 2020-01-14
2020-01-14 142
142case 1: end=middle-l
End select
End while
Return 0

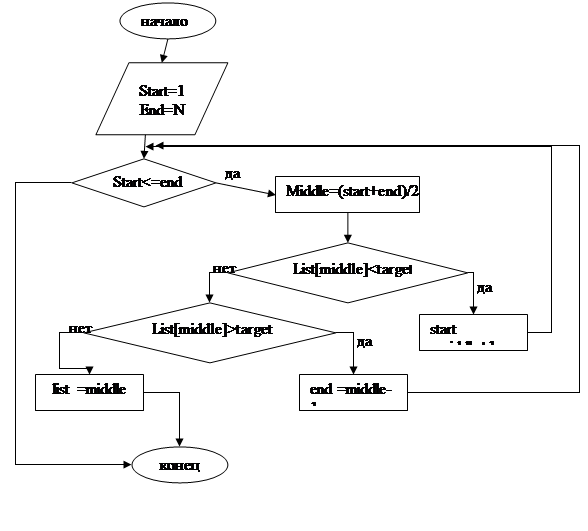
В этом алгоритме переменной start присваивается значение, на 1 большее, чем значение переменной middle, если целевое значение превышает значение найденного среднего элемента. Если целевое значение меньше значения найденного среднего элемента, то переменной end присваивается значение, на 1 меньше, чем значение переменной middle. Сдвиг на 1 объясняется тем, что в результате сравнения мы знаем, что среднее значение не является искомым, и поэтому его можно исключить из рассмотрения.
Всегда ли цикл останавливается? Если целое значение найдено, то ответ, разумеется, утвердительный, поскольку выполняется оператор return. Если нужное значение не найдено, то на каждой итерации цикла либо возрастает значение переменной start, либо уменьшается значение переменой end. Это означает, что их значения постепенно сближаются. В какой-то момент эти два значения становятся равными, и цикл выполняется еще один раз при соблюдении равенства start=end=middle. После этого прохода (если элемент с этим индексом не является искомым) либо переменная start окажется на 1 больше, чем end и middle, либо наоборот, переменная end окажется на 1 меньше, чем start и middle. В обоих случаях условие цикла while ложным, и цикл больше выполнятся не будет. Поэтому выполнение цикла завершается всегда.
Возвращает ли этот алгоритм правильный результат? Если целевое значение найдено, то ответ безусловно утвердительный, поскольку выполнен оператор return. Если же средний элемент оставшейся части списка не подходит, то на каждом подходе цикла происходит исключение половины оставшихся элементов, поскольку все они либо чересчур велики, чересчур малы. Ранее мы говорили, что в результате мы придем к единственному элементу, который следует проверить. Если это нужный нам ключ то будет возвращено значение переменной middle. Если же значение ключа отлично от искомого, то значение переменной start превысит значение end или наоборот, значение переменной end станет меньше значения start. Если бы целевое значение содержалось в списке, то оно было бы меньше или больше значения элемента middle. Однако значения переменных start и end показывают, что предыдущие сравнения исключили все остальные возможности, и поэтому целевое значение отсутствует в списке. Значит цикл завершит работу, а возращенное значение будет равно нулю, что указывает на неудачу поиска. Таким образом, алгоритм возвращает верный ответ.
Поскольку алгоритм всякий раз делит список пополам, мы будем предполагать при анализе, что N=2k-1 для некоторого k. Если это так, то сколько элементов останется при втором проходе? А третьем? Вообще говоря, ясно, что если на некотором подходе цикл имеет дело со списком из 2j-1 элементов, то в первой половине списка 2j-1-1 элементов, один элемент в середине, и 2j-1-1 элементов во второй половине списка. Поэтому к следующему проходу остаётся 2j-1-1 элемент (при 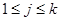 ). Это предложение позволяет упростить последующий анализ, но необходимости в нем нет.
). Это предложение позволяет упростить последующий анализ, но необходимости в нем нет.
Анализ наихудшего случая.
В предыдущем абзаце мы показали, что степень двойки в длине оставшейся части списка при всяком проходе цикла уменьшится на 1, а также, что последняя итерация цикла производится, кода размер оставшейся части становится равным 1, а это происходит при j=1 (так как 21-1=1). Это означает, что при N=2k-1 число проходов не превышает k. Решая последние уравнение относительно k, мы заключаем, что в наихудшем случае число проходов равно k=log2(N+1).
В анализе может помочь и дерево для процесса поиска. В узлах дерева решение стоят элементы, которые проверяются на соответствующем проходе. Элементы, проверка которых будет осуществляться в том случае, если целевое значение меньше текущего элемента, а сравниваемые в случае, если целевое значение больше текущего – в правом поддереве. Дерево решение для списка из 7 элементов изображено на рисунке1. В общем случае дерево относительно сбалансировано, поскольку мы всегда выбираем середину различных частей списка. Поэтому для подсчета числа сравнений мы можем воспользоваться формулами для бинарных деревьев.
|
|
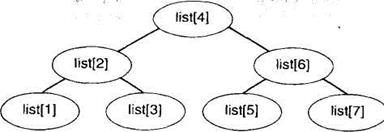
Поскольку мы предполагаем, что N=2k-1, соответствующие дерево решение будет всегда полным. В нем будет k уровней, где k=log2(N+1). Мы делаем по одному сравнению на каждом уровне, поэтому полное число сравнений не превосходит log2(N+1).
Рис. 1. Дерево решений для поиска в списке из семи элементов
Анализ среднего случая (изучить самостоятельно)
2.3. Выборка
Иногда нам нужен элемент из списка, обладающий некоторыми специальными свойствами, а не имеющий некоторое конкретное значение. Другими словами, вместо записи с некоторым конкретным значением поля нас интересует, скажем, запись с наибольшим, наименьшим или средним значением этого поля. В более общем случае нас может интересовать запись с К-ыы по величине значением поля.
Один из способов найти такую запись состоит в том, чтобы отсортировать список в порядке убывания; тогда запись с К-ыш по величине значением окажется на К-оы месте. На это уйдет гораздо больше сил, чем необходимо: значения, меньшие искомого, нас, на самом деле, не интересуют. Может пригодиться следующий подход: мы находим наибольшее значение в списке и помещаем его в конец списка. Затем мы можем найти наибольшее значение в оставшейся части списка, исключая уже найденное. В результате мы получаем второе по величине значение списка, которое можно поместить на второе с конца место в списке. Повторив эту процедуру К раз, мы найдем К-ое по величине значение. В результате мы приходим к алгоритму








