 2014-02-03
2014-02-03 1642
1642Моделирование данных в более сложных случаях
Наиболее распространенные датчики генерации случайных величин моделируют данные наиболее известных теоретических распределений. Рассмотрим способ моделирования, который позволяет моделировать эмпирические данные, то есть такие которые трудно соотнести с каким-либо теоретическим законом распределения. Предположим, что некоторый исследователь опубликовал свои исследования по изучению случайной величины, которую он наблюдал при изучении реального процесса или явления. Результаты демонстрируются гистограммой. Задача состоит в том, чтобы смоделировать данные подчиняющиеся представленной гистограммой.
Простейшим методом моделирования эмпирических данных является метод неравномерной рулетки. Этот метод удобно рассмотреть на основе использования данных некоторого гипотетического примера. Пусть данные для гипотетического примера заданы некоторым частотным рядом, представленным на рис. 4.1 Гистограмма, построенная по данным гипотетического примера, приведена на рис. 4.2.

Рис. 4.1. Исходные данные гипотетического примера
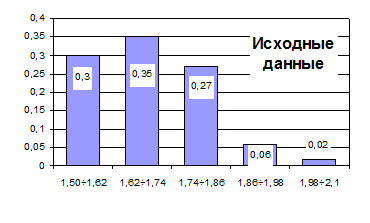
Рис. 4.2. Гистограмма эмпирического частотного ряда
Построим неравномерную рулетку (рис. 4.3). Для этого выложим на отрезке (0,1) частоты заданного частотного ряда (цифры на оси сверху) и рассчитаем накапливаемые частоты (цифры на оси снизу). Данные по неравномерной рулетке разместим в таблице (рис. 4.4).
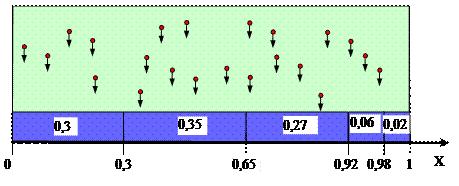
Рис. 4.3. Графическое представление неравномерной рулетки
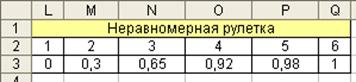
Рис. 4.4. Табличное представление неравномерной рулетки
Принцип работы генератора на основе неравномерной рулетки очень прост. Представим себе, что интервалы неравномерной рулетки это некоторые сосуды различной ширины. Если сверху ссыпать сухой горох сразу во все сосуду, то в результате количество гороха в различных сосудах будет пропорционально ширине сосуда. Теперь, если связать попадание гороха в сосуд с выпадением случайной величины, принадлежащей одному из интервалов диапазона моделируемой величины (границы интервалов в таблице на рис. 31), можно утверждать, что случайная величина будет выпадать пропорционально частоте моделируемого эмпирического частотного ряда. Выпадение определенного интервала мы можем связать с событием выпадения значения равного середине соответствующего интервала, моделируемой величины. Таким образом, количество различных значений которое будет встречаться в выборке, будет равно количеству интервалов. Эти значения будут встречаться с частотой моделируемого частотного ряда эмпирической случайной величины.
Рассмотрим реализацию этого метода в EXCEL.
Первый шаг. Создать последовательность случайных чисел и разместить их в таблицу данных. Столбец B на рис. 4.5.
Второй шаг. Записать формулу выбора случайной величины по методу неравномерной рулетки во втором столбце таблицы данных (столбец С – модельные данные 1). В формуле используются данные по неравномерной рулетке из таблицы рис. 4.4 и середины интервалов моделируемой случайной величины из таблицы рис. 4.1. Скопировать формулу по столбцу С (рис. 4.6).
Проанализируем результаты моделирования. Для этого построим частотный ряд по модельным данным (рис. 4.6) и гистограмму (рис. 4.7).
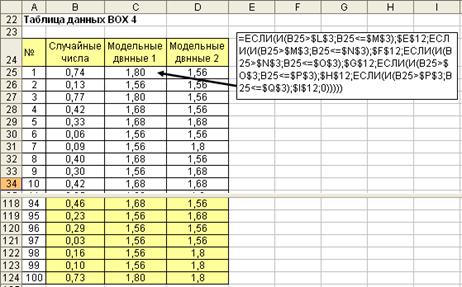
Рис. 4.5. Формула выбора случайной величины по методу неравномерной рулетки
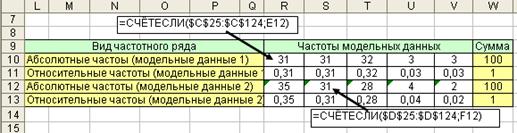
Рис. 4.6. Частотный ряд модельных данных
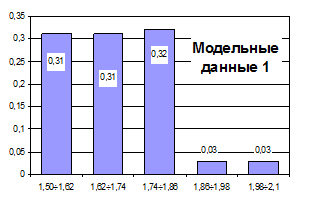
Рис. 4.7. Гистограмма модельных данных 1
Сравнение формы исходного частотного ряда и модельного свидетельствует об их сходстве. Недостатком метода является ограниченное количество вариантов различных значений в модельном ряду. Несомненное преимущество метода состоит в простоте его реализации.
Аналогичный результат можно получить с помощью программы генерации данных в пакете ”Анализ данных”. Для этого в списке программ пакета анализа выбрать программу генерации случайных чисел и определить параметры дискретного распределения (рис. 4.8). Входной интервал значений и частот должен быть представлен в двух столбцах (рис. 4.9). В качестве выходного интервала укажем первую ячейку таблицы данных в столбце “модельные данные 2”.
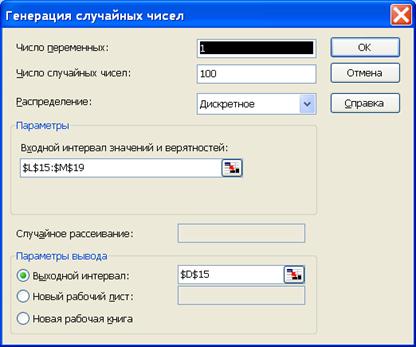
Рис. 4.8. Генерация дискретного распределения
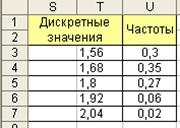
Рис. 4.9. Входной интервал значений и вероятностей
По результатам моделирования частотного ряда дискретного распределения (“модельные данные 2”) построим частотный ряд (рис. 4.10).
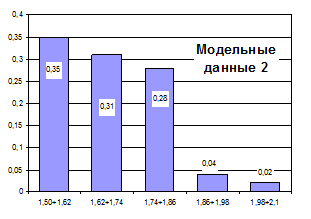
Рис. 4.10. Гистограмма модельных данных 2
Как и в случае моделирования данных с помощью метода неравномерной рулетки частотный ряд, построенный с помощью программы генерации дискретного распределения также имеет большое сходство с исходным частотным рядом.








