2014-02-24
2014-02-24 4431
4431ROLAP-серверы используют реляционные БД. Основными составляющими таких схем являются ненормализованная таблица фактов (Fact Table) и множество таблиц измерений (Dimension Tables).
Таблица фактов содержит сведения об объектах или событиях, совокупность которых будет анализироваться. Типы фактов могут быть:
· факты, связанные с транзакциями (Transaction facts), основаны на событиях (например, телефонный звонок)
· факты, связанные с моментальными снимками (Snapshot facts), основаны на состоянии объекта (например, банковского счета) в определенные моменты времени (например, объем продаж за день)
· факты, связанные с элементами документа (Line-item facts), основаны на конкретном документе и содержат подробную информацию о его элементах
· факты, связанные с событиями или состоянием объекта (Event or state facts), представляют возникновение события без подробности о нем (факт продажи или ее отсутствия)
Таблица фактов содержит уникальный составной ключ, объединяющий первичные ключи таблицы измерений. При этом как ключевые, так и некоторые не ключевые поля должны соответствовать измерениям гиперкуба. Кроме этого fact table содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные.
Для многомерного анализа пригодны таблицы фактов, содержащие как можно более подробные данные (т.е. соответствующие членам нижних уровней иерархии измерений).
Таблицы измерений содержат неизменяемые или редко изменяемые данные. Часто это – по одной записи для каждого члена нижнего уровня в иерархии содержат одно описательное поле (имя члена измерения) и целочисленное ключевое поле.
Если измерение, соответствующее таблице, содержит иерархию, то такая таблица может содержать поля, указывающие на «родителя» данного члена в этой иерархии. Каждая таблица измерений должна находится в отношении1:М с таблицей фактов.
Скорость роста таблиц измерений должна быть незначительна по сравнению со скоростью роста таблицы фактов (новая запись в таблице измерений – «товары»; только при появлении нового товара).
При большом числе независимых измерений необходимо поддерживать множество таблиц фактов, соответствующих каждому возможному сочетанию выбранных в запросе измерений.
Увеличение числа таблиц фактов в базе данных является следствием: (а) множественности уровней различных измерений; (б) факты имеют разные множества измерений. Поэтому, необходимо поддерживать множество таблиц фактов, соответствующих каждому возможному сочетанию выбранных в запросе измерений. Это также приводит к неэкономному использованию внешней памяти, увеличению времени загрузки данных в БД схемы звезды из внешних источников и сложностям администрирования. Частично решают эту проблему расширения языка SQL (операторы "GROUP BY CUBE", "GROUP BY ROLLUP" и "GROUP BY GROUPINGSETS"). Также, рекомендуется создавать таблицы фактов не для всех возможных сочетаний измерений, а только для тех, значения ячеек которых не могут быть получены с помощью последующей агрегации более полных таблиц фактов.
Таким образом, если многомерная модель реализуется в виде реляционной базы данных, следует создавать длинные и "узкие" таблицы фактов и сравнительно небольшие и "широкие" таблицы измерений. Таблицы фактов содержат численные значения ячеек гиперкуба, а остальные таблицы определяют содержащий их многомерный базис измерений. Часть информации можно получать с помощью динамической агрегации данных, распределенных по незвездообразным нормализованным структурам.
Достоинства:
· Анализ производится непосредственно над данными хранилища (т.к. большинство корпоративных хранилищ реализуются средствами РСУБД).
· Позволяют динамически изменять структуру измерений без физической реорганизации БД.
· Т.к. основная нагрузка при вычислении на сервере, где выполняются сложные аналитические SQL-запросы, то меньше требования к клиентским установкам.
· Более высокий уровень защиты прав доступа
· Возможность работы с очень большими базами.
Недостатки:
· Ограничения функциональных значений.
· Меньшая производительность.
· Если факты имеют разные множества измерений, их удобнее хранить в нескольких таблицах. Кроме того, в разных запросах пользователей может интересовать только часть возможных измерений. Это приводит к неэкономному использованию внешней памяти, увеличению времени загрузки данных в БД схемы «звезда» из внешних источников и сложностям администрирования. Для преодоления этого можно использовать специальное расширение для SQL (оператор GROUP BY CUBE и ключевое слово ALL) и создавать таблицы фактов не для всех возможных сочетаний измерений, а для тех, значения которых не могут быть получены с помощью последующей агрегации ячеек других таблиц фактов.
В любом случае следует создавать длинные и «узкие» таблицы фактов и сравнительно небольшие и «широкие» таблицы измерений.
Распространены две основные схемы реализации многомерного представления данных с помощью реляционных таблиц: схема «звезда» и «снежинка».
Схема "звезда"
В классическом варианте, типа "звезда" (star schema) предполагает наличие одной большой ненормализованной фактологической таблицы, с которой соотнесено несколько относительно небольших справочных таблиц. Идея заключается в том, что имеются таблицы для каждого измерения, а все факты помещаются в одну таблицу, индексируемую множественным ключом, составленным из ключей отдельных измерений. Каждый луч схемы звезды задает, в терминологии Кодда, направление консолидации данных по соответствующему измерению.
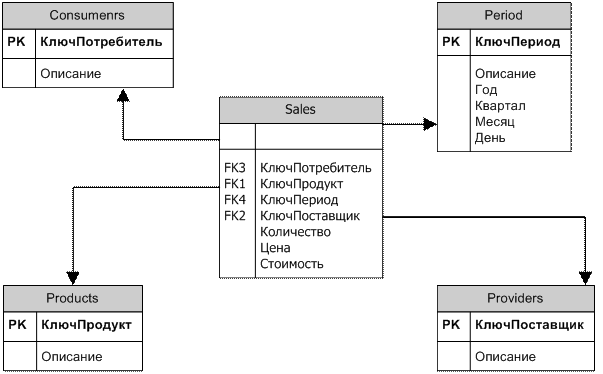
Рис. 5.1. Пример схемы "звезда"
Схема "снежинка"
Схема "созвездие"(fact constellation schema) и схема "снежинка"(snowflake schema). Используется в сложных задачах с иерархическими измерениями. Здесь отдельные таблицы фактов создаются для возможных сочетаний уровней обобщения различных измерений. Это позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных.
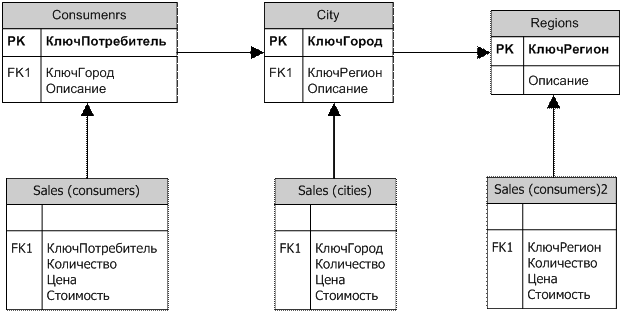
Рис. 5.2. Пример схемы "снежинка" (фрагмент для двух измерений)
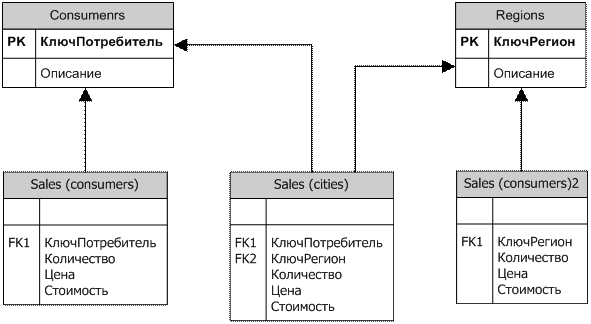
Рис. 5.3. Таблицы фактов для разных сочетаний измерений в запросе