 2014-02-01
2014-02-01 768
768Проверка свойств данных, выполнение которых предполагалось при оценивании уравнения регрессии
1. Гомоскедастичность и гетероскидастичность остатков.
2. Взвешенный и обобщенный методы наименьших квадратов.
=1=
Основные предпосылки регрессионного анализа:
1. Отклонения ei случайные
2. M(ei)=0
3. Дисперсия для всех отклонений постоянна
4. Ei независимы между собой
Третья предпосылка свидетельствует о том, что дисперсия каждого отклонения постоянна.
Такое свойство случайных ошибок называется гомоскедастичностью остатков. Если же это свойство остатков нарушено, то есть дисперсия их различна, то в остатках присутствует гетероскидастичность.
Гетероскидастичность приводит к тому, что оценки параметров a и b не будут обладать желаемыми свойствами, такими как: Несмещенность, состоятельность, эффективность.
Графически гетероскидастичность можно увидеть по корреляционному полю.
(1)
На этом рисунке дисперсия остатков возрастает при средних значениях х и уменьшается при крайних значениях х.
(2)
Дисперсия остатков увеличивается с ростом х.
(3) – гомоскедастичность
Гетероскидастичность возникает, как правило, при анализе неоднородных объектов.
Например, при исследовании зависимостей, прибылей предприятий от размера основного фонда.
Более крупные предприятия имеют большие колебания прибыли, чем малые предприятия.
Тоже самое происходит при изучении зависимости спроса на актив от суммы инвестиций инвестора.
Существуют различные тесты проверки наличия гетероскидастичности. Например, тест ранговой корреляции Спирмана, тест Уайта.
=2=
При обнаружении гетероскидастичности остатков классический метод наименьших квадратов для поиска параметров а и в использовать нельзя, так как будут нарушены 3 свойства оценок а и в.
Существуют способы корректировки гетедоскидастичности. Одним из способов является применение взвешенного метода наименьших квадратов (ВМНК). Для его использования строят ковариационную матрицу:
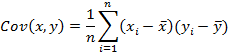
Эта матрица имеет вид:
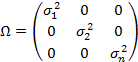
Если отсутствует гетероскидастичность, то есть наблюдается гомоскедастичность, то ковариация остатков 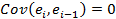
Если известны диагональные элементы 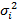 , то применяется взвешенный метод наименьших квадратов.
, то применяется взвешенный метод наименьших квадратов.
Его суть: каждое наблюдение делится на соответствующее стандартное отклонение. При этом получается новое преобразованное уравнение.
Для удобства можно провести замену переменных. Дисперсия остатков для преобразованного уравнения является постоянной.
Модель, полученная с помощью классического МНК:
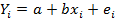
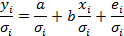
Преобразуем данные: 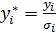
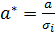
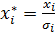
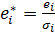
Запишем преобразованную модель: 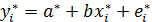
Проверим дисперсию новых преобразованных остатков:
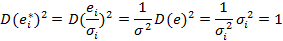
Получили постоянную дисперсию равную 1, которую имеет каждое случайное отклонение для преобразованной модели.
Если неизвестны диагональные элементы ковариационной матрицы, то используется обобщенный метод наименьших квадратов (ОМНК).
В этом случае используют какую-либо оценку неизвестных дисперсий.
Чаще всего исходят из того, что:
1. Случайная ошибка пропорциональна независимой переменной
2. Дисперсия ошибки может принимать только 2 значения(10)
Рассмотрим случай, когда величина ошибки ei пропорционально независимой переменной, то есть(11)
Исходную модель, построенную классическим МНК делят на независимую переменную. Получают новое уравнение. Удобно преобразовать данные, для преобразованной модели дисперсия остатков постоянна.
(12)
Разделим исходную модель на независимую переменную:
(13)
Преобразуем данные (14)
Преобразованная модель имеет вид: (15)
Найдем дисперсию остатков для этого преобразованного уравнения: (16)
Получили постоянную дисперсию для случайных ошибок для всех наблюдений в преобразованной модели. То есть проблема гетероскидастичности устранима.
Лекция №7
Множественный регрессионный анализ
1. Спецификация модели
2. Отбор факторов при построении множественной регрессии
3. Мультиколлинсарность факторов
4. Оценка параметров модели множественной регрессии
5. Оценка качества модели регрессии
=1=
Значения экономических показателей обычно формируются под действием набора экономических факторов.
Если есть доминирующий фактор, влияющий на показатель (цена на спрос), то зависимость является парной корреляционной зависимостью. Так при изучении потребления (у) от доходов (х) предполагается, что остальные характеристики являются одинаковыми для всех потребителей (цена, состав семьи, возраст членов семьи и др.)
Изучение влияния многих факторов на экономический показатель происходит с помощью моделей множественной регрессии.
Модель множественной регрессии позволяет оценить совокупное влияние факторов на экономический показатель, отделив при этом влияние каждого фактора в отдельности на этот экономический показатель.
При построении модели множественной регрессии решаются 2 проблемы:
1. Спецификация модели
2. Отбор факторов в модель
Прежде всего, во множественной регрессии рассматривается спецификация линейной модели.
Линейная модель (1) – модель 1
Если выполняются 4 основные предпосылки регрессионного анализа, то модель 1 называется классическая нормальная линейная модель множественной регрессии(CLNMRM).
Бета-i называются коэффициентами ‘чистой’ регрессии, он показывает, на сколько единиц в среднем изменится у при изменении xi на одну единицу, при условии, что остальные факторы останутся неизменными на среднем уровне.
Для выборочных данных bi – коэффициент чистой регрессии, имеет тот же смысл.
i=1,m
m – количество факторов в модели
n- количество наблюдений
Другие спецификации модели множественной регрессии:
1. (2) степенная модель множественной регрессии
Логарифмируя, получаем: (3)
2. Совмещенное уравнение регрессии (4)
=2=
Требования, предъявляемые к факторам, включаемым в модель:
1. Факторы должны быть количественно измеримы. Для качественных факторов (состояние объекта, этажность) можно ввести систему баллов. В модели могут использоваться фиктивные переменные. В модель могут быть включены лаговые переменные.
2. Факторы не должны быть коррелированны между собой. Коррелированные факторы действуют одновременно, в унисон на экономические показатели, тем самым деформируется экономический смысл модели.
Если 2 фактора линейно зависят между собой то они коллинеарны, если более 2,то они мультиколлинеарны.
Если факторы нелинейно зависят между собой, то они интерколлерированы.
=3=
Для определения колленеарности факторов рассчитывается коэффициент парной корреляции.
(5)
Факторы коллинеарны, если Rx1x2> 0,7
При изучении зависимости (6)
Матрица парных коэффициентов оказалась следующей(7)
Очевидно, что факторы х1 и х2 дублируют друг друга так как Rx1x2=0,8
Какой оставить в модели, а какой исключить?
Оставлять в модели следует не фактор более тесный связанный с у, а тот фактор который при достаточно тесной связи с у имеет наименьшую связь с другими факторами, так как коэффициент парной корреляции х2х3=0,2 а х1х3=0,5. Значит х1 надо исключить из модели.
=4=
Параметры линейной модели множественной регрессии оцениваются по методу наименьших квадратов.
МНК для модели множественной линейной регрессии записывается так(8)
Решая модель безусловной оптимизации получим систему нормальных уравнений (m+1) уравнения с (m+1) неизвестным.
Решая систему, найдем оценки параметров линейной модели множественной регрессии.
=5=
Каждый параметр модели множественной регрессии оценивается по t-статистике.
Надежность модели множественной регрессии в целом оценивается по F-критерию Фишера(9)
Коэффициент множественной детерминации: (10)
Характеризует качество модели регрессии, объясняет долю дисперсии зависимой переменной за счет изменения влияющих факторов.
(11)
Примеры моделей множественной регрессии:
Модель потребления Фридмата (12)
Лекция №8
Временные ряды и их характеристики
1. Общие сведения о временных рядах
2. Классификация временных рядов
3. Показатели временного ряда
4. Адоптивные модели прогнозирования
=1=
Временным рядом называется последовательность упорядоченных во времени значений, характеризующих состояние или изменение исследуемого явления.
Любой временной ряд содержит два обязательных элемента:
1. Время (момент или период)
2. Значение экономического показателя – уровень ряда.
Общий вид модели временного ряда: (1)
T – фактор времени
Y(t) – уровень ряда, значение в момент времени
u(t) – это тренд, закономерная составляющая ряда, тенденция в поведении экономического показателя. Например, курс валюты имеет тенденцию к росту, или инфляция имеет ниспадающий тренд и т.д.
v***(t) - сезонная компонента или составляющая. Отражает повторяемость процессов в течение небольших периодов времени, а именно неделя, месяца, года. Например, увеличение безработицы в южных городах в зимнее время года, снижение цены на овощную продукцию в осенний сезон и т.д.
C(t) – циклическая компонента отражает повторяющиеся процессы в течении длительного периода времени. Например, экономические циклы Кондратьева, циклы инвестиций, демографические ямы и т.д.
E(t) – случайная компонента, характеризует неучтенные факторы в других компонентах.
U,ню и с – это неслучайные компоненты.
Любая из этих компонент может быть равна нулю.
Если в модели 1 названные компоненты связаны знаком +, то модель называется аддитивной моделью временного ряда.
Если названные составляющие связаны знаком *, то модель называется мультипликативной.
На практике важнейшей задачей является изучение тенденции и отклонений от нее.
=2=
Признаки классификации временных рядов:
1. Время.
По времени временные ряды бывают моментные и интервальные.
Моментный временной ряд отражает показатель или явление на какую-либо дату или момент времени. Например, население города на начало года за последние 7 лет.
(2)
Интервальный временной ряд отражает значение показателя за какой-либо период времени. Например, объем производства молочной продукции предприятиями города за последние 7 лет.
(3)
В интервальном временном ряде итоговая сумма уровней ряда обычно имеет экономический смысл: она показывает итоговое значение показателя за все указанные периоды. Например: в таблице это производство молока за все годы с 2005 по 2011.
Так же это может быть общий объем инвестиций за годы, выпуск специалистов за годы и т.д.
2. Форма представления уровней
По форме представления бывают:
· Ряды абсолютных показателей. Например, объем производства продукции фирмой за последние 6 месяцев.
· Ряды относительных показателей. Темпы роста производства продукции за 6 месяцев.
· Ряды средних показателей. Например, среднесуточный объем производства продукции этой же фирмы за 2 месяца.
3. Расстояния между датами или интервалами времени. По этому признаку полные и неполные временные ряды.
В полном временном ряде даты располагаются последовательно одна за другой. В неполном какие-то даты могут отсутствовать.
4. Содержание показателей. По этому признаку бывают ряды: частных и агрегированных показателей.
Если объект исследуется односторонне, то достаточно знать частные показатели. Например, среднесуточный объем производства; число безработных, зарегистрированных в службе занятости и т.д.
Для комплексного исследования явления используются агрегированные показатели. Они строятся на базе частных показателей. Так показатель экономической конъюнктуры, отражающий экономическое развитие страны включает в себя ряд частных показателей, таких как: число безработных, производительность труда, техническое оснащение и т.д.
=3=
Рассмотрим пример:
| Номер периода или момент времени | Уровень ряда, тыс. т | Абсолютное изменение уровней, тыс. тонн в год | Ускорение абсолютного изменения, Тыс. тонн/год^2 | Темп роста к предыдущему периоду | Темп роста к начальному периоду |
| - | - | - | - | ||
| - | |||||
| 114,3 | |||||
| 15,6 | |||||
| 116,2 | |||||
| 116,3 | |||||
| 116,0 |
Основные показатели разберем на этом примере.
Абсолютное изменение уровней может быть цепным или базисным, представляет собой разность между текущим уровнем и уровнем более раннего периода. Если более ранний уровень относится к начальному периоду, то показатель базисный. Если более ранний уровень относится к предшествующему периоду, то показатель цепной.
(4)
Так, в примере абсолютное изменение уровней представлено в тыс. тонн в год.
Как видим, в таблице абсолютное изменение уровней возрастает со временем, т.е. уровни ряда меняются с ускорением.
Ускорение абсолютного изменения – это разница между текущим и предшествующим абсолютными изменениями уровней. Только цепной вариант.
(5)
Измеряется в тех же единицах, что и уровни с добавлением деления на квадрат длинны
периода. Если ускорение возрастает, то рост показателя увеличивается. Если ускорение отрицательное, то рост замедляется. В примере ускорение представляет собой const, это означает, что тренд u(t) будет параболическим, т.е. временной ряд имеет вид: (6).
В примере тренд будет иметь вид (7).
Предположим, конкурирующая фирма описывается трендом(8). Объемы производства руды в какой фирме выше? Для этого надо рассчитать относительный показатель.
То есть темп роста уровня, он бывает цепной и базисный.(9)
Так, в таблице темп роста к предыдущему - цепной, к начальному – базисный.
Как видим, объем производства вырос в 2,32 раза на первом предприятии. А во втором предприятии в 3,1 раза.
=4=
Адаптивные модели прогнозирования – это модели дисконтирования данных, которые способны быстро приспосабливать свою структуру и параметры к изменению условий.
Модель Брауна, модель Хольта.








