2020-01-15
2020-01-15 140
140Аннотация
Целью данной работы являлась разработка алгоритма преобразования последовательной программы на языке Fortran в параллельную программу на языке Fortran-DVM/OpenMP. Это преобразование осуществляет блок ("DVM/OpenMP-эксперт") экспериментальной системы автоматизации распараллеливания, используя результаты анализа информационной структуры последовательной программы.
К моменту начала работы над поставленной задачей система автоматизации распараллеливания содержала блок, именуемый "DVM-экспертом", который автоматизирует распараллеливание Fortran-программы на кластер. В рамках дипломной работы DVM-эксперт был доработан до DVM/OpenMP-эксперта, автоматизирующего распараллеливание Fortran-программ на SMP-кластер.
Разработанные алгоритмы были реализованы, включены в состав экспериментальной системы и проверены при распараллеливании тестовых примеров.
Введение
Развитие вычислительной техники. SMP-кластеры
Вычислительная техника в своем развитии по пути повышения быстродействия ЭВМ приблизилась к физическим пределам. Время переключения электронных схем достигло долей наносекунды, а скорость распространения сигналов в линиях, связывающих элементы и узлы машины, ограничена значением 30 см/нс (скоростью света). Поэтому дальнейшее уменьшение времени переключения электронных схем не позволит существенно повысить производительность ЭВМ. В этих условиях требования практики (сложные физико-технические расчеты, многомерные экономико-математические модели и другие задачи) по дальнейшему повышению быстродействия ЭВМ могут быть удовлетворены только путем распространения принципа параллелизма на сами устройства обработки информации и создания многомашинных и многопроцессорных (мультипроцессорных) вычислительных систем. Такие системы позволяют распараллелить выполнение программы или одновременно выполнять несколько программ.
Последние годы во всем мире происходит бурное внедрение вычислительных кластеров. Вычислительный кластер – это мультикомпьютер, состоящий из множества отдельных компьютеров (узлов), связанных между собой единой коммуникационной системой. Каждый узел имеет свою локальную оперативную память. При этом общей физической оперативной памяти для узлов не существует. Если в качестве узлов используются мультипроцессоры (мультипроцессорные компьютеры с общей памятью), то такой кластер называется SMP-кластером.
Привлекательной чертой кластерных технологий является то, что они позволяют для достижения необходимой производительности объединять в единые вычислительные системы компьютеры самого разного типа, начиная от персональных компьютеров и заканчивая мощными суперкомпьютерами. Таким образом, кластеры являются легко-масштабируемыми. Широкое распространение кластерные технологии получили как средство создания систем суперкомпьютерного класса из составных частей массового производства, что значительно удешевляет стоимость вычислительной системы.
В то же самое время, для повышения производительности кластера, в качестве узлов нередко используются мультипроцессоры. Таким образом, теперь программист имеет дело с двумя уровнями параллелизма – параллельное выполнение задач на узлах кластера, и параллельное выполнение подзадач на ядрах мультипроцессора.
Параллельное программирование
В настоящее время практически все параллельные программы для кластеров разрабатываются с использованием низкоуровневых средств передачи сообщений (MPI). Однако MPI-программы имеют ряд существенных недостатков:
· низкий уровень программирования и как следствие, высокая трудоемкость разработки программ;
· сложность выражения многоуровневого параллелизма программы;
· MPI-программы, как правило, неспособны эффективно выполняться на кластерах, у которых процессоры имеют разную производительность.
В то же время, на текущий момент так и нет и общепризнанного высокоуровневого языка параллельного программирования, позволяющего эффективно использовать возможности современных ЭВМ.
Таким образом, разработка программ для высокопроизводительных кластеров, и в особенности SMP-кластеров, продолжает оставаться исключительно сложным делом, доступным узкому кругу специалистов и крайне трудоемким даже для них.
Попытки разработать автоматически распараллеливающие компиляторы для параллельных ЭВМ с распределенной памятью, проведенные в 90-х годах (например, Paradigm, APC), привели к пониманию того, что полностью автоматическое распараллеливание для таких ЭВМ реальных производственных программ возможно только в очень редких случаях. В результате, исследования в области автоматического распараллеливания для параллельных ЭВМ с распределенной памятью практически были прекращены.
Исследователи сосредоточились на двух направлениях:
o разработка высокоуровневых языков параллельного программирования (HPF, OpenMP-языки, DVM-языки, CoArray Fortran, UPC, Titanium, Chapel, X10, Fortress);
o создание систем автоматизированного распараллеливания (CAPTools/Parawise, FORGE Magic/DM, BERT77), в которых программист активно вовлечен в процесс распараллеливания. [3]
Остановим свое внимание на высокоуровневом языке параллельного программирования DVM/OpenMP.
Модель параллелизма DVM/OpenMP
В последнее время для вычислительных систем, сочетающих в себе одновременно характеристики архитектур, как с общей, так и с распределенной памятью, используется так называемая "гибридная" модель. При этом программа представляет собой систему взаимодействующих процессов, а каждый процесс программируется на OpenMP. Рассмотрим вычислительную сеть, каждый узел которой является мультипроцессором или отдельным процессором:
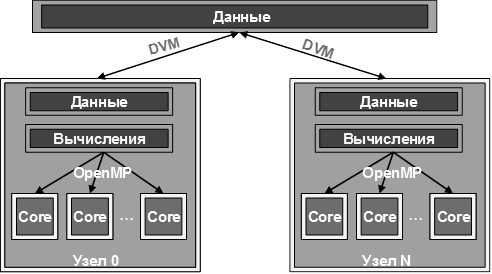
На первом этапе определяются массивы, которые могут быть распределены между узлами (распределенные данные). Эти массивы специфицируются DVM-директивами отображения данных. Остальные переменные (распределяемые по умолчанию) отображаются по одному экземпляру на каждый узел (размноженные данные). Распределение данных определяет множество локальных или собственных переменных для каждого узла. Распределив по узлам данные, пользователь должен обеспечить и распределение вычислений по узлам. При этом должно выполняться правило собственных вычислений: на каждом узле выполняются только те операторы присваивания, которые изменяют значения переменных, размещенных на данном узле. В свою очередь, на узле эти вычисления могут быть распределены между нитями средствами OpenMP.
Основным методом распределения вычислений по узлам является явное задание пользователем распределения между узлами витков цикла. При этом каждый виток такого цикла полностью выполняется на одном узле. Выполнение по правилу собственных вычислений операторов вне распределенного параллельного цикла обеспечивается автоматически компилятором, однако это требует существенных накладных расходов.
На следующем этапе необходимо организовать доступ к удаленным данным, которые могут потребоваться при вычислении значений собственных переменных. [4]