 2020-10-10
2020-10-10 164
164
Для кодирования символьной и текстовой информации последовательно используется несколько систем кодировок. При вводе информации с клавиатуры нажатие определенной клавиши вырабатывает так называемый scan-код, представляющий собой двоичное число, равное порядковому номеру клавиши.
Номер нажатой клавиши никак не связан с формой символа, нанесенного на клавише. Опознание символа и присвоение ему внутреннего кода производится специальной программой по специальным таблицам: ДКОИ, КОИ-7, ASCII (Американский стандартный код для обмена информацией), Unicode.
С помощью 8-разрядной таблицы кодирования ASCII (рис. 7) можно закодировать всего 256 различных символов (слайды 14-15). Эта таблица разделена на две части: основную (с кодами от 00 до 7F) и дополнительную (от 80 до FF)(кодировка в шестнадцатеричной системе счисления).
Первая (базовая) половина таблицы стандартизована. Она содержит управляющие коды (от 00 до 20 и 7F), не имеющие текстовых эквивалентов и используемые для управления устройствами ввода-вывода и передачей данных. Далее размещаются знаки пунктуации, цифры и математические знаки, большие и малые латинские буквы.
Вторая половина таблицы содержит национальные шрифты, символы псевдографики, из которых могут быть построены таблицы, специальные математические знаки. Эту часть таблицы кодировок можно заменять, используя соответствующие драйверы – управляющие вспомогательные программы. Этот прием позволяет применять несколько шрифтов и их гарнитур.
При использовании таблицы ASCII каждый символ в памяти компьютера занимает 1 байт с кодом этого символа.
Дисплей по этому коду должен вывести на экран изображение символа – не просто цифровой код, а соответствующую ему картинку, так как каждый символ имеет свою форму. Описание формы каждого символа хранится в специальной памяти дисплея – знакогенераторе.
Высвечивание символа на экране дисплея IBM PC осуществлялось с помощью точек, образующих символьную матрицу. Каждый пиксель в такой матрице является элементом изображения и может быть ярким или темным. Темная точка кодируется цифрой " 0 ", светлая (яркая) – цифрой " 1 ". Если изображать в матричном поле знака темные пиксели точкой, а светлые – звездочкой, то можно графически изобразить форму символа.
Программы, работающие в операционной среде Windows, применяют совершенно другую кодовую таблицу, поддерживающую векторные шрифты TrueType. В ней отсутствуют все символы псевдографики, так как используется настоящая графика.
В этой среде используется 16-разрядный код Unicode – стандарт кодирования символов (предложенный в 1991 году), позволяющий представить знаки почти всех письменных языков (слайд 16). В документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным использование и переключение кодовых страниц.
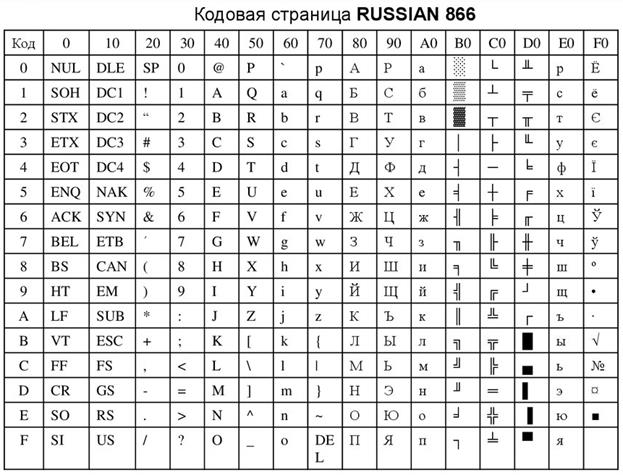
Рис. 7. Таблица ASCII-кодов для кодовой страницы RUSSIAN 866
Для обозначения символов Unicode принято используется запись вида U+ xxxx, где xxxx — шестнадцатеричные цифры. Например, символ “ я ” (U+044F) имеет код 044F16 = 110310.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF и от U+A640 до U+A69F.
При использовании таблицы Unicode каждый символ в памяти компьютера занимает 2 байта с кодом этого символа.








