 2014-02-01
2014-02-01 853
853(отбор наиболее существенных объясняющих переменных).
В самом начале нашего курса мы разбирали вопрос, откуда возникает ошибка e в i -м наблюдении. Мы тогда говорим про невключение в уравнение переменных в силу различных обстоятельств – про возможность перехода от исходного числа p анализируемых объясняющих переменных к существенно меньшему числу объясняющих переменных, наиболее6 информативных в некотором смысле. Некоторые объясняющие переменные оказывают несущественное влияние на объясняющую переменную и им можно пренебречь. Если же у нас есть сильно зависимые признаки, то информация, поставляемая ими, дублирует друг друга, так, что дополнительным влиянием одной из переменных можно пренебречь. Поэтому стремление исследователя отобрать из имеющегося у него набора объясняющих переменных лишь самые существенные (с точки зрения влияния на Y), представляется вполне естественным. В предположении, что объясняющие переменные неслучайны, возможны две точки зрения на оценку уравнения регрессии, получаемого после отбора наиболее существенных предсказывающих переменных:
1. Модель регрессии является истинной, тогда при помощи метода наименьших квадратов получается несмещенная и эффективная оценка коэффициентов регрессии (в условиях мультиколлинеарности эта оценка может быть неудовлетворительной, но, тем не менее, останется несмещенной). Тогда принудительное приравнивание части коэффициентов к нулю, что и происходит при отборе регрессоров, приводит, как мы убедились, к смещенным оценкам коэффициентов при оставшихся переменных, т. е. мы переходим к классу смещенных оценок, о чем говорилось выше.
2. Процесс отбора существенных переменных можно рассматривать как процесс выбора истинной модели из множества возможных линейных моделей, которые могут быть построены с помощью набора объясняющих переменных, и тогда полученные после отбора оценки коэффициентов можно рассматривать как несмещенные. этой точки зрения мы и будем придерживаться в дальнейшем.
3. Для случая, когда объясняющие переменные – случайные величины, вопрос о правильности (истинности) модели не стоит. Все, что мы ищем в этом случае – модель, сохраняющую ошибку предсказания на разумном уровне при ограниченном количестве переменных.
Существует несколько подходов к решению задачи отбора наиболее существенных объясняющих переменных. Мы остановимся на двух процедурах, реализующих идею «от простого к сложному» – последовательного наращивания числа объясняющих переменных.
Пусть у нас всего р переменных, претендующих на участие в правой части.
1. «Все возможные регрессии».
1) Проведем р парных регрессий Y на X 1,… Xp и выберем ту переменную, для которой коэффициент детерминации наибольший - 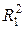 . на этом шаге мы найдем одну объясняющую переменную, которую можно назвать наиболее информативной объясняющей переменной при условии, что в регрессионную модель мы можем включить только одну из имеющегося набора объясняющих переменных.
. на этом шаге мы найдем одну объясняющую переменную, которую можно назвать наиболее информативной объясняющей переменной при условии, что в регрессионную модель мы можем включить только одну из имеющегося набора объясняющих переменных.
2) проведем р *(р -1) регрессий, каждый раз включая две из р переменных и выберем ту, которая дает наибольшее значение 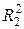 – пара (X (1), X (2)) – наиболее информативная пара переменных: эта пара будет иметь наиболее тесную статистическую связь с результирующим показателем Y. В состав этой пары переменная из первого шага может и не войти.
– пара (X (1), X (2)) – наиболее информативная пара переменных: эта пара будет иметь наиболее тесную статистическую связь с результирующим показателем Y. В состав этой пары переменная из первого шага может и не войти.
3) находим три наиболее информативных объясняющих переменных, проведя р *(р -1)*(р -2) - 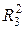
…
Вопрос – когда остановиться. Строгих правил нет, только рекомендации. Изобразим на графике зависимость скорректированного коэффициента детерминации наиболее информативной совокупности переменных от числа этих переменных. Одновременно будем откладывать следующую величину:
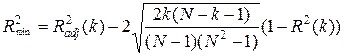 .
.
Получим следующую картинку:








