 2014-02-02
2014-02-02 3422
3422Приоритетные дисциплины диспетчеризации (ПДД)
Принцип, заложенный для приоритетов: HPF – highest priority first (наивысший приоритет - первым).
Приоритет – это право на первоочередное обслуживание.
ПДД – характеризуется более сложной работой с очередью.
Назначение приоритета процессам происходит на основе:
- статистических характеристик:
- ожидаемый объем ввода/вывода;
- априорное tобслуж.; (знание, полученное до опыта, апостериори – после опыта)
- внешний приоритет;
- ожидаемый объем ОП.
- динамических характеристик:
- время нахождения в системе;
- объем вводимых/выводимых операций в предыдущий момент времени.
ДД с фиксированным приоритетом
Процессы располагаются в очереди готовых процессов в соответствии со своим приоритетом. Если поступило несколько процессов одного приоритета, то в очереди они обслуживаются по принципу FIFO.
Недостатки дисциплин с фиксированным приоритетом
- неточность априорных характеристик приводит к приблизительности приоритета;
- возможность приспосабливаемости пользователей к системе приоритета. Если пользователю известно о системе приоритетов, т.е. больше «уважают» короткие заявки в системе, то пользователь составит 2 короткие вместо 1-ой длинной, но тогда система становится на уровень FIFO;
- при хороших и средних характеристиках параметра tожидан., отдельные заявки в системе могут длительное время ждать. Для устранения этого недостатка надо бы повысить приоритет задачи, но т.к. он фиксирован, это невозможно;
- отсутствует настраиваемость системы на изменение характеристик входного потока заявок.
ДД с динамическим приоритетом
Приоритет изменяется в период пребывания в системе (либо в процессе ожидания, либо в процессе выполнения)
Если низкоприоритетный процесс ждет длительное время, его приоритет повышается.
Pi(t) = ai tожидан. + bi tвыполн., где Pi(t) – приоритет i- го процесса
Дисциплины с динамическим приоритетом
- Следующий - с минимальным оставшимся временем(SRT).
(SRT – shortest-remaining-time)
Оставшееся время – разность между временем, запрошенным процессом, и временем, которое процесс уже получил (измеряется с помощью системных часов).
Аналог SJN с перераспределением процессора.
Короткие процессы еще более выигрывают за счет длинных.
Так как SJN и SRT основаны на оценке времени, то они не подходят для диспетчеризации интерактивных процессов.
Недостатком дисциплин, основанных на сокращении общего времени ожидания, является задержка выполнения длинных процессов (процессы могут теряться практически навсегда).
Если к требованию минимизации добавить требование гарантированного завершения всех процессов, то можно получить новые дисциплины диспетчеризации.
- Следующий – с наивысшим отношением отклика(HRRN)
(HRRN - highest response ratio next)
Отношение отклика R= (w+s)/s, где w -время затраченное процессом на ожидание,s –ожидаемое время обслуживания. Минимальное значение R (равное 1) при входе процесса в систему.
Правило стратегии: При завершении, прерывании или блокировании текущего процесса, для выполнения из очереди готовых процессов выбирается тот, который имеет наибольшее значение R (учитывается возраст процесса). Циклическая дисциплина с приоритетом.
Достоинства системы с динамическим приоритетом:
- возможность настраиваться при изменении характеристик входного потока на эффективное обслуживание;
- дисциплина основана на реальных динамических характеристиках процессов.
Недостаток: сложность реализации.
Вывод по приоритетным ДД - они сокращают время ожидания. высокоприоритетных заявок за счет увеличения времени ожидания низкоприоритетных.
Дисциплины с несколькими очередями.
Процессы делятся на классы и процессы разных классов обслуживаются по разному.
Классы процессов:
- Реального времени (д.б. обслужен до наступления конкретного момента времени) (Оперативные процессы с высоким приоритетом).
2. Интерактивные (д.б. обслужен в течение приемлемого времени реакции). (Оперативные процессы с высоким приоритетом).
3. Пакетные (нет жестких ограничений на время обслуживания). (Фоновые процессы с низким приоритетом).
Для каждой из очередей можно использовать свою дисциплину и разные значения управляющих параметров (например, длина кванта).
Связь процесса с очередью м.б.:
- статична – процесс всегда возвращается в одну и ту же очередь;
- динамична – процесс при различных обстоятельствах возвращается в разные очереди.
Гарантия обслуживания.
Более жестким требованием к системе, чем просто гарантированное завершение процесса, является его гарантированное завершений к указанному времени или за указанный интервал времени.
В системе с пакетными и интерактивными процессами на последние можно наложить жесткие временные ограничения, чтобы обеспечить необходимое время ответа.
Гарантировать обслуживание можно тремя разными способами:
- Выделять минимальную долю процессорного времени классу процессов, если по крайней мере один из процессов готов к исполнению (классы –процессы реального времени, интерактивные процессы, пакетные процессы)
- Выделять минимальную долю процессорного времени некоторому конкретному процессу, если он готов к исполнению.
- Выделять столько процессорного времени некоторому процессу, чтобы он мог выполнить необходимые действия к сроку
Диспетчеризация в мультипроцессорной системе
Задача заключается в том, что необходимо решать, какой процесс на каком процессоре должен выполняться.
- Алгоритм разделения времени
Простейший алгоритм диспетчеризации процессов (или потоков) состоит в поддержании единой очереди готовых потоков (возможно с различными приоритетами).
Наличие единой очереди, используемой всеми центральными процессорами, обеспечивает процессорам режим разделения времени подобно тому, как это выполняется на однопроцессорной системе.
Кроме того, такая организация позволяет автоматически балансировать нагрузку, то есть она исключает ситуацию, при которой один центральный процессор простаивает, в то время как другие процессоры перегружены.
2. Алгоритм родственного планирования.
Основная идея данного алгоритма заключается в том, чтобы поток был запущен на том же центральном процессоре, что и в прошлый раз. Один из способов реализации этого метода состоит в использовании двухуровневого алгоритма планирования. В момент создания поток назначается конкретному центральному процессору, например, наименее загруженному в данный момент. Это назначение процессов процессорам представляет собой верхний уровень алгоритма. В результате каждый центральный процессор получает свой набор потоков.
Действительное планирование потоков находится на нижнем уровне алгоритма. Оно выполняется отдельно для каждого центрального процессора. Старания удерживать процессы на одном и том же центральном процессоре максимизируют родственность кэша. Однако если у какого-либо центрального процессора нет работы, у загруженного работой процессора отнимается поток и отдается ему.
Двухуровневое планирование обладает тремя преимуществами
- Во-первых, оно довольно равномерно распределяет нагрузку среди имеющихся центральных процессоров.
- Во-вторых, двухуровневое планирование по возможности использует преимущество родственности кэша.
- В-третьих, поскольку у каждого центрального процессора при таком варианте планирования есть свой собственный список свободных процессов, конкуренция за списки свободных процессов минимизируется, так как попытки использования списка другого процессора происходят относительно нечасто.
3. Совместное использование пространства (процессоров).
Другой подход к планированию мультипроцессоров может быть использован, если потоки связаны друг с другом каким-либо способом.
Планирование нескольких потоков на нескольких центральных процессорах называется совместным использованием пространства или разделением пространства.
Простейший алгоритм разделения пространства работает следующим образом.
· Создается группа связанных потоков.
· В момент их создания планировщик проверяет, есть ли свободные центральные процессоры по количеству создаваемых потоков.
· Если свободных процессоров достаточно, каждому потоку выделяется собственный (то есть работающий в однозадачном режиме) центральный процессор и все потоки запускаются.
· Если процессоров недостаточно, ни один из потоков не запускается, пока не освободится достаточное количество центральных процессоров.
· Каждый поток выполняется на своем процессоре вплоть до завершения, после чего все центральные процессоры возвращаются в пул свободных процессоров.
· Если поток оказывается заблокированным операцией ввода-вывода, он продолжает удерживать центральный процессор, который простаивает до тех пор, пока поток не сможет продолжать свою работу.
Периодически должны приниматься решения о планировании процессов. В однопроцессорных системах для пакетного планирования применяется хорошо известный алгоритм «кратчайшее задание первое». Подобный алгоритм для мультипроцессора представляет собой выбор процесса, для которого требуется наименьшее количество циклов процессора, то есть процесса, чье произведение числа центральных процессоров на время работы минимально. Однако на практике эта информация редко бывает доступна, поэтому применение такого алгоритма затруднительно. Действительно, исследования показали, что придумать что-либо лучшее простого обслуживания заданий в порядке их поступления трудно.
В этой простой модели разбиения процессоров на группы процесс просто запрашивает определенное количество центральных процессоров и либо сразу получает их, либо ждет, пока они не освободятся. Другой подход состоит в том, чтобы активно управлять степенью распараллеливания процессов.
Один из способов управления степенью распараллеливания заключается в наличии центрального сервера, ведущего учет работающих и желающих работать процессов, а также минимального и максимального количества требующихся для них центральных процессоров. Периодически каждый центральный процессор опрашивает центральный сервер, чтобы узнать, сколько центральных процессоров он может использовать. Затем он увеличивает или уменьшает количество процессов или потоков, стараясь добиться соответствия числу доступных процессоров. Например, на web-сервере могут параллельно работать 1. 2, 5, 10, 20 или любое другое количество потоков. Если на нем в настоящий момент работает 10 потоков и вдруг спрос на центральные процессоры повышается, то ему могут приказать сократить число своих потоков до 5. Поэтому, когда 5 потоков закончат свою работу, они не получают новую работу, а завершаются. Такая схема обеспечивает динамическое изменение размеров групп процессоров, чтобы добиться лучшего соответствия текущей нагрузке
4. Бригадное планирование.
Множество потоков процесса распределяются для одновременного выполнения на множестве процессоров, по одному потоку на процессор.
Очевидное преимущество разделения пространства заключается в устранении многозадачности, что снижает накладные расходы по переключению контекста. Однако ее недостаток состоит в потерях времени при блокировке центрального процессора.
Поэтому проводились активные поиски алгоритма, пытающегося планировать одновременно в пространстве и времени, особенно для процессов, создающих большое количество потоков, которым, как правило, требуется возможность общения друг с другом.
Чтобы понять, какие возможны проблемы при независимом планировании потоков процесса (или процессов задания), рассмотрим систему с потоками Ао и А1,, принадлежащими процессу А, и потоками Во и В1, принадлежащими процессу В. Потоки Ао и Во работают в режиме разделения времени на центральном процессоре 0, а потоки А1, и В1 - на процессоре 1. Потокам Ао и А1 нужно часто обмениваться информацией. Общение потоков выглядит следующим образом. Поток Ао посылает потоку А1 сообщение, после чего поток А1, отправляет потоку Ао ответ и т. д. Предположим, что потоки Ао и Во, начали выполняться первыми. В интервале времени 0 поток Ао посылает потоку А1 запрос, но поток А1 не получает его до тех пор, пока не будет запущен в интервале времени 1. начинающемся через 100 мс. Он немедленно отправляет ответ, но поток Ао не получает ответа, пока его снова не запустят в момент времени 200 мс. В результате за 200 мс мы получаем всего одну пару запрос-ответ, что не слишком хорошо. Решением данной проблемы является так называемое бригадное планирование, представляющее собой развитие идеи совместного планирования.
Бригадное планирование состоит из трех частей:
- Группы связанных потоков планируются как одно целое, бригада.
- Все члены бригады запускаются одновременно, на разных центральных процессорах с разделением времени.
- Все члены бригады начинают и завершают свои временные интервалы (кванты времени) одновременно.
Бригадное планирование работает благодаря синхронности работы всех центральных процессоров.
Это значит, что время разделяется на дискретные кванты. В начале каждого нового кванта все центральные процессоры перепланируются заново, и на каждом процессоре запускается новый поток. В начале следующего кванта опять принимается решение о планировании. В середине кванта планирование не выполняется. Если какой-либо поток блокируется, его центральный процессор простаивает до конца кванта времени.
Программные модули.
Являются очень важным видом ресурсов.
- Однократно-используемые.
Выполняются один раз (портят либо код, либо данные). Являются неделимыми ресурсами.
Системные однократно-используемые модули, как правило, используются только на этапе загрузки ОС.
2. Многократно (повторно)-используемые
а) Непривилегированные программные модули – обычные программные модули, которые могут быть прерваны во время своей работы.
В общем случае не являются разделяемыми, т.к. если после прерывания процесса запустить его по требованию другого процесса, промежуточные результаты первого процесса м.б. потеряны.
б) Привилегированные программные модули – работают в привилегированном режиме (при отключенной системе прерываний). Являются последовательно используемыми (повторно используемыми) ресурсами. Допускается многократное выполнение действий типа запрос-использование-освобождение.
Структура модуля (рис. 8.1а).
в) Реентерабельные программные модули (reenterable-допускающий повторные обращения) - допускают повторное многократное прерывание своего исполнения и повторный запуск из других вычислительных процессов. Д.б. обеспечено сохранение промежуточных вычислений и возврат к ним, когда процесс возобновляется с прерванной ранее точки.
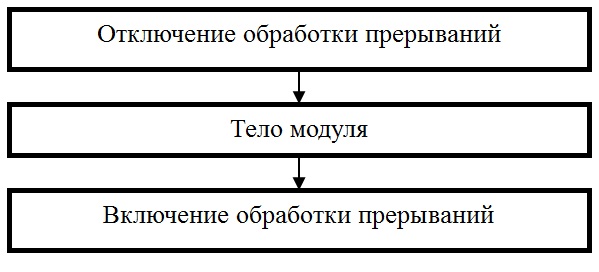
Рис 8.1а. Привилегированный программный модуль
Это обеспечивается с помощью статических и динамических методов выделения памяти под сохраняемые значения.
- статический: резервируется область памяти для фиксированного числа вычислительных процессов(пример: процессы в/в и реентерабельные драйверы для управления параллельно несколькими однотипными устройствами.
- динамический: область памяти выделяется динамически для каждого процесса (наиболее часто используемый) (рис. 8.1б).
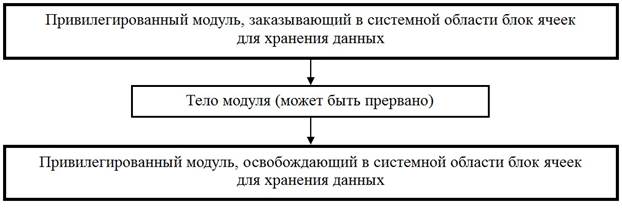
Рис 8.1б. Динамический реентерабельный программный модуль
г) Повторно входимые программные модули (re-entrance) –допускают многократное параллельное использование, но в отличие от реентерабельных их нельзя прерывать в любой точке.
Структура модуля (рис. 8.1в):
- модуль состоит из привилегированных секций и повторное обращение к модулю возможно только после завершения какой-нибудь из этих секций
- после завершения секции управление м.б. передано диспетчеру, и он может предоставить возможность выполняться другому процессу,
В повторно входимых программных модулях четко предопределены все допустимые (возможные) точки входа.
Повторно входимые программные модули встречаются гораздо чаще реентерабельных (повторно прерываемых).
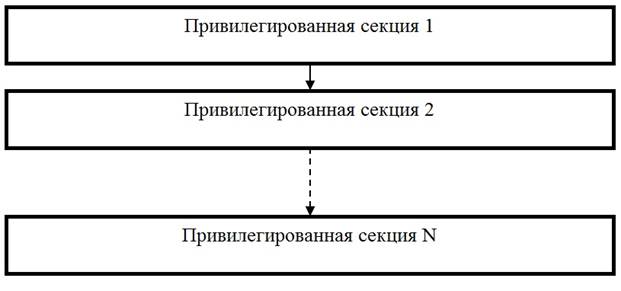
Рис. 8.1в. Повторно входимый программный модуль
Лекция 9. Управление памятью
Отображение программных модулей на оперативную память.
Программа имеет пространство имен – набор логических имен переменных и входных точек программных модулей (чаще всего являются символьными и для которых отсутствует отношение порядка).
Оперативная память – упорядоченное множество ячеек. Количество ячеек ограничено и фиксировано.
Системное программное обеспечение должно связать каждое имя с ячейкой памяти, т.е. осуществить отображение пространства имен на физическую память компьютера.
Отображение осуществляется в два этапа (рис 9.1):
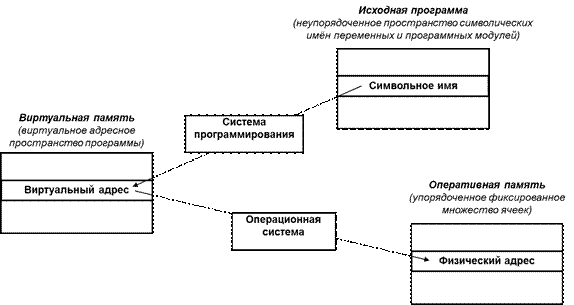
Рис. 9.1. Отображение программных модулей на оперативную память
- Системой программирования на основе логических (символьных) имен формируется виртуальное адресное пространство (виртуальная память) программы - множество всех допустимых значений виртуального адреса.
Виртуальное адресное пространство прежде всего зависит от архитектуры процессора и от системы программирования и практически не зависит от объема реальной физической памяти, на которую это пространство будет отображаться.
Система программирования осуществляет трансляцию и компоновку программы, используя библиотечные программные модули.
В результате работы системы программирования полученные адреса могут иметь как двоичную форму, так и символьно-двоичную, т.е. некоторые программные модули (их, как правило, большинство) и их переменные получают какие-то числовые значения, а те модули, адреса для которых не могут быть сейчас определены, имеют по-прежнему символьную форму и окончательную привязку их к физическим ячейкам будет осуществлена на этапе загрузки программы в память перед ее непосредственным выполнением.
2. Операционной системой с помощью специальных программных модулей управления памятью и использования соответствующих аппаратных средств вычислительной системы производится отображение виртуального адресного пространства программы на физическую память компьютера
Частные случаи отображения:
А) Виртуальное адресное пространство тождественно физической памяти.
Нет необходимости во втором отображении.
В данном случае система программирования генерирует абсолютную двоичную программу.
Абсолютная двоичная программа – все двоичные адреса в ней таковы, что программа может исполняться только в том случае, если ее виртуальные адреса будут точно соответствовать физическим.
Часть программных модулей любой ОС должна быть абсолютными двоичными программами. Эти программы размещаются по фиксированным адресам и с их помощью размещаются другие программы, которые могут работать на различных физических адресах, на которых их разместит ОС.
Б) Виртуальное адресное пространство тождественно исходному пространству имен.
Отображение выполняет сама ОС, которая во время исполнения использует таблицу символьных имен.
Отображение имен на адреса выполняется для каждого нового имени. Схема интерпретации.
Промежуточные варианты:
- Транслятор-компилятор генерирует относительные адреса (которые по сути являются виртуальными.
Перемещающий загрузчик настраивает программу на один из непрерывных разделов. После загрузки программы виртуальный адрес теряется, и доступ осуществляется непосредственно к физическим ячейкам.
2. Транслятор-компилятор генерирует в качестве виртуальногоадреса относительный адрес и информацию о начальном адресе.
Процессор, используя подготовленную ОС адресную информацию, выполняет второе отображение не один раз (при загрузке программы), а при каждом обращении к памяти.
Методы управления памятью.
- Своппинг (Swapping).
Метод управления памятью, основанный на том, что все процессы, участвующие в мультипрограммной обработке, хранятся во внешней памяти.
При выделении процессу процессора он перемещается в ОП (swap in/roll in).
При прерывании процесса он перемещается во внешнюю память (swap out/roll out).
При свопинге происходит перемещение всей программы.
Основное применение своппинг находит в системах разделения времени, где он используется одновременно с циклической стратегией планирования.
Недостаток «чистого» своппинга в больших потерях времени на загрузку/выгрузку процессов.
В современных ОС используются модифицированные варианты своппинга (во многих версиях ОС UNIX своппинг включается только в том случае, если количество процессов в ОП становится слишком большим).
2. Смежное размещение процессов.
Простейшее размещение. Выделяется один непрерывный участок адресного пространства.
- Однопрограммный режим.
- Мультипрограммирование с фиксированными разделами MFT ( Multiprogramming with a fixed number of tasks). Фиксируются границы разделов. В каждом разделе один процесс. Фрагментация: Внутренняя – размер процесса меньше размера раздела. Внешняя – размер процесса в очереди больше размера раздела
- Мультипрограммирование с переменными разделами MVT (Multiprogramming with a variable number of tasks). Границы разделов не фиксируются. В начальной фазе фрагментации нет. На фазе повторного размещения те же причины фрагментации, что и для MFT.
- Мультипрограммирование с переменными разделами и уплотнением памяти. Уплотнение – перемещение занятых разделов по адресному пространству памяти таким образом, чтобы свободный фрагмент занимал одну связную область.
Недостатки: когда мультипрограммная смесь неоднородна по отношению к размерам программ, возникает необходимость в частом уплотнении, что расходует ресурс «процессорное время» и компенсирует экономию ресурса «оперативная память».
3. Несмежное размещение процессов.
Программа разбивается на множество частей, которые располагаются в различных, не обязательно смежных участках адресного пространства.
- Сегментная организация (рис 9.2).
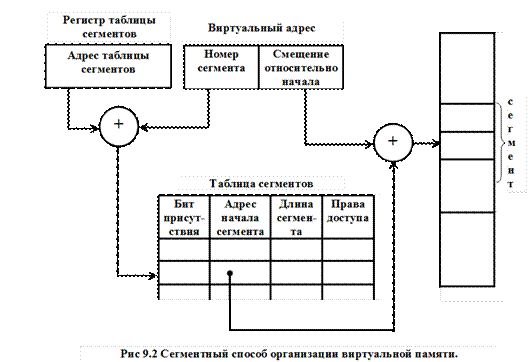
В этом случае программа и связанные с ней данные разделяются на ряд сегментов. Хотя и существует максимальный размер сегмента, на них не накладывается условие равенства размеров.
Логический адрес при сегментной организации состоит из двух частей:
- S - номер сегмента
- d - смещение в пределах сегмента
S используется в качестве индекса для таблицы сегментов. С помощью таблицы сегментов определяется начальный адрес сегмента в оперативной памяти. Физический адрес определяется как S+d.
Если таблица сегментов имеет значительные размеры, она располагается в ОП, а ее начальный адрес и длина хранятся в специальных регистрах.
Защита сегментной памяти основана на контроле уровня доступа к каждому сегменту (например, сегменты, содержащие только код, могут быть помещены как доступные только для чтения или выполнения, а сегменты, содержащие данные, помечают как доступные для чтения и записи).
Поскольку сегмент является логически завершенным программным модулем, он может использоваться различными процессами. Сегмент называется разделяемым, если его начальный адрес и размер указаны в двух и более таблицах сегментов.
Сегментной организации присуща фрагментация:
- Внутренняя фрагментация – когда размер загружаемого сегмента меньше размера имеющегося свободного раздела.
- Внешняя фрагментация – отсутствует участок памяти подходящего размера. Часть процесса остается незагруженной, и его выполнение в какой-то момент времени должно быть приостановлено.
2. Страничная организация памяти (рис. 9.3) 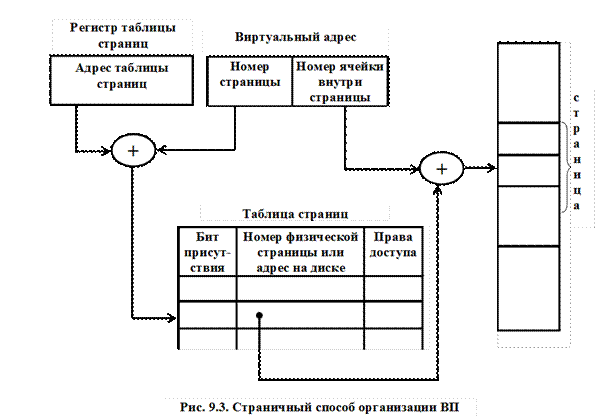
Позволяет свести к минимуму общую фрагментацию за счет полного устранения внешней фрагментации и минимизации внутренней фрагментации.
Адресное пространство оперативной и внешней памяти разбивается на блоки фиксированного размера, называемые страничными рамками (frames, фреймы, кадры).
Логическое адресное пространство программы также разбивается на блоки фиксированного размера, называемыми страницами (pages). Размеры страничных рамок и страниц совпадают.
Процесс загружается в память постранично, причем каждая страница помещается в любую свободную страничную рамку основной памяти.

