 2014-02-09
2014-02-09 1285
1285Модель поиска текстовой информации характеризуется четырьмя параметрами:
1. представлением документов и запросов;
2. критерием смыслового соответствия;
3. методами ранжирования результатов запроса;
4. механизмами обратной связи, обеспечивающими оценку релевантности пользователем.
Рассмотрим наиболее распространенные модели поиска с позиции первых трех параметров.
Булева модель представляет документы с помощью набора терминов, присутствующих в индексе, каждый из которых рассматривается как булева переменная. При наличии термина в документе соответствующая переменная принимает значение True. Присваивание терминам весовых коэффициентов не допускается. Запросы формулируются как произвольные булевы выражения, связывающие термины с помощью стандартных логических операций: AND, OR или NOT. Мерой соответствия запроса документу служит значение статуса выборки (RSV, retrieval status value). В булевой модели RSV равно либо 1, если для данного документа вычисление выражения запроса дает True, либо 0 в противном случае. Все документы с RSV = 1 считаются релевантными запросу.
Такая модель проста в реализации и применяется во многих коммерческих системах. Она позволяет пользователям вводить в свои запросы произвольные сложные выражения. Однако эффективность поиска обычно невысока. К тому же, ранжировать результаты невозможно, так как все найденные документы имеют одинаковые RSV, а терминам нельзя присвоить весовые коэффициенты.
Нередко результаты выглядят противоестественно. Например, если пользователь указал в запросе десять терминов, связанных логической операцией AND, документ, содержащий девять таких терминов, в выборку не попадет. Для повышения эффективности поиска в ИПС часто применяется обратная связь с пользователем. Как правило, система просит пользователя указать релевантность или нерелевантность нескольких документов, включенных в начало списка вывода. Поскольку результаты не ранжируются, выбор документов для подобной экспертной оценки релевантности затруднен.
Модель нечетких множеств основывается на теории нечетких множеств, допускающей (в отличие от обычной теории множеств) частичную принадлежность элемента тому или иному множеству. Здесь логические операции переопределены таким образом, чтобы учесть возможность неполной принадлежности множеству, а обработка запросов пользователя выполняется аналогично булевой модели. Тем не менее, ИПС на основе подобной модели оказывается практически столь же не способной классифицировать полученные результаты, что и системы, базирующиеся на булевой модели.
Строгая булева модель и модель, использующая методы теории нечетких множеств, требуют меньших объемов вычислений (при индексировании и оценке соответствия документов запросу), чем другие модели. Они менее сложны алгоритмически и предъявляют не очень жесткие требования к другим ресурсам, таким как дисковое пространство для хранения представлений документов.
Пространственно-векторная модель основана на предположении, что совокупность документов можно представить набором векторов в пространстве, определяемом базисом, из n нормализованных векторов терминов. Значение первого компонента вектора представляющего документ отражает вес термина в нем. Запрос пользователя также представляется n-мерным вектором. Показатель RSV, определяющий соответствие документа запросу, задается скалярным произведением векторов запроса и документа. Чем больше RSV, тем выше релевантность документа запросу.
Достоинство подобной модели в ее простоте. Она позволяет легко реализовать обратную связь для оценки релевантности пользователем. В то же время приходится жертвовать выразительностью спецификации запроса, присущей булевой модели.
Вероятностные модели. В пространственно-векторной модели подразумевается, что векторы терминов, ортогональны и существующие взаимосвязи между терминами не должны приниматься во внимание. Кроме того, в такой модели не специфицируется степень соответствия "запрос - документ" и она оценивается достаточно произвольно. Вероятностная модель учитывает все взаимозависимости и связи терминов, а также определяет такие основные параметры, как веса терминов запросови форма соответствия "запрос - документ".
Данная модель базируется на двух главных параметрах: Pr(rel) и Pr(nonrel), т.е. на вероятности релевантности и нерелевантности документа запросу пользователя, которые вычисляются на основе вероятностных весовых коэффициентов терминов и фактического присутствия терминов в документе.
Подразумевается, что релевантность является бинарным свойством, и поэтому Pr(rel) = 1 - Pr(nonrel). Кроме того, в этой модели применяются два стоимостных параметра: al и а2. Они характеризуют соответственно потери, связанные с включением в результат нерелевантного документа и пропуском релевантного документа.
Данная модель требует определения вероятностей вхождения термина в релевантные и нерелевантные части совокупности документов, оценить которые довольно сложно. Между тем она выполняет важную функцию, объясняя процесс поиска и предлагая теоретическое обоснование методов, применявшихся ранее эмпирически (например, введение некоторых систем определения весовых коэффициентов терминов).
Методы введения обратной связи с пользователем
В отличие от среды баз данных в ДИПС нет четкого представления документов и
пользовательских запросов. Пользователи обычно начинают с неточного и неполного запроса, а, следовательно - с низкой эффективности поиска, постепенно уточняя его методом итераций. Система поддерживает обратную связь с пользователем, позволяя тем самым оценить релевантность документов, найденных по первоначальному запросу. Такой подход позволяет повысить эффективность поиска.
Чтобы упростить представление обратной связи, будем считать, что используется пространственно-векторная модель поиска, а пользователю предоставлена возможность просто отметить: релевантен документ или нет.
Множество документов, считающихся релевантными, формируют положительную обратную связь, а множество документов, рассматриваемых как нерелевантные, - отрицательную.
Существуют два основных подхода к использованию такой обратной связи: модификация запроса и модификация представления документов.
Методы, модифицирующие представление запроса, влияют только на текущий сеанс, но никак не сказываются на обработке других запросов. Методы, основанные на модификации представления документов, оказывают влияние и на эффективность поиска в последующих запросах.
Базовое допущение, на которое опирается методология обратной связи, состоит в том, что документы, релевантные некоторому пользовательскому запросу, близки друг к другу в векторном пространстве, т. е. соответствующие векторы в каком-то смысле "похожи" друг на друга. Использование обратной связи в механизмах поиска информации требует более описательного и семантически богатого представления документов, чем то, что получается в результате индексирования лишь названий или рефератов документов. Один из возможных способов - индексирование всего документа. Пространственно-векторную модель нетрудно адаптировать ко всем методам поиска с обратной связью, в то время как вероятностная модель требует специальных расширений.
Модификация представления запроса. Существуют три способа повышения эффективности поиска путем модификации представления запроса. Первый - модификация весов терминов - предусматривает корректировку весов терминов в запросе, осуществляемую путем сложения вектора запроса и векторов, представляющих документы, которые получили положительную оценку (положительную обратную связь). Наряду с этим возможна дополнительная корректировка за счет вычитания векторов, входящих во множество с отрицательной обратной связью.
Переформулированный таким образом запрос должен возвращать дополнительные релевантные документы, аналогичные тем, что попали во множество с положительной обратной связью. Данный процесс можно повторять итерационно до тех пор, пока качество выборки и число документов в ней не достигнут приемлемого уровня.
Результаты экспериментов показывают, что положительная обратная связь более содержательна и эффективна. Причина в том, что документы из множества с положительной обратной связью обычно более однородны, чем формирующие отрицательную обратную связь. Один из эффективных методов использует все документы с положительной обратной связью, но для вычитания из запроса берет только те векторы с отрицательной обратной связью, которые обладают наибольшим рангом нерелевантности.
Второй метод, называемый методом расширения запроса, модифицирует исходный запрос путем добавления к нему новых терминов. Эти термины выбираются из документа с положительной обратной связью и сортируются на основе их весов. К запросу добавляется заранее заданное число терминов из начала отсортированного списка. Эксперименты показывают, что последние три метода сортировки дают наилучшие результаты и добавление ограниченного числа наиболее важных терминов предпочтительнее учета всех терминов. При включении в запрос более 20 дополнительных терминов эффективность практически не увеличивается.
В некоторых случаях представленные два метода не дают удовлетворительного результата. Наличие ошибок 1-го и 2-го рода в реальной системе обуславливает разбиение всего массива документов системы по отношению к запросу на 4 подмассива:
Разбиение массива документов
Выданные Невыданные
Релевантные А С
Нерелевантные В D
А - массив выданных релевантных документов; В - массив выданных нерелевантных документов; С - массив невиданных релевантных документов; D - массив невиданных нерелевантных документов; Введем следующие обозначения: a - количество выданных релевантных документов; b – количество выданных нерелевантных документов; c - количество невиданных релевантных документов; d -количество невыданных нерелевантных документов; Существуют следующие показатели эффективности ДИПС:
1.Коэффициент полноты p, характеризующий долю выданных релевантных документов во всем массиве релевантных документов:
a pa c =+.
2.Коэффициент точности n, характеризующий долю выданных релевантных документов во всем массиве выданных документов:
a na b =+.
3.Коэффициент шума е, характеризующий долю выданных нерелевантных документов во всем массиве выданных документов:
1 b e na b = = -+.
4.Коэффициент осадка q, характеризующий долю выданных нерелевантных документов во всем массиве нерелевантных документов:
b qb d =+.
5.Коэффициент специфичности k, характеризующий долю невиданных нерелевантных документов во всем массиве нерелевантных документов:
d kb d =+.
Часто для удобства перечисленные показатели измеряют в %, т.е. в указанных формулах появляется дополнительный сомножитель 100 %.
При оценке качества реальных систем наиболее часто используются лишь коэффициенты полноты и точности. Ясно, что и точность поиска, и его полнота зависят не только от свойств поисковой системы, но и от правильности построения конкретного запроса, а также от субъективного представления пользователя о том, что такое нужная ему информация. Однако при желании можно вычислить и средние значения полноты и точности для конкретной системы, протестировав ее на эталонной базе документов. Очевидно, хорошая поисковая система должна иметь как можно большие полноту и точность, желательно - 100%, т. е. находить все нужные документы и ни одного лишнего. Однако стопроцентное качество поиска невозможно, потому что на фиксированном уровне мощности поискового средства все попытки улучшить один из этих параметров приводят к ухудшению другого (см. рис. 10.)
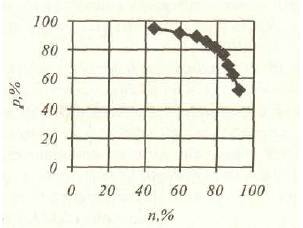
Рис. 10. Пример зависимости между коэффициентами полноты и точности
Наряду с перечисленными показателями, которые основаны на сопряженности релевантности и выдачи, целесообразно использовать также и другие показатели эффективности, что обычно и делается на практике. К основным из них следует отнести:
1. быстродействие ДИПС (интервал времени между моментом формулировки запроса и получением ответа на него);
2. пропускная способность (оценивается количеством вводимых документов и количеством ответов в единицу времени при заданных значениях коэффициентов полноты и точности);
3. производительность (оценивается количеством пользователей системы и частотой обращения с их стороны);
4. надежность работы (оценивается вероятностью того, что система будет выполнять свои функции при заданных условиях в течение требуемого времени); тип запросов, обслуживаемых системой.

