 2014-02-24
2014-02-24 771
771При использовании префиксных кодов возникает вопрос о том, каковы возможные длины кодовых комбинаций префиксного кода. Пусть a1, a2,..., aN - кодовые комбинации префиксного двоичного кода. Пусть nk -число кодовых комбинаций длины k. Число nk совпадает с числом вершин k-го уровня кодового дерева. Конечно справедливо неравенство nk £ 2k, поскольку 2k - максимально возможное число вершин на k-м уровне двоичного дерева. Однако для префиксного кода можно получить гораздо более точную оценку. Если n1, n2,..., nk-1 - число вершин 1-го, 2-го,..., (k-1)-го уровней дерева, то число всех вершин k-го уровня кодового дерева префиксного кода равно 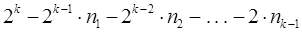 , и поэтому
, и поэтому 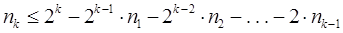 , или иначе
, или иначе 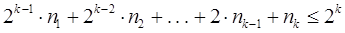 .
.
Деля обе части неравенства на 2k,получим 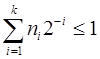 . Это неравенство справедливо для любого k£L, где L - максимальная длина кодовых комбинаций
. Это неравенство справедливо для любого k£L, где L - максимальная длина кодовых комбинаций 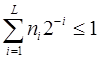 . Если обозначить l1, l2,..., lN длины кодовых комбинаций a1, a2,..., aN, то последнее неравенство можно записать следующим образом
. Если обозначить l1, l2,..., lN длины кодовых комбинаций a1, a2,..., aN, то последнее неравенство можно записать следующим образом 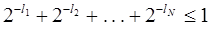 .
.
Это и есть условие, которому должны удовлетворять длины кодовых комбинаций двоичного префиксного кода. Это неравенство в теории кодирования называется неравенством Крафта и является достаточным условием того, что существует префиксный код с длинами кодовых комбинаций l1, l2,..., lN.
Если кодовый алфавит содержит не два, а S символов, то подобным же образом доказывается, что необходимым и достаточным условием для существования префиксного кода является выполнение неравенства 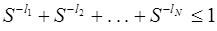 .
.
Эффективное кодирование направлено на устранение избыточности, вызванной неравной априорной вероятностью символов источника. Устранение избыточности, обусловленной наличием корреляции между символами, основано на переходе от кодирования отдельных символов источника к кодированию групп этих символов, то есть происходит укрупнение алфавита источника.
Общая избыточность при укрупнении алфавита не изменяется. Это вызвано тем, что уменьшение избыточности, обусловленной взаимными связями между символами, сопровождается соответствующим возрастанием избыточности, обусловленной неравномерностью появления различных групп символов, то есть символов нового укрупненного алфавита. Таким образом, происходит конвертация одного вида избыточности в другой.
Сжатие бывает с потерями и без потерь при восстановлении. В системах передачи данных используются только методы сжатия без потерь.
Эти методы подразделяются на несколько основных групп:
1. Кодирование повторов. Суть метода состоит в замене последовательности одинаковых повторяющихся символов на один такой символ и число, соответствующее количеству его повторений.
2. Вероятностные методы сжатия. Основу этих методов составляют алгоритмы Шеннона – Фано и Хаффмена. Существуют две разновидности вероятностных методов, различающихся способом определения вероятности появления каждого символа:
а) статические, использующие фиксированную таблицу частоты появления символов, рассчитываемую перед началом процесса сжатия. Статические методы характеризуются хорошим быстродействием и не требуют значительных ресурсов оперативной памяти. Они нашли широкое применение в различных программах- архиваторах, но для сжатия данных, передаваемых модемами, используются редко, поскольку в них предпочтение отдается методам словарей, обеспечивающим большую степень сжатия.;
б) динамические или адаптивные, в которых частота появления символов все время меняется и по мере считывания нового блока данных происходит перерасчет начальных значений частот символов.
Комбинация методов кодирования повторов и адаптивного кодирования с применением кода Хаффмена используется в протоколе MNP5. На перовом этапе процедуры сжатия в соответствии с этим протоколом каждая группа из трех и более (до 253) одинаковых смежных символов преобразуется к виду символ и число символов. На втором этапе используется адаптивное кодирование с применением кода Хаффмена. В протоколе MNP5 определяются 256 лексем для всех возможных 8-разрядных величин – октетов. Лексема состоит из трехразрядного префикса и суффикса, который может включать от 1 до 8 разрядов. Как приемник, так и передатчик инициализируют исходные символьно-лексемные таблицы. После того, как обработан каждый октет передаваемого сообщения, таблица передатчика переопределяется, исходя из частоты появления каждого октета. Октетам, которые появляются чаще, ставятся в соответствие наиболее короткие лексемы. На приемном конце лексемы преобразуются в октеты. В соответствии с частотой появления тех или иных октетов трансформируется символьно-лексемная таблица приемника. Тем самым осуществляется самосинхронизация таблиц кодирования и декодирования.
Протокол MNP5 обеспечивает степень сжатия в среднем 2:1. Более совершенным протоколом, обеспечивающим степень сжатия до 3:1, является протокол MNP7.
Протокол MNP7 использует улучшенную форму кодирования методом Хаффмена в сочетании с алгоритмом прогнозирования, который может предсказывать следующий символ в последовательности, исходя из появившегося предыдущего символа. Для каждого октета формируется таблица из всех 256 возможных следующих за ним октетов, расположенных в соответствии с частотой их появления. Октет кодируется путем выбора столбца, соответствующего предыдущему октету, с последующим отысканием в этом столбце значения текущего октета. Строка, в которой находится текущий октет, определяет лексему так же, как в MNP5. После того, как каждый октет будет закодирован, порядок следования октетов в выбранном столбце изменяется в соответствии с новыми относительными частотами появления октетов.
3. Метод словарей. Наиболее известным и включенным в рекомендации V.42bis алгоритмом данного типа является алгоритм LZW (Lempel – Ziv – Welch), обеспечивающий коэффициент сжатия 4:1 файлов с оптимальной структурой.
Алгоритм LZW построен на основе словаря или таблицы фраз, которая отображает строки символов сжимаемого сообщения в коды фиксированной длины, равные 12 битам.
Таблица обладает свойством предшествования, т.е. для каждой фразы словаря, состоящей из некоторой фразы w и символа K, фраза w тоже содержится в словаре.
Алгоритм LZW работает следующим образом:
1. Инициализировать словарь односимвольными фразами, соответствующими символам входного алфавита. Прочитать первый символ сообщения в текущую фразу w. Текущей фразой на первом шаге алгоритма является пустая фраза.
2. Прочитать очередной символ сообщения K. Если это символ конца сообщения, то выдать код w и закончить работу алгоритма. Если нет, перейти к п.3.
3. Если фраза w K уже есть в словаре, то заменить w на код фразы w K и перейти к п.2.
4. Если фразы w K нет в словаре, то выдать код w в линию и добавить w K в словарь, после чего повторить п.2.
Декодер LZW должен использовать тот же словарь, что и кодер, строя его по аналогичным правилам при восстановлении сжатых данных. Каждый считываемый код разбирается с помощью словаря на предшествующую фразу w и символ K. Затем рекурсия продолжается для предшествующей фразы w до тех пор, пока она не окажется кодом одного символа. При этом завершается декомпрессия этого кода. Обновление словаря происходит для каждого декодируемого кода, кроме первого. После завершения декодирования кода его последний символ, соединенный с предыдущей фразой, добавляется в словарь. Новая фраза получает то же значение кода т.е. позицию в словаре, что присвоил ей кодер. В результате такого процесса, шаг за щагом декодер восстанавливает тот словарь, что построил кодер. Декодирование в алгоритме LZWобычно намного быстрее процесса кодирования.
К параметрам алгоритма, значения которых могут быть согласованы между взаимодействующими модемами, относятся:
- максимальный размер выходного кодового слова;
- общее число кодовых слов;
- размер символа;
- число символов в алфавите;
- максимальная длина последовательности символов.
Кроме того, алгоритм осуществляет мониторинг входного и выходного потоков данных для определения эффективности сжатия. Если сжатия не происходит или оно невозможно в силу природы передаваемых данных, алгоритм прекращает свою работу. Это свойство обеспечивает лучшие рабочие характеристики при передаче файлов, которые уже были сжаты, например, заархивированы, или которые не поддаются сжатию.
Контрольные вопросы к лекции 16
16-1. Что называется сигнально-кодовой конструкцией?
16-2. Что называется энтропией источника сообщений?
16-3. Когда энтропия источника максимальна?
16-4. Когда энтропия источника минимальна?
16-5. В чем состоит суть эффективного кодирования по методу Шеннона – Фано?
16-6. Как строится эффективный код по методу Шеннона – Фано?
16-7. В чем состоит недостаток эффективного кодирования по методу Шеннона – Фано?
16-8. Как строится эффективный код по методу Хаффмена?
16-9. Какие эффективные коды называются префиксными?
16-10. Почему при укрупнении алфавита общая избыточность не меняется?
16-11. Перечислите основные методы сжатия информации без потерь.
16-12. В чем состоит суть метода кодирования повторов?
16-13. Чем статические вероятностные методы сжатия отличаются от динамических?
16-14. Чем протокол сжатия MNP7 отличается от протокола MNP5?
16-15. Что означает свойство предшествования таблицы фраз в алгоритме LZW?
16-16. Какие параметры алгоритма LZW согласовываются между взаимодействующими пользователями?
16-17. С какой целью алгоритм LZW осуществляет мониторинг входного и выходного потоков данных?
Лекция 17. Методы обнаружения ошибок
Сжатие позволяет увеличить пропускную способность систем передачи данных, но если один или несколько битов будут приняты с ошибкой, это может привести к катастрофическим последствиям при восстановлении потока данных. Следовательно, применение методов сжатия данных неразрывно связано с использованием методов обнаружения и исправления ошибок. В качестве примера можно рассмотреть, к чему приводит ошибка в одном бите при использовании наиболее простого метода сжатия – кодирования повторов. Ошибка в одном бите байта, соответствующего повторяемому символу, приводит к восстановлению на приеме соответствующего количества других символов. Ошибка в одном бите байта, соответствующего количеству повторяемых символов, приводит к восстановлению другого количества символов.
Этот простой пример показывает, что последствия ошибки в символе при передаче сжатых данных намного серьезнее, чем при наличии такой же ошибки в случае обычной передачи. Поэтому во всех модемах, выполняющих сжатие данных, имеются встроенные программы, осуществляющие обнаружение и исправление ошибок. Для обеспечения целостности сжимаемых данных эти программы запускаются автоматически, как только модем начинает выполнять сжатие.
Борьба с возникающими при передаче данных по каналу ошибками ведется на разных уровнях семиуровневой базовой эталонной модели взаимодействия открытых систем. Для борьбы с ошибками используется множество различных методов.
Все их можно разделить на две группы: не использующие обратную связь и использующие ее.
В первом случае на передающей стороне данные кодируются одним из известных корректирующих кодов с исправлением ошибок. На приемной стороне производится декодирование принимаемых данных и исправление обнаруженных ошибок. Исправляющая способность применяемого кода зависит от его избыточности. Если вносимая избыточность невелика, то есть опасность того, что принимаемые данные будут содержать необнаруженные ошибки. Если же используется код с высокой исправляющей способностью, т.е. большой избыточностью, то это приводит к существенному снижению реальной скорости передачи данных.
В системах с обратной связью применяются процедуры обнаружения ошибок и переспроса. Такие системы называются системами с решающей обратной связью или системами с автоматическим запросом повторения. В этих системах избыточный код применяется только в режиме обнаружения ошибок. В случае обнаружения ошибки приемная сторона посылает передающей по обратному каналу запрос на повторную передачу. Использование кода только в режиме обнаружения позволяет достичь очень низкой вероятности необнаруженной ошибки (10-6 – 10-12) при сравнительно небольшой избыточности кода.
При передаче данных модемами наибольшее применение нашел второй подход. Иногда (при передаче по каналам очень низкого качества) применяется комбинация обоих подходов, заключающаяся в реализации на передающей стороне сначала кодирования кодом с обнаружением ошибок, а затем кодирования кодом с исправлением ошибок.
Для обнаружения ошибок применяются различные методы:
- посимвольный контроль четности;
- поблочный контроль четности;
- расчет контрольной суммы;
- кодирование циклическим кодом.
Реализация первых трех методов относительно проста. Однако неспособность этих методов выявлять группирующиеся ошибки ограничивает их практическую применимость.
Кодирование циклическим кодом является более мощным средством обнаружения ошибок и применяется на уровне блоков данных. Содержимое кадра, включая служебные, управляющие и информационные поля, представляется в виде полинома и делится на образующий полином используемого циклического кода. В формате кадра выделяется специальное контрольное поле, куда помещается остаток от деления. На приемной стороне выполняется деление содержимого кадра вместе с контрольным полем на тот же образующий полином. Если результат деления на приемной стороне равен некоторому определенному числу (в некоторых системах – нулю), то считается, что передача выполнена без ошибок. Возможны и другие алгоритмы формирования и проверки контрольного поля кадра, однако отличия носят частный характер.
При выборе порождающего полинома руководствуются желаемой разрядностью остатка и его способностью выявлять ошибки. Ряд порождающих полиномов принят в качестве стандартных. Рекомендацией V.41 стандартизирован полином g(x)=x16 +x12 +x5 +1. Другим популярным полиномом является полином g(x)=x16 +x12 +x2 +1. Увеличение числа разрядов контрольного поля кадра позволяет значительно повысить надежность передачи. В связи с этим используется рекомендованный V.42 полином g(x)=x 32 +x26 +x23 +x22 +x16 +x12 +x11 +x10 +x8 +x7+x5 +x4 +x2 +x +1. Находит применение в качестве порождающего и полином g(x)=x12 +x11 +x3 +1. Он применяется в тех случаях, когда для контрольного поля кадра выделяется меньшее число разрядов.
Возможен ряд вариантов механизма переспроса, рассмотренных ранее (глава 3).
По интеллектуальным возможностям модемы можно подразделить на два больших класса: 1) модемы без системы управления; 2) модемы с системой управления, поддерживающей стандартный или фирменный набор команд.
Преобладающее большинство современных модемов относится ко второму из названных классов, т.е. являются интеллектуальными. Эти модемы работают в одном из двух режимов.
В командном режиме модем получает команды от компьютера, которые устанавливают и изменяют условия связи с удаленным модемом. Командный режим устанавливается в следующих случаях:
- при включении питания;
- при первоначальной инициализации модема;
- после неудачной попытки соединения с удаленным модемом;
- при прерывании передачи с клавиатуры путем нажатия комбинации клавиш, соответствующей действию «положить трубку»;
- при выходе из второго режима, называемого режимом передачи, через последовательность команд, называемую ESCAPE-последовательностью.
В режиме передачи модем является прозрачным для команд, которые передаются в канал наряду с другими символами. И только ESCAPE-последовательность символов будет восприниматься модемом как управляющая команда.
В роли стандартов для интеллектуальных модемов в настоящее время выступает набор команд модемов Hayes, называемый также АТ-командами, определяемый рекомендацией V.25bis. Набор АТ-команд обеспечивает возможность:
- выбора поточного или блочного методов обмена с выбором размера кадра;
- выбора режима без коррекции ошибок или с коррекцией ошибок с выбором протокола коррекции;
- управления скоростью передачи;
- запрещения или разрешения сжатия данных с выбором протокола сжатия;
- выбор режима – дуплекс, полудуплекс и множество других возможностей.
Так, например, с помощью пары команд можно осуществлять запись и считывание информации, содержащейся в наборе входящих в состав модема S-регистров. Устанавливая определенные значения в определенных разрядах соответствующих регистров можно конфигурировать модем. С помощью этих регистров можно, например, задать:
- количество гудков для автоответа;
- время ожидания повторного гудка;
- время одной попытки соединения, определяющее время, в течение которого должна быть установлена связь с удаленным модемом;
- время определения несущей;
- время ожидания восстановления потерянной несущей;
- параметры режима передачи (асинхронный, синхронный, по коммутируемой или выделенной линии, с выбором источника синхронизации, в качестве которого может задаваться модем пользователя, компьютер или выделение из принимаемой несущей);
- множество других параметров.
В процессе работы модем может информировать компьютер пользователя о текущем состоянии связи и результатах выполнения АТ- команд. Большинство ответов модема зависит от команды и связано с возвратом запрашиваемой информации или сообщением о текущем состоянии модема.
Контрольные вопросы к лекции 17
17-1. Почему при использовании любых алгоритмов сжатия данных особенно актуальной становится проблема защиты от ошибок?
17-2. На какие группы можно разделить все методы борьбы с ошибками?
17-3. Почему в системах передачи данных предпочтение отдается режиму обнаружения, а не исправления ошибок?
17-4. Какие методы используются для обнаружения ошибок?
17-5. На какие группы модемы подразделяются по интеллектуальным возможностям?
17-6. В каких режимах работает интеллектуальный модем?
17-7. Чем характеризуется командный режим работы модема?
17-8. Как осуществляется конфигурирование интеллектуального модема?








