 2020-06-10
2020-06-10 178
178Существующую науку о БД многокомпонентный подход почти не затрагивает, допуская проектировать таблицы (отношения) в соответствии с любой существующей (реляционной, объектно-ориентированной или объектно-реляционной) моделью. Другим словами, таблица может рассматриваться как в реляционном виде (т.е. находиться, по крайней мере, в первой нормальной форме), так и в объектно-ориентированном виде (т.е. иметь в качестве доменов списковые данные, сложные типы, подтипы и т.д.).
Отличия МКБД проявляются не на уровне столбцов таблицы (атрибутов отношений), а на более высоком уровне, который в стандартных БД отсутствует. Самые простые СУБД представляют БД в виде неструктурированного множества таблиц, более сложные вводят понятие группы таблиц (каталога, схемы и т.п.), которое позволяет строить из таблиц более сложную логическую структуру. При рассмотрении МКБД группа таблиц также активно применяется. Ниже группа таблиц называется документом ввиду особенностей своего представления пользователю и в силу необходимости отличать её от каталога или схемы. Однако, кроме этого относительно стандартного понятия, МКБД использует понятие компонента базы данных (КБД) – некоторого промежуточного объекта между группой таблиц и всей базой данных.
В однокомпонентной БД:  ,
,  ,
,  Æ,
Æ,
в структурированной однокомпонентной БД: 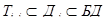 ,
, 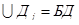 ,
,  Æ,
Æ,  ,
,  Æ ],
Æ ],
в многокомпонентной БД  ,
,  ,
,  Æ,
Æ,  ,
,  Æ,
Æ,  ,
,  Æ ] },
Æ ] },
где:
Т – схема таблицы (отношения);
Д – схема документа (группы таблиц);
КБД – схема компонента БД;
БД – схема БД.
Отсюда видно, что даже с точки зрения схем компонент базы данных (КБД) не есть просто ещё один уровень иерархического упорядочения таблиц, аналогичный документу (группе таблиц). Схемы КБД являются нестрогими подмножествами схемы БД, имея друг с другом непустое пересечение, – в отличие от схем документов, которые представляют собой разбиение схемы КБД (то есть не пересекаются). Другими словами, КБД могут иметь все таблицы схемы БД, являясь не её частями, а версиями (вариантами).
Однако основное отличие компонентов от документов проявляется не в схемах, в самих данных. В то время как данные документов разных версий однокомпонентной БД независимы, данные компонентов – версий многокомпонентной БД – являются зависимыми; они организованы в некоторую иерархию, принципиально отличную от рассмотренной выше иерархии схем.
Два компонента в этой иерархии (наследования) могут находиться в отношении наполнения (в отношении доработки, в отношении «структура/реализация»). Компонент, находящийся выше некоторого КБД в иерархии, называется суперкомпонентом (родительским компонентом, предком), а находящийся ниже – подкомпонентом (дочерним компонентом, потомком). Часть данных суперкомпонента используется в его подкомпонентах, и часть этих данных там изменяется (удаляется); кроме того, в них появляются новые данные.
Дерево иерархии компонентов обычно строится таким образом, что самые точные, редко изменяемые данные помещаются ближе к корню дерева, а самые ненадёжные, часто изменяемые – на его листьях. Это позволяет в большинстве случаев перед созданием новой версии копировать лишь один лист дерева, а не целую ветвь (и тем более не всё дерево). В БД могут существовать абсолютно надёжные данные, имеющие к тому же весьма общий характер, так что на них могут опираться все остальные данные. Такие данные относятся к корневому компоненту (ККБД), который является суперкомпонентом для всех существующих в БД компонентов. Если ККБД является единственным компонентом МКБД, то она неотличима от однокомпонентной БД.
Абстракция данных
Ещё одна идея МКБД заключается в том, что не все компоненты могут иметь полный набор данных, необходимый для их использования в приложениях. Связанные между собой данные (например, качественные и количественные данные, характеризующие один и тот же объект) могут храниться в разных таблицах, относящихся, как правило, к разным документам. Это позволяет одни данные (качественные) относить к суперкомпоненту, а разные варианты других данных (количественных) – к его подкомпонентам-версиям. В этом случае суперкомпонент является неполным (абстрактным), он не может быть использован как таковой, но может служить общей основой (заготовкой) для своих подкомпонентов, избавляя пользователя от многократного повторения одной и той же работы (в рассмотренном примере – от работы по изменению качественных данных).
Возможность работы с абстрактными данными проявляется в том, что таблицы МКБД делятся на первичные и вторичные. Первичная таблица, хранящая обычно общую структуру каких-либо реальных объектов, может содержать ссылки на другие таблицы (внешние ключи) лишь среди своих неключевых атрибутов. Ключ вторичной таблицы совпадает с ключом соответствующей ей первичной, то есть одновременно является внешним ключом. Как следствие, во вторичной таблице (в нескольких вторичных таблицах) могут храниться только данные, конкретизирующие описание объектов первичной таблицы.
Данное рассуждение проведено для какого-либо конкретного КБД, однако различение первичных и вторичных таблиц имеет смысл, только если в БД имеется, по крайней мере, два КБД: абстрактный суперкомпонент, который хранит прежде всего данные в первичной таблице (а вторичной таблицы может не иметь вообще), и подкомпонент, который хранит недостающие данные во вторичной таблице. Иерархия компонентов считается полной (неабстрактной), если она в сумме имеет равное число объектов (строк) в первичной таблице и в любой соответствующей ей вторичной таблице.








