 2014-02-24
2014-02-24 493
493Таблица 2
| Пункты шкалы | Обследуемые всего, N-50 чел. | Итог по строке | ||||||
| А | В | В | Г | ...n | (+) | (-) | % совпадений | |
| + | + | - | + | + | ||||
| + | - | + | + | + | б | |||
| - | + | - | - | - | ||||
| + | + | + | - | + | ||||
| Б | + | + | + | - | + | |||
| в | + | + | - | + | + | |||
| + | + | - | + | + | ||||
| Итог по (+) колонке (-) | 10 5 | 13 2 |
Чтобы устранить такой дефект, используют контрольную группу (см. гл. 5, С. 357—361). Простейший же способ снять влияние установки первого замера — производить повторный замер спустя достаточное время после первого (например, две недели) и на достаточно большой выборке испытуемых (около 50 человек). Составив таблицу замеров для всех обследуемых, мы далее анализируем, какова общая устойчивость данных и от чего зависят отклонения между двумя замерами (табл. 2, пример Г. И. Саганенко).
При повторных измерениях используют различные оценки устойчивости данных, одна из которых — это процент полных совпадений ответов на серию вопросов в двух последовательных пробах методики. Соответствующая формула:
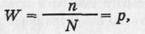
где в числителе п — количество полностью совпавших пар ответов, а в знаменателе Л7 — общая численность испытуемых, р — процент устойчивости.
По этой формуле, для примера, в табл. 2 получим:
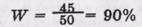 . полной устойчивости исходных данных. Однако ее можно повысить, заменив некоторые пункты, в частности пункт 3. по которому обнаружен наибольший разброс (всего лишь 50% совпадений). Основной критерий устойчивости информации — анализ данных по отроке. Если анализировать эти итоги по колонкам, найдем, что некоторые субъекты (В и Г особенно) дали большой разброс, а некоторые (А и Б) — почти не дали разброса. Те пункты шкалы, в которых обнаружено несовпадение даже у весьма "устойчивых" субъектов, должны быть переформулированы.
. полной устойчивости исходных данных. Однако ее можно повысить, заменив некоторые пункты, в частности пункт 3. по которому обнаружен наибольший разброс (всего лишь 50% совпадений). Основной критерий устойчивости информации — анализ данных по отроке. Если анализировать эти итоги по колонкам, найдем, что некоторые субъекты (В и Г особенно) дали большой разброс, а некоторые (А и Б) — почти не дали разброса. Те пункты шкалы, в которых обнаружено несовпадение даже у весьма "устойчивых" субъектов, должны быть переформулированы.








