2014-02-04
2014-02-04 1553
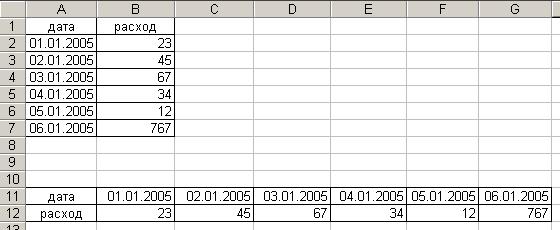
1553Это реорганизация данных, при которой меняется их распределение "по столбцам" на "по строкам" и наоборот. Порядок транспонирования:
· выделить исходный диапазон данных
· команда Правка/Копировать или Правка/вырезать
· установить курсор в пустую ячейку (новое место расположения)
· команда правка/Специальная вставка опция Транспонирование.
Пример:
III. ППП STATISTICA
ППП STATISTICA содержит полный набор статистических методов анализа данных, в том числе нейронные сети, и высококачественную графику (сотни типов графиков).
Состоит из следующих частей (окон):
· таблицы исходных данных
· Графики
· Таблицы результатов
Лист рабочей книги файл (например, с исходными данными) - *.sta График *.stw
Данные организованы в виде электронной таблицы:
· Столбцы – это переменные Variable
· Строки – это наблюдения Cases
Характерная черта ППП – внизу панель анализа, на которой располагается значок свернутого окна доступа к различным видам анализа, возврата на предыдущие шаги и др. опции. Не следует закрывать это окно до конца анализа данных.
Нейронные сети – используются когда другие виды анализа неприменимы, т.е.:
· анализ данных со сложной нелинейной структурой зависимостей
· распознавание и классификация
· нелинейное понижение размерности
IV. ППП SPSS
Содержит полный набор статистических методов анализа данных, кроме нейронных сетей, модульную структуру, отличается низкой стоимостью.
Предлагаются следующие процедуры:
1. Общая линейная модель (GLM) содержит модели:
1.1. линейная регрессия,
1.2. одномерный дисперсионный анализ,
1.3. одномерный ковариационный анализ,
1.4. многомерный дисперсионный анализ
1.5. многомерный ковариационный анализ и др.
2. Смешанная линейная модель (Mixed) содержит модели:
2.1. Однофакторный дисперсионный анализ (ANOVA) с фиксированными эффектами
2.2. рандомизированные полные блоки
2.3. случайные эффекты
2.4. случайные коэффициенты
2.5. многоуровневый анализ,
2.6. безусловная модель линейного роста,
2.7. модель линейного роста с ковариатами,
2.8. модель повторных измерений с ковариатами, зависящими от времени и др.
3. Политомическая (PLUM) - универсальная логит модель (дает возможность предсказывать порядковые исходы с более чем двумя категориями. Например, можно исследовать факторы, влияющие на уровень интереса (низкий, средний, высокий) покупателей к товару.
4. Оценка компонент дисперсии (VARCOMP) - ряд методов оценки компонент дисперсии для каждого случайного эффекта в смешанных моделях.
5. Анализ выживаемости
6. Многовходовые таблицы сопряженности (LOGLINEAR)
7. Иерархические Многовходовые таблицы сопряженности (HILOGLINEAR)
8. Подгонка моделей к данным (GENLOG)
9. Оценка временного интервала
10. Пропорциональные риски с зависящими от времени ковариатами
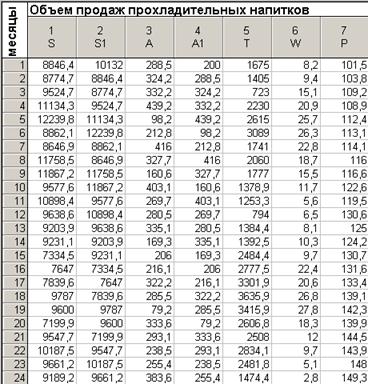 Основные результаты множественной линейной регрессии (для курсовой работы)
Основные результаты множественной линейной регрессии (для курсовой работы)
S - объем продаж за текущий месяц,
S1 - объем продаж за предыдущий месяц,
A - расходы на рекламу в текущем месяце,
A1 - расходы на рекламу в предыдущем месяце,
T - число туристов в текущем месяце,
W - средняя температура воздуха,
P - индекс розничных цен в текущем месяце
Предполагается следующая зависимость:
S=к1ZS1+к2ZA+к3ZA1+к4ZT+к5ZW+к6ZP
Требуется определить:
1. существует ли эта линейная связь, степень линейности
2. коэффициенты к1, к2, к3, к4, к5, к6.
3. точность регрессии
4. прогнозируемое значение зависимой переменной S
5. график зависимости
6. значения остатков по Дарбину-Уотсону
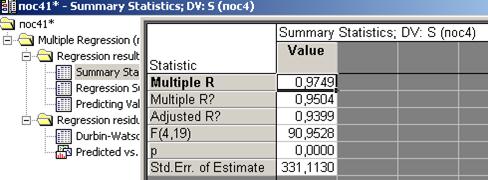
Коэффициент корреляции R=0,9749, т.е. больше 0,9, следовательно получена очень сильная линейная связь между зависимой и независимыми переменными.
P<0,0000
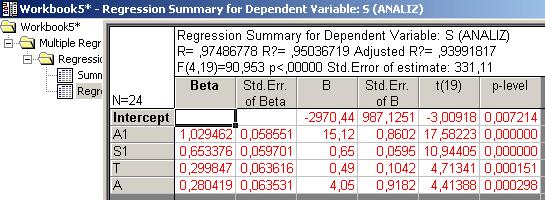
S=0,653376ZS1+0,280419ZA+1,029462ZA1+0,299847ZT
Наибольшее влияние на зависимую переменную S оказывает переменная A1, затем S1, далее Т и А. Коэффициенты к5 и к6 очень малы, поэтому переменные W и P пренебрежимо мало влияют на переменную S
К1, к2, к3, к4 значимы, т.к. p-level для каждого из них меньше 0,05
Beta – стандартизованные коэффициенты регрессии
B - нестандартизованные коэффициенты регрессии
Если в полученное уравнение подставить прогнозируемые значения независимых переменных, то можно получить прогнозируемое значение зависимой переменной
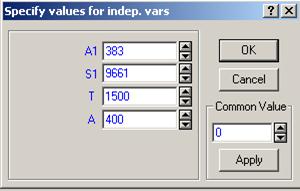
 Прогноз 11473,93
Прогноз 11473,93
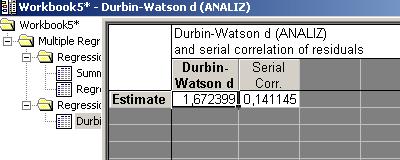
Анализ остатков (разницы между теоретическими и фактическими значениями)
Если остатки зависимы, то модель неадекватна (нарушение важного предположения о независимости ошибок в регрессионной модели)
Критические точки статистики Дарбина-Уотсона приведены в специальных таблицах, например, для числа наблюдений 24 для 4-х независимых переменных DL=1,01 DU=1,78
Получено значение d=1,672399 т.е.d>DL (4 –d)>DL
1,67>1,01 2,33>1,78
Полученная регрессионная модель адекватна.
например, для числа наблюдений 31 для 5-и независимых переменных DL=1,09 DU=1,83
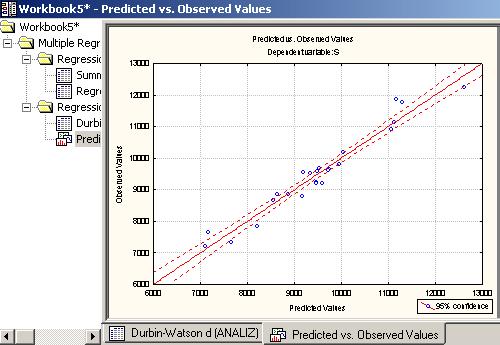
График предсказанных и наблюдаемых значений