 2014-02-10
2014-02-10 364
364Разделение секрета
Ключ разделяется между субъектами так, что восстановить его может только заданное подмножество субъектов.
Схема разделения: для выполнения действия нужна группа субъектов (разделение ответственности)
Хранение секретных ключей.
Совместный контроль модульным сложением
Есть секрет, выбирается модуль, больший этого секрета, хотим разделить между t участниками.
Первым t-1 выдаем случайные числа по модулю m, а последнему:
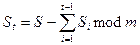
Секрет могут восстановить все участники. Если какое-либо их подмножество соберется, то они не смогут восстановить секрет.
Более сложная схема
t субъектов
s – секрет.
Строим полином и выбираем случайные значения: 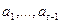
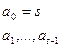
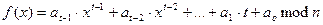
Берем t точек и вычисляем 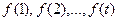
|| || ||
y1 y2 yt
Значение первое – первому участнику u1, t-ое – пользователю ut.
Так как полином степени t-1, то он однозначно восстановим по t точкам, то его могут восстановить t участников.
Последний коэффициент вычисляется следующим образом:

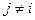
Проверим:
x=xk
При yi: 1.  xk - xj
xk - xj
Встретится xk - xk=0
2. i=k 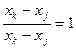
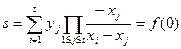
Достоинства:
¾ Если соберется меньше t участников, то они не смогут восстановить секрет.
¾ Идеальная схема – каждый участник имеет минимальное количество информации.
¾ Расширяемость схемы для новых пользователей.
¾ Возможность контроля – различные уровни.
¾ Если пользователю дать больше информации, то его вклад увеличится.
¾ В основе системы нет недоказуемых предположений безопасности.
При анализе данных часто возникает желание вычислить не одно среднее значение по всей выборке, а серию средних значений (плюс стандартных отклонений, стандартных ошибок среднего и т.п.) для различных категорий респондентов. Категории респондентов должны быть записаны в отдельном столбце.
Вычислим, для примера, средние значения количества детей для респондентов различных рас.
Запускаем еще один раздел, который называется «Средние…», или “Means…”:
Анализ à Сравнение средних à Средние… (в русской версии)
Analyze à Compare means à means. (в английской версии).
На экране появится следующее окно:
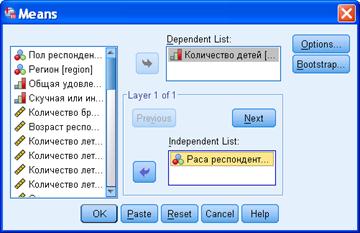
Первым делом указываем, какие переменные обрабатывать. Ту переменную, по которой будут вычисляться средние значения, отправляем в Dependent list. Переменную, коды которой определяют номера групп, отправляем в Independent list – столбец, содержащий номера групп. В нашем случае зависимой переменной окажется количество детей, а независимой – раса респондента.
Еще обычно требуется уточнить статистики, которые будут вычисляться. Для этого нажмем кнопку “Options…” («Параметры…») и отметим нужные статистики в появившемся окне:
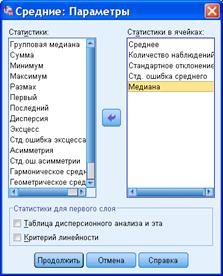
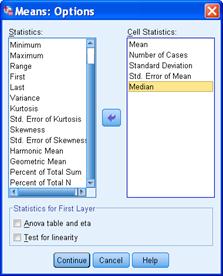
Выбрав статистики, нажимаем «Продолжить» и «ОК». Результат выполнения процедуры будет выглядеть примерно так (английская версия):
| Case Processing Summary | ||||||
| Cases | ||||||
| Included | Excluded | Total | ||||
| N | Percent | N | Percent | N | Percent | |
| Количество детей * Раса респондента | 99,5% | ,5% | 100,0% |
| Report | |||||
| Количество детей | |||||
| Раса респондента | Mean | N | Std. Deviation | Std. Error of Mean | Median |
| Белый | 1,83 | 1,707 | ,048 | 2,00 | |
| Черный | 2,27 | 2,005 | ,141 | 2,00 | |
| Другой | 2,20 | 1,989 | ,284 | 2,00 | |
| Total | 1,90 | 1,765 | ,045 | 2,00 |
Часто требуется найти усредненные параметры не по одной группирующей переменной, а по комбинации нескольких группирующей переменной. Например, требуется найти среднее число детей для различных комбинаций расы и пола (белых мужчин, негритянок, и т.п.). Эту задачу можно также выполнить в процедуре Means (Средние), но группирующие переменные следует задавать по слоям. Если обе переменные (и пол, и расу) поместить на один слой, то мы будем иметь на выходе фактически две похожих по смыслу группы таблиц – каждая для своей переменной. Нам требуется не это. Одну из переменных (например, «раса») поместим в первый слой (как и раньше), затем нажмем кнопку «Следующий» (”Next”) и в новый слой добавим пол. Тогда итоговая таблица примет примерно такой вид:
| Количество детей | ||||||
| Раса респондента | Пол респондента | Mean | N | Std. Deviation | Std. Error of Mean | Median |
| Белый | Мужской | 1,56 | 1,634 | ,070 | 1,00 | |
| Женский | 2,03 | 1,733 | ,065 | 2,00 | ||
| Total | 1,83 | 1,707 | ,048 | 2,00 | ||
| Черный | Мужской | 2,04 | 2,003 | ,241 | 2,00 | |
| Женский | 2,39 | 2,003 | ,174 | 2,00 | ||
| Total | 2,27 | 2,005 | ,141 | 2,00 | ||
| Другой | Мужской | 2,20 | 2,142 | ,479 | 2,00 | |
| Женский | 2,21 | 1,916 | ,356 | 2,00 | ||
| Total | 2,20 | 1,989 | ,284 | 2,00 | ||
| Total | Мужской | 1,64 | 1,702 | ,068 | 1,00 | |
| Женский | 2,09 | 1,785 | ,060 | 2,00 | ||
| Total | 1,90 | 1,765 | ,045 | 2,00 |
Интерпретировать эту таблицу легко, поэтому подробнее на ней мы останавливаться не будем.








