 2014-02-10
2014-02-10 2540
2540Как отмечалось ранее, нейронные сети могут служить универсальным средством аппроксимации в том смысле, что при достаточно разветвленной архитектуре они реализуют широкий класс функций. Как часто бывает, достоинство одновременно является и недостатком. Благодаря способности тонко улавливать структуру аппроксимируемой функции сеть достигает очень высокой степени соответствия на обучающем множестве, и в результате плохо делает обобщения при последующей работе с реальными данными. Это явление называется переобучением. Сеть моделирует не столько саму функцию, сколько присутствующий в обучающем множестве шум. Переобучение присутствует и в таких более простых моделях, как линейная регрессия, но там оно не так выражено, поскольку через обучающие данные нужно провести всего лишь прямую линию. Чем богаче набор моделирующих функций, тем больше риск переобучения. (На рисунке показать типичные проявления переобучения, пример с распознаванием танков).
Объем обучающей выборки
Первое естественное желание состоит в том, чтобы увеличивать число примеров в обучающем множестве. Чем их больше, тем более представительны данные. Как и в любом физическом измерении, увеличение числа наблюдений уменьшает шум. Если имеется несколько измерений одного объекта, сеть возьмет их среднее значение, и это лучше, чем точно следовать одному единственному зашумленному значению.
Однако на практике и, особенно, в приложениях к задачам биологии и медицины невозможно получить такое количество наблюдений, которое было бы желательно в свете положений статистики. Число необходимых примеров резко растет с увеличением сложности моделируемой функции и повышением уровня шума. Более того, доступные нам данные могут иметь все меньшее отношение к делу. Наконец, могут существовать физические ограничения на размер базы данных, например, объем памяти или недопустимо большое время обучения.
Вопросам, связанным с объемом множества образцов и сложностью сети, посвящены многочисленные исследования. В частности было установлено, что на сети с прямой связью, построенной из линейных пороговых функциональных элементов, можно получить правильные обобщения, если объем обучающего множества в несколько раз больше объема сети. Для многослойных сетей общего вида, построенных из сигмоидальных элементов, аналогичное утверждение не имеет места.
Контрольное множество.
Другой способ избавиться от переобучения заключается в том, чтобы измерить ошибку сети на некотором множестве примеров из базы данных, не включенных в обучающее множество, — к онтрольном множестве. Для этого из обучающего множества случайным образом может быть выделено некоторое множество примеров. При этом «обучение» сети производят по прежнему на обучающем множестве, контрольное же множество используют лишь для определения момента переобучения. В случае, когда функция ошибок на обучающем множестве продолжает уменьшаться, а на контрольном не изменяется либо увеличивается, как это показано на рисунке 2, обучение прекращается. Если же объем выборки не позволяет выделить контрольное множество, то может быть использован метод перекрестного подтверждения.
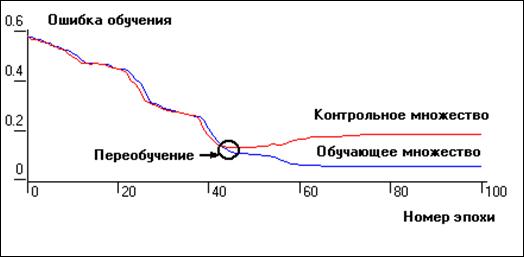 |
Рис.2. Применение контрольного множества для устранения эффекта переобучения нейронной сети.
Регуляризация весов
Еще один способ избежать переобучения состоит в том, чтобы ограничить совокупность функций отображения, реализуемых сетью. Методы такого типа называются регуляризацией. Например, в функцию ошибок может быть добавлено штрафное слагаемое, подавляющее резкие скачки отображающей функции (на математическом языке— большие значения ее второй производной). Алгоритм обучения изменяется таким образом, чтобы учитывался этот штраф.








