 2014-02-02
2014-02-02 2200
2200Технологии искусственного интеллекта ч.2
Лекция 10
Как правило, данные, обрабатываемые в информационных системах, носят четкий, числовой характер. Однако в запросах к базам данных, которые пытается формулировать человек, часто присутствуют неточности и неопределенности.
Нет ничего удивительного, когда на запрос в поисковой системе Интернет пользователю выдается множество ссылок на документы, упорядоченных по степени релевантности запросу. Потому что текстовой информации изначально присуща нечеткость и неопределенность, причинами которой является семантическая неоднозначность языка, наличие синонимов и т.д.
Например, из базы данных требуется извлечь следующую информацию:
" Получить список молодых сотрудников с невысокой заработной платой "
" Найти предложения о сдаче не очень дорогого жилья близко к центру города "
Здесь высказывания " Молодой ", " Невысокая ", " Не очень дорогой ", " Близко " имеют размытый, неточный характер, хотя заработная плата определена до рубля, а удаленность квартиры от центра - с точностью до километра. Причиной всему служит то, что в реальной жизни мы оперируем и рассуждаем неопределенными, неточными категориями.
Концепция нечетких запросов базируется на математической теории нечетких множеств (fuzzy sets) и аппарате нечеткой логики (fuzzy logic), предложенной Л. Заде в 1965 году. Нечеткая логика - черезвычайно полезный инструмент для моделирования приближенных рассуждений. Она позволяет аккумулировать знания о некоторой предметной области, или, проще говоря, является одной из моделей представления знаний.
Нечетким множеством A в непустом четком пространстве X называется множество пар вида A={ х / MF(x) },
где MF(x) - функция принадлежности нечеткого множества A. Эта функция приписывает каждому элементу x є Х степень его принадлежности к нечеткому множеству A.
Например, формализуем нечеткое понятие А="Высокая цена на нефть" (долл. за баррель). Для этого введем область изменения значений переменной "Цена на нефть" X = [15; 30] и зададим множество пар:
A = {20/0,2; 21/0,35; 22/0,4; 23/0,5; 24/0,7; 25/0,8; 26/0,9; 27/0,95; 28/1,0; 29/1,0; 30/1,0}.
Знак "/" в данном случае не означает деление, а означает присваивание конкретным элементам множества соответствующих степеней принадлежности. Степень принадлежности не нужно путать с вероятностью, носящей объективный характер и подчиняющейся другим математическим зависимостям.
Лингвистическая переменная (ЛП) — это переменная, значение которой задается набором вербальных (то есть словесных) характеристик некоторого свойства.
В общем случае лингвистическая переменная представляет собой набор, в состав которого входят:
· название лингвистической переменной (например, "Цена акции");
· универсальное множество X, или область определения лингвистической переменной;
· множество ее значений T (базовое терм-множество), представляющих собой наименования нечетких переменных, например: "Низкая (цена)", "Высокая (цена)" и т.д.
Для задания нечетких множеств часто используют стандартные формы функций принадлежности. Наибольшее распространение получили кусочно-линейные формы, а именно: треугольная и трапецеидальная (Рис.1).
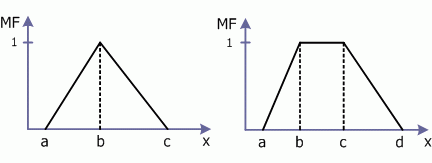
Рис. 1 Треугольная и трапецеидальная функции принадлежности
Треугольная функция принадлежности задается тройкой чисел a, b, c:
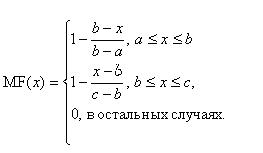
При b-a=c-b имеем случай симметричной треугольной функции принадлежности.
Аналогично трапецеидальная функция принадлежности задается четверкой чисел a, b, c, d:
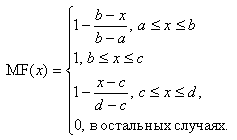
Треугольная функция принадлежности есть частный случай трапецеидальной при b=c.
Функции принадлежности для краткости записываются в виде: треугольная MF(x)=[а,в,с], трапецеидальная MF(x)= [a,b,c,d]. Определение конкретных значений a,b,c,d относится к компетенции экспертов.
Пример
Определить возраст сотрудника компании «Молодой», «Средний», «Выше среднего».
Введем лингвистическую переменную "Возраст сотрудника компании". Зададим для нее область определения X = [18; 60] и три лингвистических терма Т1,Т2,Т3 - "Молодой", "Средний", "Выше среднего".
 |
Для термов выберем трапецеидальные функции принадлежности со следующими координатами:
"Молодой" = [18, 18, 28, 34],
"Средний" = [28, 35, 45, 50],
"Выше среднего" = [42, 53, 60, 60].
Теперь можно вычислить степень принадлежности сотрудника 30 лет к каждому из нечетких термов:
MF[Молодой](30)=0,67;
MF[Средний](30)=0,29;
MF[Выше среднего](30)=0.
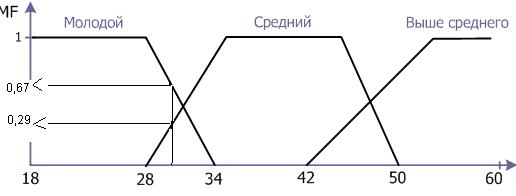
Рис.2 Функции принадлежности
Основное требование при построении функций принадлежности - значение функций принадлежности должно быть больше нуля хотя бы для одного лингвистического терма. Как правило, количество термов не превышает 7.
По такому же принципу могут быть построены функция принадлежности по оценке, например, состояния предприятия «Состояние предприятия» с термами «Очень плохое», «Плохое», «Нормальное», «Хорошее», «Очень хорошее», где по оси х может быть отложена рентабельность предприятия.
Основными потребителями нечеткой логики являются банкиры и финансисты, а также специалисты в области политического и экономического анализа. Они применяют информационные системы, использующие правила нечеткой логики, для создания моделей различных экономических, политических, биржевых ситуаций.
Начало этому процессу положила японская финансовая корпорация Yamaichi Securuties. Задавшись целью автоматизировать игру на рынке ценных бумаг, эта компания привлекла к работе около 30 специалистов по искусственному интеллекту. В первую версию системы, завершенную к началу 1990 года, вошли 600 нечетких функций принадлежности - воплощение опыта десяти ведущих брокеров корпорации. Прежде чем решиться на использование новой системы в реальных условиях, ее протестировали на двухлетней выборке финансовых данных (1987-1989 г). Система с блеском выдержала испытание. Особое изумление вызвало то, что за неделю до наступления биржевого краха (знаменитого «Черного Понедельника» на токийской бирже в 1988 году) система распродала весь пакет акций, что свело ущерб практически к нулю. После этого вопрос о целесообразности применения нечеткой логики в финансовой сфере уже не поднимался. Хотя скептики могут привести и другие примеры - например, ни одна из банковских систем не смогла предсказать падение биржевого индекса Nikkei весной 1992 года. Можно привести и другие примеры применения нечеткой логики в бизнесе. Удачный опыт Ганса по использованию экспертной системы с нечеткими правилами для анализа инвестиционной активности в городе Аахене (ФРГ) привел к созданию коммерческого программного пакета для оценки кредитных и инвестиционных рисков. На рынке коммерческих экспертных систем на основе нечеткой логики в России наиболее известным является экспертная система CubiCalc.

