 2014-02-02
2014-02-02 817
817Ограничения целостности
Примерный набор операций может быть следующим:
- найти конкретную запись в наборе однотипных записей (инженера Сидорова);
- перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310);
- перейти к следующему потомку в некоторой связи (от Сидорова к Иванову);
- перейти от потомка к предку по некоторой связи (найти отдел Сидорова);
- создать новую запись;
- уничтожить запись;
- модифицировать запись;
- включить в связь;
- исключить из связи;
- переставить в другую связь и т.д.
В принципе их поддержание не требуется, но иногда требуют целостности по ссылкам (как в иерархической модели).
Достоинства ранних СУБД:
- развитые средства управления данными во внешней памяти на низком уровне;
- возможность построения вручную эффективных прикладных систем;
- возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Недостатки дореляционных СУБД:
- слишком сложно пользоваться;
- фактически необходимы знания о физической организации данных;
- прикладные программы зависят от физической организации;
- логика прикладных программ перегружена деталями организации доступа к БД.
Физические модели определяет способ размещения данных в среде хранения и способы доступа к этим данным, которые поддерживаются на физическом уровне. Среди самых важных характеристик любой базы данных следует назвать производительность, надежность и простоту администрирования. Знание того, как большинство СУБД физически хранят данные во внешней памяти, представление о параметрах этого хранения и соответствующих методах доступа может очень помочь при проектировании баз данных, обладающих заданной производительностью. Любая логическая структура данных представляется на физическом уровне в виде последовательности битов.
Можно выделить следующие аспекты проблемы физического представления данных:
I. Как найти нужную запись? Необходимо установить соответствие между логической записью и адресом физической записи. Под физической зап и сью будем понимать последовательность битов, которые можно прочесть с помощью одной машинной инструкции. Логические записи находят по ключу или совокупности ключей.
II. Каким образом организовать данные, чтобы их поиск был эффективным, а выборку можно было осуществить по совокупности ключей?
III. Как можно добавить новую запись к данным, уничтожить старые записи и при этом не нарушить системы адресации и поиска, а также сами структуры данных.
Укажем основные факторы, влияющие на физическую организацию данных для конкретных БД:
- произвольная или последовательная обработка данных. Для определения вид обработки используют коэффициент активности файла (k)
k=z1/z,
где z1 – число записей, считанных за 1 прогон; z - число записей, просмотренных за 1 прогон. Если k высок, то используют последовательную обработку, например при расчете заработной платы;
- частота обращения к определенным записям;
- время ответа (важно для систем реального времени);
- способность к расширению (особенно, если добавляется записей больше, чем уничтожается);
- возможность организации поиска по нескольким ключам.
Можно выделить следующие способы адресации (поиска нужной записи):
1. Последовательное сканирование файла с проверкой ключа каждой записи. Такой метод используется, если выбран последовательный метод обработки данных или используется файл последовательного доступа. Требует много времени.
2. Блочный поиск. Если записи упорядочены по ключу, то при сканировании не требуется чтение каждой записи. Считывается первая запись блока и ее ключ сравнивается с ключом искомой записи. А далее или просматриваются все записи данного блока или выбирается первая запись следующего блока.
3. Преобразование ключа в адрес - самая быстрая организация поиска. Сейчас применяется технология хэширования – технология быстрого доступа к хранимой записи на основе вычисления специальной функции от заданного значения некоторого поля. Это значение и является адресом для записи.
4. Поиск по индексу. Первичный индекс – индекс, использующий в качестве входной информации первичный ключ. В индексном файле запись состоит из индекса и указателя. Сначала проводится поиск в индексе, а потом по указателю обращаемся к основному файлу с записями. Эффективно, быстро, но требуется память для хранения индекса.
5. Бинарный (двоичный) поиск для записей, упорядоченных по ключу.
6. Поиск по В-дереву.
Исторически первыми системами хранения и доступа были файловые структуры и системы управления файлами, которые фактически являлись частью операционных систем. СУБД создавала над этими файлами свою надстройку, которая позволяла организовать всю совокупность файлов таким образом, чтобы она работала как единое целое и получала централизованное управление от СУБД. При этом непосредственный доступ осуществлялся на уровне файловых команд, которые СУБД использовала при манипулировании файлами.
Однако механизмы буферизации и управления файловыми структурами не приспособлены для решения задач собственно СУБД, так как создавались для традиционной обработки файлов, и с ростом объемов хранимых данных они стали неэффективными для использования СУБД. Тогда постепенно произошел переход от базовых файловых структур к непосредственному управлению размещением данных на внешних носителях самой СУБД. При этом механизмы, применяемые в файловых системах, перешли во многом и в новые системы организации данных во внешней памяти, называемые чаще страничными системами хранения информации. Любое упорядоченное расположение данных на диске, называется структурой хранения. На рис. 2.5 приведена классификация структур хранения информации в БД.
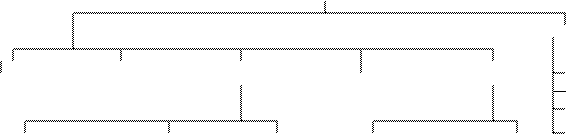 Структуры хранения информации в БД
Структуры хранения информации в БД
Файловые Бесфайловые
прямого последовательного индексные инвертированные взаимосвязанные строки
доступа доступа списки файлы страницы
чанки
экстенты
индексно-прямые индексно- В-деревья с однонаправ- с двухнаправ-
последовательные ленными ленными
цепочками цепочками
Рисунок. 2.5. Классификация структур хранения информации в БД








