 2014-02-18
2014-02-18 1166
1166Наиболее простая и распространенная стратегия распределения памяти – смежное распределение памяти – распределение памяти для пользовательских процессов в одной смежной области памяти. Основная пмять разбивается на две смежных части (partitions), которые "растут" навстречу друг другу: резидентная часть ОС и вектор прерываний – по меньшим адресам, пользовательские процессы – по адресам. Для пользовательских процессов память распределяется в одном и том же смежном участке памяти. Для каждого процесса регистр перемещения указывает на начало выделенной ему области памяти, регистр границы содержит длину диапазона логических адресов. Каждый логический адрес должен быть меньше содержимого регистра границы. Физический адрес вычисляется аппаратно как сумма логического адреса и значения регистра перемещения. Схема адресации с аппаратной поддержкой регистров перемещения и границы изображена на рис. 16.2.
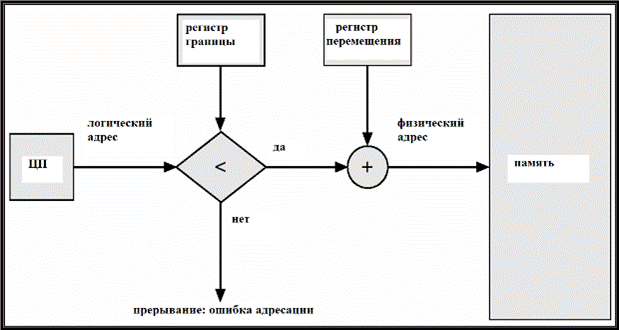
увеличить изображение
Рис. 16.2. Адресация с аппаратной поддержкой регистров перемещения и границы.
Общая задача распределения памяти и стратегии ее решения
В общем случае, в операционных системах может использоваться смежное распределение памяти в нескольких смежных областях. Свободная область – это смежный блок свободной памяти. Свободные области могут быть произвольно разбросаны по памяти. При загрузке процесса ему предоставляется память из любой свободной смежной области, которая достаточно велика для его размещения. При этом операционная система хранит список свободных областей памяти и список занятых областей памяти. Все эти области могут быть произвольно расположены в памяти и иметь различную длину.
Возникает общая задача распределения памяти: Имеется список свободных областей памяти и список занятых областей разного размера. Разработать и реализовать оптимальный (по некоторому критерию) алгоритм выделения свободного смежного участка памяти длины n (слов или байтов).
Для решения данной задачи применяются следующие стратегии: метод первого подходящего (first-fit), метод наиболее подходящего (best-fit) и метод наименее подходящего (worst-fit). Рассмотрим каждую из них подробнее.
Метод первого подходящего: Выбирается первый по списку свободный участок подходящего размера (не меньшего, чем n). На первый взгляд, данная стратегия оптимальна, но далее мы увидим, что это не всегда так.
Метод наиболее подходящего: Выбирается из списка наиболее подходящий свободный участок (минимального размера, не меньшего, чем n). В отличие от предыдущего метода, требует просмотра всего списка, если список не упорядочен по размеру областей. Применение метода приводит к образованию оставшейся части самого маленького размера.
Метод наименее подходящего: Выбирается из списка подходящая область наибольшего размера. Почему наибольшего? Чтобы избежать фрагментации (проблема фрагментации подробно рассмотрена далее в данной лекции).
Применение первой и второй стратегий лучше со следующих точек зрения: скорость выполнения и минимальность объема использованной памяти. Однако их применение может создать фрагментацию.








