2014-02-09
2014-02-09 854
854RISC (reduced instruction set computer)
Итого
Организация цикла
Логические
Вещественные
Арифметические команды
A R, addr //слож
S R, A //вычит
M R, A //умн
D R, A //дел
В R заложены два рег-ра: R всегда чётно, операнд в R+1, множ-ль в A, рез-т – в R и R+1.
16-и разрядные команды
AH R, A
SH R, A
MH R, A // Команды DH R, A НЕТ!!!
AE, SE, ME, DE R, A – для полуслова
AD, SD, MD, DD R, A – для слова (word)
N R, A – and
OR R, A
XOR R, A
Пример.
c:=a<b
L R1, a
S R1, b //a-b
L R2, =F'1' //c:=1
BC 2, M //2 – маска перехода (<)
L R2, =F'0' //c:=0
M: … BXLE R1, R2, M // переход по <=, R1 – счетчик, в R2 – шаг, в следующем за R2 – верхний предел.
M: … BXH R1, R2, M //переход по > (шаг вычитается)
1) Память тратится впустую
2) IBM сделали машины от больших и до маленьких с одинаков. Сист. Команд
3) У-ва I/O отделены, процессор заказывает файл(бывет нескольких типов), котор мож. быть на неважно какой технике
- RISC, CISC – компьютеры
«Суперскалярная архитектура», много исполнительных блоков, способных работать параллельно над различными инструкциями (MIMD). (все команды в одном кристале)
Машина, в которой только однотактные команды (сложение, вычитание, логические, регистровые пересылки – всего около 30 команд). Все такие команды зашиты в один кристалл (раньше в кристаллах не умели делать много вентилей (триггеры, элементы Шеффера…)). Умножение, переходы – отдельно (из простых команд). Эти команды редкие Þ не сильно замедляют работу.
Итак, принципы RISC:
1. все команды за один такт
2. все команды одинаковой длины (32 бита) (водопроводу всё равно, он может работать и с командами разной длины);
3. много регистров;
4. программировать для RISC можно только на языке высокого уровня (high-level language).
Программа длиннее, чем на обычных машинах примерно в 2-2.5 раза. RISC программа в 4-5 раз быстрее, чем CISC.
«Скалярная архитектура», за один такт – только одна команда (SIMD).
Предусмотрены команды для всех возможных действий. Выигрыш в памяти, программа проще. Раньше в один кристалл помещалось мало команд
Сейчас в RISC много команд (порядка 256) и нек. Команды не обяз. за один такт
- ITANIUM
Itanium 1,2 (1 – в 2000г)– представители EPIC архитектуры, она же IA64.
Основные посылки Epic:
1. Основана на идеях VLIW
2. Минимизация предсказаний переходов
3. Явное указание //’но исполняемых команд (компилятор объедин.в сязки)
4. Минимизация задержек при доступе к данным, путем обеспечения их равномерной подкачки
Итак рассмотрим отличия Itanium от традиционной x86 архитектуры:
-простые команды одинаковой длины
- Порты:
· 3B – Branch
· 2M – работа с memory
· 2I – c integer
· 2F – c float
-команды идут в связке - шаблон + двумя блоками по 3 команды T,I1,I2,I3 каждая по 40 бит, сотоит из
полей opcode - 14(или 16) B -6, R –7(6),R –7(6),R –7(6)
- тег связки.
Научная MFI MFI, 12 за такт (М-читает(или записыв), F- float I- записывает B-вертится)
Бизнес MII MBB, 8 за такт
-кроме предсказания переходов используется предикатный метод (заводятся однобитовые предикатные регистры и просчитываем несколько веток сразу). То, надо ли условный переход обрабатывать предикатным методом, решает компилятор. (6 бит предикат => 64 парных предикатных регистра. Команды с if else считываются водопровдом без проблем, условию соотв. предикатн. переменная, если ветка if else не нужна, то вместо команды ничего не делаем)
- загрузка данных осуществляется не только по требованию, но и по заявке. Если exception то проверяем не была ли эта data случайно загружена(выполнена) раньше – (?)
Архитектура: [Кеш+TLB(//отвечает за переадресацию страниц)]=>[буфер распределения]=>[3 порта для инструкций ветвления, 2 порта для инструкций работы с памятью, 2 порта для целочисленных инструкций, 2 порта для float инструкций]=>[блок отображения регистров]=>[3 исполнителя переходов (работают с предикатными регистрами – 64шт), 4 целочисленных исполнителя (работают с 128 рег. целых), 2 float исполнителя (+128 float рег.)].
Если результат команды используется непосредственно в качестве операнда для следующей, то он помещается в спец. Быструю память – scouboard.
В Itanium есть конвейер (10 стадий):
1. – фронтальная часть [IPG-генерация счетчика команд][FET-выборка][ROT-вращение(переименование) регистров]
2. – доставка команд [EXP-доп. декодирование][REN-переименов-е рег-ров]
3. – доставка операнда [WLD-декод-е оп-дов][REG-чтение р-ров]
4. – выполнение [EXE-вып-е][DET-опред-е исключ-й][WRB-запись(обратная)]
В Itanium есть не только обычной счетчик переходов, но и счетчик множественного перехода. Используется несколько уровней кеша (16кб + 16кб, 96кб, 4Мб). Используется WriteBack – отложенная запись (сначала пишем в кеш, а потом уже по мере возможности сгружаем в память).
- HLL-компьютеры
В HLL-компьютерах команда if, вызов процедуры, вырезка a[i] осуществляются за одну команду. Правда, это усложняет машину.
Первая такая машина была сделана в СССР Мир-1
1965 – "Мир-1" (академик Глушков). Для "Мир-1" – специальный символьный язык "Аналитик".
1968 – "Мир-3": 100 тыс. опер./сек. Выделена фаза предварительного анализа программы(бинарное дерево)
1970-е – США: "Борроуз", поддерживала Алгол-68, тестирование (к каждому слову – 2 бита, по которым можно было определить, инициализирована переменная или нет).
1970 – СССР: "Эльбрус", тестирование (8 бит), общая архитектура, команды отличались от "Борроуза". В ПВО, первая сбила ракету. (1982 рассекретили) Автокод, Ф32,Ф64; сложение на 16-ти схемах, потом выбирали р-т, но были и команды “+”, ”+цел”, ”+вещ”
iAPX423: должна была делать 10 млн. опер./сек., делала 100 тыс. Семиуровневая адресация, короткая/длинная база/смещение. Все проверки выполнялись, где только можно Þ тормозила.
Люди, применяя дополнительные знания, хитрости, выиграют у транслятора. Но транслятор может сделать глобальную оптимизацию, может обрабатывать большие тексты.
Можно взять одну предметную область и для неё сделать HLL-компьютер. Специализированная машина должна быть сначала хорошей, а потом специализированной.
- Основные принципы построения HLL-машины «Самсон»
Решение: ограничить класс входных языков.(только статические)
Задача ® транслятор ® аппаратура ® результат
То, что сделано на этапе трансляции, перепроверять на аппаратуре не будем. И обратно, что не удобно делать транслятору, должна делать аппаратура. Ограничили класс входных языков статическими языками: Алгол-68, Паскаль, Модула-2, Ада. В таких языках транслятор знает всё о переменных и может сделать то, что потом на архитектуре делать не надо.
Обычно в машинах проверяется переполнение и опустошение стека. В этой машине транслятор гарантирует, что такого не будет(кроме рекурсии – только там проверка), также нет неправильн. Кода операции, непр.использ регистра и т.д. Есть только деление на 0.
От транслятора можно добиться большей надёжности, чем от аппаратуры.
Остаются ошибки типа «деление на 0». Их должна проверять аппаратура, ибо они динамические.
Итоги:
- главная беда старых машин – при их создании не верили в трансляцию;
- транслятор и архитектура должны создаваться в одном коллективе с общей целью.
Адресная шина 24 бита (16 Мб памяти). Позже вернулись к 32 битам (2 Гб памяти).
Реально в программе мы имеем доступ к сегментам. Можно организовать страничную или сегментную память.
Страничная – память выделяется стандартными кусками (проблема – внутренняя фрагментация, т.е. в кусках).
Сегментная – память выделяется произвольными кусками (проблема – внешняя фрагментация, т.е. между занятыми кусками остаются свободные).
В "Самсоне" – сегментная организация памяти, метод граничных маркеров (Copyright Л. Григорьева).
Сегментные регистры, адрес = база + смещение.
Есть как сегменты данных так и сегменты команд.
Память с кодом "read only" можно читать несколькими процессами.
Регистр команд (РК) – текущая исполняемая команда в текущем сегменте.
Ориентация на совершенную польскую запись.
Три стека:
- стек целых;
- стек адресов (каждый элемент указывает на произвольную ячейку памяти);
- стек вещественных.
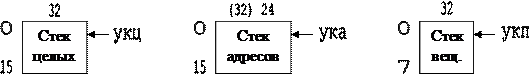 |
Регистр G – адресует глобальные данные.
Регистр L – адресует статику текущей процедуры.
Основной адресуемый элемент – слово.
@ - адрес верхушки стека.
C8 (L/G) – 8-ибитовое смещение
C16 (L/G) – 16-и битовое смещение
Итого шесть типов адресации.
Младший бит смещения указывает относительно L оно или G.
Тогда остаётся только четыре принципиально разных типа адресации. В водопроводе сразу определяется, L или G.
Стек – аппаратный регистр, сидящий внутри процессора.
Главная часть транслятора – глобальная оптимизация регистров.
40% команд в программе – чтение, ещё 40% - переходы. На каждые 4 чтения – одна запись.
Чтение: Ч адр (ЧС8, ЧС16, Ч@, Ч@8)
Запись: П адр (ПС8, ПС16, П@, П@8)
ЧН – непосредственный операнд. Ч0, Ч1 – на верхушку стека целых 0, 1.
ЧУС4 – укороченное чтение.
Для часто используемых команд – короткий код команды. Для редко используемых добавляем несколько битов – не жалко.
- Организация памяти
Адресная шина 24 бита (16 Мб памяти). Позже вернулись к 32 битам (2 Гб памяти).
Реально в программе мы имеем доступ к сегментам. Можно организовать страничную или сегментную память.
У каждого процесса в Самсоне есть сегмент данных, так и сегмент кода.
|G -(шапка)-|---(сегмент данных)--------L-------------|
|IR-(шапка)-|---(сегмент кода)-----------PC------------|
//PC-указатель на текущую команду
//IR-указатель на начало сегмента кода данного процесса
//G – указатель на глобальные данные процесса
//L – указатель на локальные данные процедур процесса (статика процедур)
Страничная – память выделяется стандартными кусками (проблема – внутренняя фрагментация, т.е. в кусках).
Сегментная – память выделяется произвольными кусками (проблема – внешняя фрагментация, т.е. между занятыми кусками остаются свободные).
В "Самсоне" – сегментная организация памяти, метод граничных маркеров (Copyright Л. Григорьева).
Метод граничных маркеров – храним списки свободных/занятых сегментов с 2-мя словами по бокам (длина куска, + => свободен, - => занят), при выгрузке сливаем куски. При выделении памяти применяем стандартные методы поиска первого подходящего куска, либо минимально подходящего, либо откусываем от большого.
Есть как сегменты данных так и сегменты команд.
Память с кодом "read only" можно читать несколькими процессами.
Регистр команд (РК) – текущая исполняемая команда в текущем сегменте.
Есть три стека:
- стек целых;
- стек адресов (каждый элемент указывает на произвольную ячейку памяти);
- стек вещественных.
|
Основной адресуемый элемент – слово (16 бит).
4 типа адрессации:
а) Статическая $8/$16 и L/G
б) Динамическая
@ - по адресу, взятому с верхушки адр. стека
@8 - по адресу, взятому с верхушки адр. Стека + сдвинулись по 8-бит смещ
- Команды чтения-записи
Ч$8, Ч$16, Ч@, Ч@8 - пометка о L/G в младш.бите, так как адр. четные
ЧБЛ8, ЧБГ8, ЧБЛ16, ЧБГ16 – читает байт, в старший байт ставит пометку – L или G
Аналог. с записью: П (+еще 4 вар), ПБЛ, ПБГ – снимаем одну позицию стека в память.
Команды кодируются так [КОП][С8 или С16]
Чтение: Ч адр (ЧС8, ЧС16, Ч@, Ч@8)
Запись: П адр (ПС8, ПС16, П@, П@8) (?)
У обычной процедуры локальных данных обычно около 10. Значит С8 – много, Тогда введем ЧУС4 – однобайтовая команда, Можно сделать и ЧУ С0,С1,С2 – читаем от регистра L со смещением.
Можно читать и константы:
ЧКОН – 16 бит
ЧКБ+, ЧКБ- (8 бит) - берем + и – константы
80% всех констант = 0 или 1, значит делаем Ч0, Ч1– на верхушку стека целых 0, 1.
Для вещественных чисел команды аналогичны (ЧП, ЧУП, ПП, ЧКОНП) и т.д.
Команды писать из стека в память:
П АД, П Ц4, ПУ С4, аналогично для плав и для адр.
- Арифметические команды
+ - сложение двух целых со стека целых
-, *, /, ОСТ – аналогично (ВНИМАНИЕ: /-деление нацело)
вид: Р+, РОСТ…(т.е. один операнд в регистре, а др. в память, адр. Идет за командой)
П+, П-, П*, П/ - с плавающей точкой
Также СДВИГ, ЭЛЕМ, БИТ, НЕ, ИЛИ
Для некоммут. операций обратные аналоги типа /П обр
Команды +:= -:= *:= /:= ОСТ:= ИЛИ:=
НЕЧЕТ, ИНД, ДЕК, -1, АБС, ЗНАК, ОКР, ВЕЩ,, ЦЕЛ, -1П, АБСП, ЗНАКП(плав)
- Логические команды
Логические команды: И(в смысле +), ИЛИ…
Пример: a/\b\/c/\d
Чa
Чb
И
Чc
Чd
И
ИЛИ
Можно использовать и операторы сравнения (сравнивается верхушка с подверхушкой стека и на стек кладется 0 или 1). Важен только последний бит, отрицание - НЕ1
Вычисл. Логич выраж по Маккарти (вычисл. только одна часть имеет смысл в if, но дольше работает при присваивании)
- Передача управления