2020-01-15
2020-01-15 135
135
Идеология оболочки состоит в том, что пользователь будущей базы данных сначала описывает на специальном языке структуры данных, из которых должны состоять таблицы в базе (то есть фактически интерфейсы) их ссылочные связи, индексы и т.п. Затем при помощи специального транслятора он получает готовый С++ код, реализующий интерфейс работы с базой данных, определенный пользователем, включая саму базу, ее таблицы, записи данных, транзакции и некоторые другие объекты. Код, генерируемый транслятором, на самом деле, является тоже оболочкой. Дело в том, что многие части транслятора имеют под собой общее основание. Эти статические классы и функции можно выделить в библиотеку. Еще одна причина для этого – семантика самого транслятора должна быть как можно проще. И как следствие этого, сокращаются размеры генерируемых файлов.
Полученный программный код остается только включить в проект и использовать уже готовые объекты базы данных и таблиц.
Новая база данных должна располагать такими возможностями:
· Добавление пользовательских данных их модификация и удаление.
· Открытие базы в нескольких режимах: например, в нормальном многопользовательском транзакционном режиме, безопасном режиме (как правило, для монопольного доступа и используется утилитами), а также в режиме восстановления базы данных.
· Импорта данных, то есть, представления данных в некотором текстовом формате, и их перемещение в пустую базу данных
· Экспорта данных, то есть, перемещение данных из базы, и представление их в определенном текстовом формате в файле, удобном для чтения. Является взаимно обратной операцией предыдущей.
· Проверки индексной целостности. Дело в том, что иногда, вследствие различных внешних факторов (например, перепад напряжения), теряется актуальность и корректность данных в индексных таблицах, и их необходимо периодически проверять и в случае необходимости восстанавливать.
· Проверки ссылочной целостности. То есть проверка корректности логических зависимостей между таблицами в базе.
Итак, вся оболочка состоит из следующих частей:
1. Собственно, базовая библиотека статических классов, для высокоуровневой работы с Berkeley, необходимая транслятору.
2. Транслятор, который, также является генерируемой оболочкой под типы данных пользователя вокруг библиотеки.
Библиотека классов
«Движок» представляет собой библиотеку классов, которые с одной стороны являются надстройками вокруг стандартных соответствующих структур, а с другой стороны делают их интерфейс более удобным и инкапсулируют часть работы транслятора. Основными компонентами являются:
· Транзакции
· Исключения
· Базовые записи
· Таблицы
· Базы данных
· Курсоры
Базовые записи
Базовая запись – это элементарная единица хранения в таблице. Описание ее класса:
//! базовый класс для записей с vtable pointer
class hbObj{
Dbt dbt;
protected:
void dbtInit(uint s,void* d)
{
dbt.set_flags(DB_DBT_USERMEM);
dbt.set_ulen(s);
dbt.set_size(s);
dbt.set_data(d);
}
public:
operator Dbt*(){return &dbt;}
void* getData(void) {return dbt.get_data();};
uint getSize(void) {return dbt.get_size();};
hbObj() {}
virtual ~hbObj() {}
};
Этот класс не совсем удобен для непосредственного использования. Дело в том, что он ничего не знает об исходных данных, которые будет в себе содержать. Этими данными могут быть, например, размер структуры в памяти и некоторые ее методы. Простейшим решением будет введение шаблона с передачей типа хранимой структуры как его параметра.
//! реальный класс, который приводится к Dbt
template <class A> class hbRec:public hbObj
{
A data;
public:
A* getPnt(void) { return &data;} // если в в A массив то можно переопределить операцию & для А
hbRec() { memset(&data,0,sizeof(A));dbtInit(sizeof(A),&data);}
hbRec(const hbRec<A>& a):data(a.data) { dbtInit(sizeof(A),&data);}
hbRec(const A& a) :data(a) { dbtInit(sizeof(A),&data);}
void SetData(const A& a) { data = a;dbtInit(sizeof(A),&data);}
virtual ~hbRec() {}
};
Таблицы
Диаграмма отношений существующих таблиц приведена ниже:
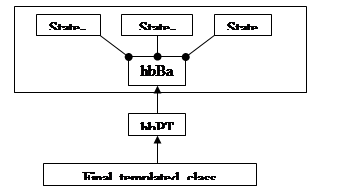
По аналогии с записями существует базовый класс таблиц hbBasetbl, который поддерживает работу со всеми стандартными типами таблиц (Hash, Btree, Queue). Фактически ее тип является ее состоянием и определяется в момент открытия.
class hbBasetbl
{
// нужен для того чтобы set_flags вызывалась ровно один раз
uint Set_flg_Counter;
ushort state;
// флаг, показывающ. открыта ли сама таблица, необходим для экстр. закрытия в случае некоректного
// открытия
bool tableopen;
hbInit ini;
protected:
uint recsize;
uint keysize; //только для DB_HASH
Db *table;
virtual void UsrOpen(hbTxn *tx,FileConf& conf,bool openidx,hbInitRt* irt = 0,u_int32_t op_flags = 0);
virtual void UsrClose();
void SetRecSize(uint recsize1){recsize = recsize1;}
void SetKeySize(uint keysize1){keysize = keysize1;}
uint GetType() {return ini.type;}
bool IsDup() {return (ini.st_flags & DB_DUP | ini.st_flags & DB_DUPSORT)>0;}
public:
hbEnv& env;
operator Db*(){return table;}
Db* operator ->(){return table;}
const char* GetDbName(){return ini.dbname;}
hbBasetbl(hbEnv& e,hbInit&);
virtual ~hbBasetbl(){ if(state) Close();}
void Open(hbTxn *tx,FileConf& conf,bool openidx,hbInitRt* irt = 0,u_int32_t op_flags = 0);
void Close();
virtual void Create(hbTxn *tx,FileConf& conf,hbInitRt* irt = 0,u_int32_t op_flags = 0);
virtual int Get(hbTxn *tx,hbObj *key,hbObj *val,u_int32_t flags=0); // в стиле С (без исключений)
virtual int Pget(hbTxn *tx,hbObj *fkey,hbObj *pkey, // в стиле С (без исключений)
hbObj *val, u_int32_t flags=0);
virtual int Del(hbTxn *tx,hbObj *key,u_int32_t flags=0); // в стиле С (без исключений)
virtual int tGet(hbTxn *tx,hbObj *key,hbObj *val,u_int32_t flags=0); // в стиле С++
virtual int tPget(hbTxn *tx,hbObj *fkey,hbObj *pkey, hbObj *val, u_int32_t flags=0); // в стиле С++
virtual int tDel(hbTxn *tx,hbObj *key,u_int32_t flags=0); // в стиле С++
virtual int Put(hbTxn *tx,hbObj *key,hbObj *val,u_int32_t flags=0);
bool IsOpen(){return state;}
};
Для ускорения доступа по какому-то критерию к данным в таблицах вводятся индексные таблицы. Ими могут быть любые из перечисленных, конечно в соответствии с их особенностями. Класс hbBasetbl является с одной стороны базовым классом, содержащим всю рутинную работу с флагами и основными операциями с таблицей, а с другой стороны -финальным классом для индексной таблицы.
Этот класс является базовым, и совсем неудобен для работы, если эта таблица является индексированной (то есть имеет индексы – другие индексные таблицы). Необходим еще один класс, который будет обобщением понятия индексируемой таблицы и являться контейнером для таких индексных таблиц. Этот класс представлен ниже.
class hbPTable:public hbBasetbl{
void ErrorClose();
void eee();
void FixIdx(uint bulk_ret_buffer_size,int i,FileConf& conf);
void FixIdxForQueue(uint bulk_ret_buffer_size,int i,FileConf& conf);
void FixIdxForHash(uint bulk_ret_buffer_size,int i,FileConf& conf);
void CheckMainToIdx(uint bulk_ret_buffer_size,bool fix,FileConf& conf);
void CheckMainToIdxForQueue(uint bulk_ret_buffer_size,bool fix,FileConf& conf);
void CheckMainToIdxForHash(uint bulk_ret_buffer_size,bool fix,FileConf& conf);
void CheckIdxToMain(uint bulk_ret_buffer_size,bool fix,FileConf& conf);
void CheckIdxToMainForQueue(uint bulk_ret_buffer_size,bool fix,FileConf& conf);
void CheckIdxToMainForHash(uint bulk_ret_buffer_size,bool fix,FileConf& conf);
inline void ExportForQueue(uint bulk_ret_buffer_size,FILE* f, hbTxn* tx);
inline void ExportForHash(uint bulk_ret_buffer_size,FILE* f, hbTxn* tx);
inline void Import3(Dbt* key,Dbt* data);
inline void Import2(char* buf);
inline void Import1(FILE* f,char*& buf1,uint&);
inline void CheckForRefForQueue(uint bulk_ret_buffer_size);
inline void CheckForRefForHash(uint bulk_ret_buffer_size);
inline uint GetMaxRefRecBuf();
protected:
int sz;
IdxItem *idx;
RefItems ref;
virtual void UsrOpen(hbTxn *tx,FileConf& conf,bool openidx,hbInitRt* irt = 0,u_int32_t flags = 0);
virtual void UsrClose();
inline virtual void ExportDBTemplate(FILE*,const char*,const char*) = 0;
inline virtual void ImportDBTemplate( char* buf1,
uint buf1len,
char* buf2,
uint buf2len,
hbObj*& Key,
hbObj*& Val) = 0;
public:
//! конструктор принимает массив инициализаторов (в тч индексов)
hbPTable(hbEnv& env,hbInit& ini1);
virtual ~hbPTable();
// проверка индексной целостности
void CheckIdx(uint bulk_ret_buffer_size,bool fix);
// проверка ссылочной целостности
void CheckForRef(uint bulk_ret_buffer_size);
void Export(uint bulk_ret_buffer_size,FILE* f, hbTxn* tx);
void Import(FILE* f,char*& buf,uint&);
virtual int Pget(hbTxn *tx,int n,hbObj *fkey, hbObj* pkey, hbObj *val, u_int32_t flags=0)
{return idx[n].table.Pget(tx,fkey,pkey,val,flags);}
hbBasetbl& GetIdx(int n)
{return idx[n].table;}
inline uint GetIdxCount() {return sz;}
inline uint GetRecSize() {return recsize;}
};
Как видим, этот класс расширяет старый интерфейс путем введения утилитарных методов экспорта, импорта, различного рода проверок и операциями с индексными таблицами. Однако этот класс также не удобен в работе, так как не знает ничего о типах структур и ее характеристиках. Введение этих типов как параметров шаблона позволило бы очень упростить работу с интерфейсом индексируемой таблицы (но не расширить!). Результат приведен ниже:
template<class Key,class Val> class hbTable:public hbPTable
{
public:
//! конструктор принимает массив инициализаторов (в тч индексов)
hbTable(hbEnv& e,hbInit& ini1):hbPTable(e,ini1) {SetRecSize(sizeof(Val));SetKeySize(sizeof(Key));}
//SetRecSize use by QUEUE only
virtual ~hbTable() {}
// более продвинутые функции
int Get(const bexcp& excp, hbTxn *tx,const Key &key,Val *val, u_int32_t flags=0)
{
Get(excp,tx,(Key*)&key,val,flags);
}
int Pget(const bexcp& excp, hbTxn *tx,int n,hbObj *fkey,Key *pkey, Val *val,u_int32_t flags=0)
{
MTRY
hbRec<Key> k;
hbRec<Val> v;
int z=Pget(tx,n,fkey,&k,&v,flags);
*pkey= *(k.getPnt());
*val= *(v.getPnt());
return z;
CATCH_hbExcp
}
int Del(const bexcp& excp, hbTxn *tx, const Key &key,u_int32_t flags=0)
{
Del(excp,tx,(Key*)&key,flags);
}
int tGet(const bexcp& excp, hbTxn *tx, Key *key,Val *val, u_int32_t flags=0)
{
MTRY
hbRec<Key> k(*key);
hbRec<Val> v;
int z = tGet(tx,&k,&v,flags);
*val= *(v.getPnt());
return z;
CATCH_hbExcp
}
int Put(const bexcp& excp, hbTxn *tx,const Key &key, const Val &val, u_int32_t flags=0)
{
Put(excp,tx,(Key*)&key,(Val*)&val,flags);
}
uint Append(const bexcp& excp, hbTxn *tx, Val *val)
{
MTRY
if(GetType()!= DB_QUEUE) return 0;
hbRec<uint> k;
hbRec<Val> v(*val);
hbBasetbl::Put(tx,&k,&v,DB_APPEND);
return (uint&)*(k.getPnt());
CATCH_hbExcp
}
uint Append(const bexcp& excp, hbTxn *tx,const Val &val)
{
return Append(excp,tx,(Val*)&val);
}
};
Этот параметризированный класс на самом деле только переопределил сигнатуры методов более удобными и работающими с пользовательскими типами данных.