 2014-02-03
2014-02-03 682
682Масштабирование и распределение подзадач по процессорам
Как правило, число тел физической системы N значительно превышает количество процессоров p. Поэтому рассмотренные ранее подзадачи следует укрупнить, объединив в рамках одной подзадачи вычисления для группы из N/p тел. После проведения подобной агрегации число подзадач и количество процессоров будет совпадать и при распределении подзадач между процессорами останется лишь обеспечить наличие прямых коммуникационных линий между процессорами с подзадачами, у которых имеются информационные обмены при выполнении операции сбора данных.
Оценим эффективность разработанных способов параллельных вычислений для решения задачи N тел. Поскольку предложенные варианты отличаются только методами выполнения информационных обменов, для сравнения подходов достаточно определить длительность операции обобщенного сбора данных. Используем для оценки времени передачи сообщений модель, предложенную Хокни (см. лекцию 3), - тогда длительность выполнения операции сбора данных для первого варианта параллельных вычислений может быть выражена как
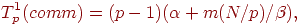
| (4.3) |
где  и β есть параметры модели Хокни (латентность и пропускная способность сети передачи данных), а m задает объем пересылаемых данных для одного тела физической системы.
и β есть параметры модели Хокни (латентность и пропускная способность сети передачи данных), а m задает объем пересылаемых данных для одного тела физической системы.
Для второго способа информационного обмена, как уже отмечалось ранее, объем пересылаемых данных на разных итерациях операции сбора данных различается. На первой итерации объем пересылаемых сообщений составляет Nm/p, на второй этот объем увеличивается вдвое и оказывается равным 2Nm/p и т.д. В общем случае, для итерации с номером i объем сообщений оценивается как 2i-1Nm/p. Как результат, длительность выполнения операции сбора данных в этом случае может быть определена при помощи следующего выражения:
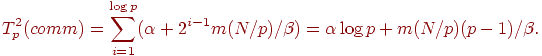
| (4.4) |
Сравнение полученных выражений показывает, что второй разработанный способ параллельных вычислений имеет существенно более высокую эффективность, требует меньших коммуникационных затрат и допускает лучшую масштабируемость при увеличении количества используемых процессоров.








