 2014-02-24
2014-02-24 1852
1852Реляционная модель данных (РМД)
Иерархическая модель данных (ИМД)
Сетевая модель данных (СМД)
Сетевая модель позволяет организовывать БД, структура которых представляется графом общего вида (пример СМД – на рис. 2.4). Организация данных в сетевой модели соответствует структуризации данных по версии CODASYL. Каждая вершина графа хранит экземпляры сущностей (записи одного типа) и сведения о групповых отношениях с сущностями других типов. Каждая запись может хранить произвольное количество значений атрибутов (элементов данных и агрегатов), характеризующих экземпляр сущности. Для каждого типа записи выделяется первичный ключ – атрибут, значение которого позволяет однозначно идентифицировать запись среди экземпляров записей данного типа.
Связи между записями в СМД выполняются в виде указателей, т.е. каждая запись хранит ссылку на другую однотипную запись (или признак конца списка) и ссылки на списки подчинённых записей, связанных с ней групповыми отношениями. Таким образом, в каждой вершине записи хранятся в виде связного списка. Если список организован как однонаправленный, запись имеет ссылку на следующую однотипную запись в списке; если список двунаправленный – то на следующую и предыдущую однотипные записи.
Групповые отношения характеризуются следующими признаками:
- Способ упорядочения подчинённых записей
Поддерживаются три способа упорядочения:
- Очередь – добавление в конец списка (FIFO – first input, first output).
- Очередь – добавление в конец списка (FIFO – first input, first output).
- Сортировка по значению ключа. При этом задаётся ключев Очередь – добавление в конец списка (FIFO – first input, first output).
- ое поле (группа полей), и вновь поступившая запись добавляется в упорядоченный список в соответствии со значением этого поля (значением ключа).
- Режим включения подчинённых записей.
Режим включения бывает автоматический и ручной.
При автоматическом режиме подчинённая запись связана с записью-владельцем обязательной связью, поэтому она включается в групповое отношение и прикрепляется к записи-владельцу в момент внесения в БД. (Из этого следует, что запись-владелец должна быть внесена в базу данных до внесения первого экземпляра подчинённой записи.)
При ручном режиме включения подчинённая запись может находиться в БД и не быть прикрепленной к записи-владельцу. Она вручную включается в групповое отношение тогда, когда это отношение (связь) возникает.
- Режим исключения подчинённых записей
Режим исключения определяется классом членства. Различают три класса членства – фиксированный, обязательный и необязательный:/p>
- Записи с обязательным членством должны быть удалены до удаления записи–владельца: владелец, к которому прикреплена хотя бы одна запись с обязательным членством, не может быть удалён.
- Записи с фиксированным членством удаляются вместе с записью–владельцем.
- Записи с необязательным членством при удалении записи–владельца останутся в БД.
Рассмотрим фрагмент БД "Предприятие" (рис. 2.5). Здесь записи типов ОТДЕЛЫ и ОРГАНИЗАЦИИ-ЗАКАЗЧИКИ являются владельцами записей типа ПРОЕКТЫ и они связаны групповыми отношениями соответственно выполняют и заказывают. Записи типов ОТДЕЛЫ и ПРОЕКТЫ являются владельцами записей типа СОТРУДНИКИ и они связаны групповыми отношениями работают и выполняются. Записи типа СОТРУДНИКИ являются владельцами записей типа ДЕТИ.
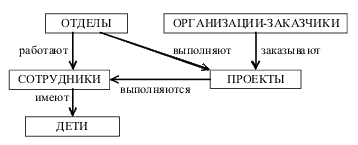
Рис. 2.5. Пример фрагмента сетевой БД "Предприятие"
Групповые отношения чаще всего описывают связь "один-ко-многим": один владелец, много подчинённых. Например, отношение работают подразумевает, что каждый сотрудник работает в одном отделе, но в каждом отделе могут работать несколько сотрудников. С другой стороны, групповое отношение выполняются отражает связь "многие-ко-многим": каждый сотрудник может участвовать в выполнении нескольких проектов, каждый проект могут выполнять несколько человек. Что касается классов членства подчинённых записей, то связь "сотрудники–дети" относится к фиксированному классу членства, связь "сотрудники–проекты" – к необязательному, а все остальные – к обязательному классу членства. Режим включения для связи "сотрудники–проекты" ручной, для всех остальных – автоматический.
В СМД связи 1:n между разными сущностями реализуются с помощью групповых отношений, а связи 1:n между атрибутами сущности – в рамках записи. Для реализации связей типа n:m вводится вспомогательный тип записи и две связи 1:n.
В СМД применяются следующие операции над данными:
- запомнить: внесение информации в БД;
- включить в групповое отношение: установление связей между данными;
- переключить: переход члена набора к другому владельцу;
- обновить: модификация данных;
- извлечь: чтение данных;
- удалить: физическое или логическое удаление данных;
- исключить из группового отношения: разрыв связей между данными.
В сетевой модели данных предусмотрены специальные способы навига-ции и манипулирования данными. Аппарат навигации в графовых моделях служит для установления тех записей, к которым будет применяться очередная операция манипулирования данными. Такие записи называются текущими. В СМД возможны переходы:
- от текущего экземпляра записи определённого типа к следующему экземп-ляру записи этого же типа;
- из текущей вершины в любую вершину, с которой текущая связана групповым отношением.
Навигация в СМД может начинаться с любой записи.
Наиболее распространенной и стандартизованной из реализаций СМД является модель CODASYL. В соответствии с ней описание схемы БД осуществляется на языке COBOL, а манипулирование данными – с помощью включающего языка программирования высокого уровня. Примером се-тевой СУБД является система Integrated Database Management System (IDMS).
СМД является наиболее полной с точки зрения реализации различных типов связей и ограничений целостности, но она является достаточно сложной для проектирования и поддержки. В этой модели не обеспечивается физическая независимость данных, т.к. наборы организованы с помощью физических ссылок. Также в СМД не обеспечивается независимость данных от программ. Из-за этих недостатков эта модель не получила широкого распространения.
Иерархическая модель позволяет строить БД с иерархической древовидной структурой. Структура ИМД описывается в терминах, аналогичных терминам сетевой модели данных (версия CODASYL). Группу в ИМД принято называть сегментом. В основе ИМД лежит понятие дерева.
Дерево – это связный неориентированный граф, который не содержит циклов. При работе с деревом выделяют какую-то конкретную вершину, определяют её как корень дерева и рассматривают особо – в эту вершину не заходит ни одно ребро. В этом случае дерево становится ориентированным, ориентация определяется от корня. Дерево как ориентированный граф определяется так:
- имеется единственная особая вершина, называемая корнем, в которую не заходит ни одно ребро;
- во все остальные вершины заходит только одно ребро, а исходит произвольное количество ребер;
- граф не содержит циклов.
Конечные вершины, то есть вершины, из которых не выходит ни одной дуги, называются листьями дерева. Количество вершин на пути от корня к листьям в разных ветвях дерева может быть различным.
В иерархических моделях данных используется ориентация древо-видной структуры от корня к листьям. Графическая диаграмма концептуальной схемы базы данных называется деревом определения. Пример иерархической базы данных приведён на рис. 2.6. Каждая некорневая вершина в ИМД связана с родительской вершиной (сегментом) иерархическим групповым отношением. Каждая вершина дерева соответствует типу сущности ПО. Тип сущности характеризуется произвольным количеством атрибутов, связанных с ней отношением 1:1. Атрибуты, связанные с сущностью отношением 1:n, образуют отдельную сущность (сегмент) и переносятся на следующий уровень иерархии. Реализация связей типа n:m не поддерживается.
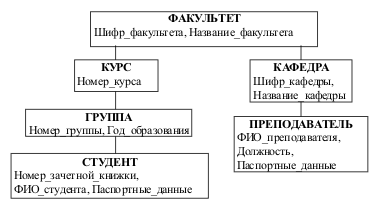
Рис. 2.6. Пример фрагмента иерархической базы данных
Тип вершины определяется типом сущности и набором её атрибутов. Каждая вершина дерева хранит экземпляры сущностей – записи. Следствием внутренних ограничений иерархической модели является то, что каждому экземпляру зависимой группы в БД соответствует уникальное множество экземпляров родительских записей – по одному экземпляру (записи) каждого типа вершин вышестоящих уровней.
По сравнению с СМД иерархическая имеет ограниченный набор режимов включения и исключения подчинённых записей. Это определяется обязательностью связей: в дереве не может быть «висячих» вершин, не связанных с вершиной верхнего уровня (кроме корневой). Поэтому ИМД не поддерживает необязательный класс членства и ручной режим включения записей.
В ИМД предусмотрены специальные способы навигации. Передвижение по дереву всегда начинается с корневой вершины, от которой можно перейти на конкретный экземпляр записи любой вершины следующего уровня. Эта вершина становится текущей вершиной, а экземпляр – текущей записью. От этой записи можно перейти к другой записи данной вершины, к экземпляру записи родительской вершины или к экземпляру записи подчинённой вершины. Т.о., попасть в любую вершину можно, только проделав полный путь по дереву от корня. Связи между записями в ИМД обычно выполнены в виде ссылок (т.е. хранятся адреса связанных записей).
Корневая запись дерева должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальные значения только в экземплярах групповых отношений, т.е. на одном и том же уровне иерархии в разных ветвях дерева могут быть экземпляры записей с одинаковыми ключами. Это объясняется тем, что каждая запись идентифицируется полным сцепленным ключом, который образуется путём конкатенации всех ключей экземпляров родительских записей. Например, для студента (рис. 2.6) ключ – это (Шифр_факультета+Номер_курса+Номер_группы+Номер_зачётной_книжки).
Основным недостатком ИМД является дублирование данных. Оно вызвано тем, что каждая сущность (атрибут) может относиться только к одной родительской сущности. Например, если в БД хранятся данные о детях сотрудников, а на предприятии работает и отец, и мать ребёнка, то сведения об этом ребёнке нужно хранить дважды. Аналогичная ситуация возникает, если нужно отразить в БД связь «многие-ко-многим». Дублирование данных может вызвать нарушение логической целостности БД при внесении изменений в эти данные.
Если данные имеют естественную древовидную структуризацию, то ис-пользование иерархической модели данных не вызывает проблем. Но на практике часто требуется реализовать структуры данных, отличные от иерархической. Для решения этих задач конкретные СУБД, основанные на ИМД, включают дополнительные средства, облегчающие представление произвольно организованных данных.
В качестве примера типичного представителя иерархических СУБД можно привести систему IMS (Information Management System, IBM).
Сетевая и иерархическая модели данных относятся к базам данных I-го поколения (60-е – начало 70-х гг. XX века). Эти модели не смогли в полной мере реализовать независимость данных от программ. Из-за особенностей их организации структура запросов к данным в таких системах определяется наличием связей между записями.
Следующее, II-е поколение баз данных основано на реляционной модели.
Реляционная модель данных была предложена в 1970 г. математиком Эдгаром Коддом (Codd E.F.). РМД является наиболее широко распространенной моделью данных и единственной из трёх основных моделей данных, для которой разработан теоретический базис с использованием теории множеств.
Базовой структурой РМД является отношение, основанное на декарто-вом произведении доменов. Домен – это множество значений, которое может принимать элемент данных (например, множество целых чисел, множество дат, множество комбинаций символов длиной N и т.п.). Домен может задаваться перечислением элементов, указанием диапазона значений, функцией и т.д.
Пусть D1, D2,…, Dk – произвольные конечные и не обязательно различ-ные множества (домены). Декартово произведение этих множеств определяется следующим образом:
D1×D2×...×Dk={(d1, d2,...,dk | di Î Di, I=1,...,k)}
Таким образом, декартово произведение позволяет получить все возможные комбинации значений элементов исходных множеств.
Пример. Для доменов D1 = (1, 2), D2 = (A, B, C) декартово произведение D = D1×D2 будет таким: D = {(1,A), (1,B), (1,C), (2,A), (2,B), (2,C)}
| Подмножество декартова произведения доменов называется отношением. |
Отношение содержит данные о сущностях определённого типа. Поясним это на примере. Если построить произведение трёх доменов Должности ('директор', 'бухгалтер', 'водитель', 'продавец'), Оклады (x | 20000?x?80000), Надбавки (1.1, 1.2, 1.3), то мы получим 4*60001*3=720012 комбинаций. Но реально отношение «Штатное расписание» содержит по одной строке на каждую должность, т.е. является именно подмножеством декартова произведения доменов.
Элементы отношения называют кортежами (или записями). Каждый кортеж отношения соответствует одному экземпляру сущности определённого типа. Элементы кортежа принято называть атрибутами (или полями).

