2020-10-10
2020-10-10 225
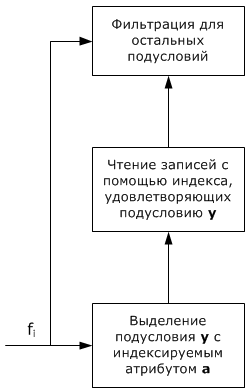
225IndexScan + Filter
Формула стоимости:
Cost Σ= CCPU + CIO
CCPU = T (R) I (R, a)⋅ Cfilter
CIO - как и в предыдущем методе, умножаем время чтения/записи на число записей в блоке индекса. Но тут два варианта:
- для кластеризованного: CIO = B (Index (R, a)) I (R, a)⋅ CB + B (R)⋅ kI (R, a)⋅ CB. В кластеризованном индексе последовательность значений в индексе и в таблице совпадает;
- для индекса без кластеризации CIO = B (Index (R, a)) I (R, a)⋅ CB + T (R)⋅ kI (R, a)⋅ CB. Последовательность в индексе и таблице не совпадает. Число в этом случае читаемых записей равно числу блоков. Или наоборот.
здесь:
T (R) - общее количество записей в таблице R;
B (R) - число физических блоков в таблице R;
I (R, a) - мощность индексируемого атрибута a таблицы R (число разных значений, исключая пустое множество);
B (Index (R, a)) - число блоков на листовом уровне индекса по атрибуту a;
Cfilter - среднее время фильтрации одной записи;
CB - время чтения/записи одного блока на диск;
k - мощность атрибута a в запросе (число разных значений, указанных в подзапросе y).
Определение k:
- k =1, если y: a = const;
- k = n, если y: a IN (C 1... Cn), Ci = const;
- k = диапазон значений, если y: a >= C 1 AND a <= C 2;
- k = число атрибутов, удовлетворяющих образцу, если y: a LIKE 'чтонить'.
Отличие физического плана от логического
Логический план не указывает, как реализуются операции реляционной алгебры, а физический определяет, как они будут реализованы.
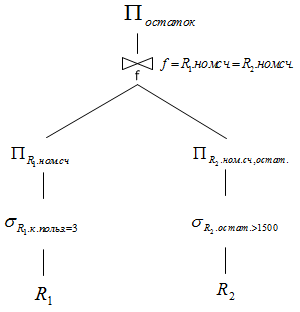
Пример логического плана