2014-02-13
2014-02-13 589
589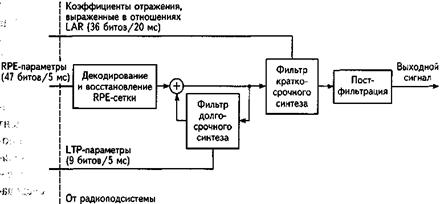 Эти же RPE параметры подаются на блок декодирования и восстановления сетки RPE, который выдает подсегмент LTP -остатка (5). После прибавления отсчетов этого сегмента к приближенным значениям STP -остатка получаются реконструированные отсчеты STP -остатка, которые и направляются на вход фильтра долговременного анализа. В результате фильтрации получается новый подсегмент приближенных значений отсчетов остатка кратковременного предсказания, которые используются при обработке следующего подсегмента. В результате применения алгоритма кодирования 20-мс сегмент речи передается 260 битами информации, т.е. кодер речи осуществляет сжатие информации почти в 5 раз (1280: 260 = 4,92), что обеспечивает цифровую скорость передачи Rц = 64/5 @ 13 кбит/с. На рис.13.2 изображена упрощенная схема RPE-LTP -декодера. Он содержит такой же контур обратной связи, как и кодер.
Эти же RPE параметры подаются на блок декодирования и восстановления сетки RPE, который выдает подсегмент LTP -остатка (5). После прибавления отсчетов этого сегмента к приближенным значениям STP -остатка получаются реконструированные отсчеты STP -остатка, которые и направляются на вход фильтра долговременного анализа. В результате фильтрации получается новый подсегмент приближенных значений отсчетов остатка кратковременного предсказания, которые используются при обработке следующего подсегмента. В результате применения алгоритма кодирования 20-мс сегмент речи передается 260 битами информации, т.е. кодер речи осуществляет сжатие информации почти в 5 раз (1280: 260 = 4,92), что обеспечивает цифровую скорость передачи Rц = 64/5 @ 13 кбит/с. На рис.13.2 изображена упрощенная схема RPE-LTP -декодера. Он содержит такой же контур обратной связи, как и кодер.
Рис. 13.2. Блок-схема RPE-LTP -декодера речи
В случае отсутствия ошибок передачи, выходной сигнал этой части декодера восстанавливает последовательность отсчетов остатка кратковременного предсказания. Затем эти отсчеты направляются на вход STP фильтра-синтезатора, после чего обрабатываются блоком постфильтрации для компенсации предыскажений, внесенных фильтром на входе кодера. Сигнал на выходе блока постфильтрации представляет собой восстановленные фрагменты речевого сигнала.
Кодирование речи с половинной скоростью. В GSM -кодере речи с половинной скоростью используется подход «анализ через синтез», рассмотренный в разделе 12, в версии VSELP. На рис. 13.3 изображена упрощенная блок-схема кодера с половинной скоростью.
Процедура «анализ через синтез» используется для поиска наилучшего кодового слова (вектора), характеризующего сигнал возбуждения для каждого 20-мс сегмента. Такое кодовое слово находится путем применения каждого кодового слова из словаря для возбуждения CELP -синтезатора. Затем синтезированный РС сравнивается с входным сигналом и вычисляется их разность. Разностный сигнал взвешивается спектральным взвешивающим фильтром с характеристикой W(z) и вторичным взвешивающим фильтром C(z). В результате получается сигнал ошибки е(п). Кодовое слово, обеспечивающее наименьшую среднюю мощность сигнала ошибки е(п), выбирается как наиболее точно соответствующее данному сегменту. Характеристики взвешивающего фильтра выбираются таким образом, чтобы обеспечить наилучшее субъективное восприятие синтезируемого РС человеческим ухом. Второй взвешивающий фильтр C(z) контролирует количество ошибок в гармониках речевого сигнала.
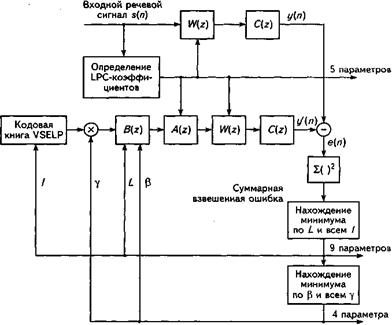
Рис. 13.3. Упрощенная блок-схема GSM -кодера речи с половинной скоростью
A(z) - кратковременный спектральный фильтр; B(z) - долговременный фильтр
с задержкой L
В процессе «анализа через синтез» кодер вычисляет 18 параметров, которые характеризуют каждый 20-мс сегмент. Параметры единичного сегмента представляются 112 битами, что эквивалентно скорости передачи данных 5,6 кбит/с на выходе полускоростного кодера.
Декодер с половинной скоростью представляет собой усечённый вариант кодера. На основе принятых параметров речь генерируется тем же синтезатором, что и в кодере.
При кодировании речи с половинной скоростью количество битов, представляющих 20-мс сегмент, значительно меньше, чем при кодировании с полной скоростью; следовательно, необходим более высокий уровень их защиты в канале передачи. Применение более эффективного канального кодирования приводит к увеличению числа битов в 20-мс сегменте до 228. Это равнозначно скорости потока данных 11,4 кбит/с на выходе канального кодера, что составляет ровно половину скорости на выходе канального кодера, работающего совместно с полноскоростным кодером речи.
Основное преимущество кодера речи с половинной скоростью заключается в удвоении емкости физического канала. Один и тот же временной слот может использоваться чередующимися полускоростными каналами трафика. Внедрение кодирования речи с половинной скоростью связано с попытками обойти проблемы с емкостью системы в густонаселенных районах. Это привело к необходимости внедрить в мобильные телефоны кодеры, которые могут работать с обоими стандартами. Основной недостаток кодирования речи с половинной скоростью - ухудшение качества передачи речи.
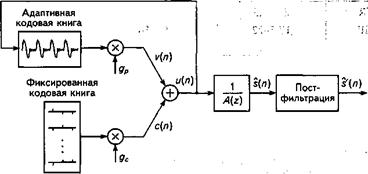 Улучшенноекодирование речи с полной скоростью. В основе такого кодера лежит модель линейного предсказания с кодовым возбуждением(CELP).В этой модели речевой сигнал синтезируется в линейном фильтре синтеза с кратковременным предсказанием (STP) 1/A(z)10-го порядка (рис.13.4). Сигнал u(n) для его возбуждения формируется путем сложения двух векторов возбуждения из адаптивной и фиксированной кодовых книг. LTP -фильтр синтеза реализован с использованием адаптивной кодовой книги. Оптимальный вектор возбуждения ищется в кодовой книге с помощью процедуры «анализ через синтез» - аналогичной той, которая используется в кодировании речи с половинной скоростью.
Улучшенноекодирование речи с полной скоростью. В основе такого кодера лежит модель линейного предсказания с кодовым возбуждением(CELP).В этой модели речевой сигнал синтезируется в линейном фильтре синтеза с кратковременным предсказанием (STP) 1/A(z)10-го порядка (рис.13.4). Сигнал u(n) для его возбуждения формируется путем сложения двух векторов возбуждения из адаптивной и фиксированной кодовых книг. LTP -фильтр синтеза реализован с использованием адаптивной кодовой книги. Оптимальный вектор возбуждения ищется в кодовой книге с помощью процедуры «анализ через синтез» - аналогичной той, которая используется в кодировании речи с половинной скоростью.
Рис. 13.4. Упрощенная блок-схема
GSM-EFR - кодера
Для каждого сегмента (20 мс, 160 отсчетов) определяются такие параметры модели CELP, как коэффициенты фильтра линейного предсказания, адреса в адаптивной и фиксированной кодовой книгах, а также весовые коэффициенты. Затем они кодируются и пересылаются на приемник. Декодер использует принятые параметры для восстановления речевого сигнала в CELP -синтезаторе, идентичном применяемому в передатчике при анализе речи.
EFR-кодер генерирует поток данных со скоростью 13 кбит/с. Тесты показали, что EFR-кодирование позволяет получить намного лучшее качество передачи речи, чем RPE-LTP -коди-рование. Такой тип кодеров в основном используется во вновь разворачиваемых сетях, в частности, в сетях PCS-1900 в Северной Америке.
14. Оценка качества передачи речи
Поскольку человек как получатель информации является ключевым элементом любой телекоммуникационной системы, качество сигнала оценивается по его субъективному восприятию речи. К основным показателям качества принимаемой речи относят: разборчивость (понятность), громкость и натуральность.
Понятность речи - определяющая характеристика тракта передачи речи, так как если тракт не обеспечивает полной понятности речи, то никакие другие его преимущества не имеют значения - он не пригоден к эксплуатации. Для непосредственного определения этой качественной характеристики есть только один метод – субъективно-статистические испытания (ССИ), требующий большого количества речевого материала, обработанного кодеками и трактом передачи, и привлечения группы экспертов (тренированных слушателей и дикторов). Разработан косвенный, объективный количественный метод определения понятности речи через ее разборчивость (см. также раздел 4).
Громкость речи определяет желательный уровень принимаемых сигналов, при котором разборчивость (понятность) речи достигается без напряжения слухового аппарата со стороны принимающего. Натуральность речи оценивает способность системы воспроизводить не только смысл передаваемой речи, но и ее тембр и индивидуальные особенности голосов говорящих, т.е. способность обеспечить узнаваемость говорящего по голосу.
Наиболее распространенным объективным методом оценки качества передачи речи является метод артикуляции. Он основан на оценке степени выполнения главного требования, предъявляемого к разговорным трактам, - обеспечения разборчивой передачи речи. Мерой разборчивости является здесь разборчивость элементов речи. Процесс произнесения речевых элементов называется артикуляцией - отсюда и название метода.
Для измерений разборчивости разработаны специальные (артикуляционные) таблицы слогов, звукосочетаний и слов с учетом их встречаемости в русской речи (аналогичные таблицы есть и для других языков). Звуковых таблиц нет, так как звуки, кроме гласных, отдельно не произносятся, а для измерений звуковой разборчивости пользуются слоговыми таблицами или таблицами звукосочетаний. Пусть, например, в процессе измерения было передано 1200 слогов, из них правильно принято 840 и искажено 360. Тогда слоговая разборчивость составит S = 840´100/1200 = 70%. Из всех типов артикуляционных таблиц (слоговых, словесных, фразовых) практическое применение находят первые две. При этом слоговые артикуляционные таблицы считаются основными, так как на практике в большинстве случаев рассматривается именно слоговая разборчивость.
Измеряют разборчивость экспериментально (в соответствии с ГОСТ 16600-73) с помощью артикуляционной бригады - группы тренированных слушателей и дикторов - молодых людей без нарушений слуха и речи. Ограничение влияния субъективных факторов достигается путем строгой регламентации артикуляционных измерений. Регламентация касается вопросов комплектования и тренировки артикуляционных бригад, порядка проведения передачи, записи и проверки артикуляционных таблиц, обработки результатов измерения разборчивости.
В табл. 14.1 приведены градации понятности речи и соответствующие им величины разборчивости. Словесная разборчивость ниже 75% оценивается как "срыв связи".
| Понятность | Разборчивость, % | |
| слоговая | словесная | |
| Предельно допустимая | 25…40 | 75…87 |
| Удовлетворительная | 40…50 | 87…93 |
| Хорошая | 50…80 | 93…98 |
| Отличная | 80 и выше | 98 и выше |
Эти данные были получены для широкого словаря, т.е. при передаче самой разнообразной информации. В тех же случаях, когда идет обмен информацией с гораздо меньшим объемом (т.е. при ограниченном словаре), понятность речи будет лучше, чем в общем случае при той же разборчивости речи. Так, для диспетчерской связи 40%-ная слоговая разборчивость уже соответствует полной понятности речи, хотя в общем случае она соответствует удовлетворительной понятности. Для передачи цифрами полная понятность достигается при 30% слоговой разборчивости.
По результатам проведения артикуляционных испытаний разборчивости различают классы качества речевых трактов по процентам правильно принятых элементов речи: слабое, удовлетворительное, хорошее и отличное (табл. 14.2).
| Вид разборчи- вости | Качество речевых трактов, % | |||
| Слабое | Удовлетворительное | Хорошее | Отличное | |
| Звуковая | 25...40 | 40...55 | 55...80 | >80 |
| Слоговая | 64...75 | 75...82 | 82...90 | >90 |
| Словесная | 75...87 | 87...93 | 93...98 | >98 |
| Фразовая | 90...95 | 87...93 | 97...99 | >99 |
При оценке качества кодирования и сопоставлении различных кодеков оцениваются разборчивость речи и качество синтеза (качество звучания) речи. За рубежом для оценки разборчивости речи используется метод DRT (диагностический рифмованный тест). В этом методе подбираются пары близких по звучанию слов, отличающихся отдельными согласными в начале слова (типа "дот - тот", "кол - гол"), которые многократно произносятся рядом дикторов, и по результатам испытаний оценивается доля искажений. Метод позволяет получить как оценку разборчивости отдельных согласных, так и общую оценку разборчивости речи.
Для оценки качества звучания используется критерий DAM (диагностическая мера приемлемости). Испытания заключаются в чтении несколькими дикторами, мужчинами и женщинами, ряда специально подобранных фраз (12 фонетически сбалансированных 6-слоговых предложений), которые прослушиваются на выходе тракта связи рядом экспертов-слушателей, выставляющих свои оценки по 5-балльной шкале MOS (средняя субъективная оценка или средняя оценка мнений) в соответствии с данными табл. 14.3. Затем результаты усредняются. Хотя этот метод является субъективным по своей сути (аналог ССИ), его результаты по сопоставлению различных типов кодеков при проведении испытаний одними и теми же группами дикторов и экспертов-слушателей являются достаточно объективными, и на них основываются практически все выводы и решения.
Экспериментальные субъективно-статистические способы определения оценок качества чрезмерно громоздки и дают достоверные результаты лишь при большом объеме обработанного речевого материала. Поэтому весьма актуально создание объективного метода оценки качества с меньшими затратами труда и времени. Так, при исследовании речевых кодеков (а в последние годы эти исследования стали проводиться с помощью ЭВМ) желательно использовать объективные (формализованные) критерии качества, отличающиеся оперативностью и не требующие привлечения экспертов. Однако существующие объективные критерии качества слабо отражают свойства слухового восприятия. Поэтому критерий качества, используемый для оценивания кодеков одного типа, может оказаться некорректным для кодеков иного типа. Например, такой широко используемый критерий, как отношение сигнал-шум квантования (ОСШК), вполне удовлетворительно оценивающий качество неадаптивных, инвариантных к спектру передаваемого сигнала кодеков, становится некорректным при сравнении адаптивных дифференциальных речевых кодеков. Это связано с различием в характере искажений сигналов.
| Субъективная оценка качества звучания речи | Уровень восприятия речевой информации | Оценка по шкале MOS |
| Очень плохо | Речь не воспринимается полностью или частично | |
| Плохо (слабо) | Речь воспринимается затрудненно, с напряженным вниманием | |
| Удовлетворительно (Разборчиво) | Речь воспринимается свободно, но наличие дефектов неоспоримо | |
| Хорошо | Речь воспринимается свободно, определение дефектов затруднительно | |
| Отлично | Речь воспринимается полностью и без искажений |
В табл.14.4 представлена сводная информация о наиболее распространенных способах кодирования речи. Здесь оценка различных методов кодирования связана с восприятием речи человеком, т.е. со средними субъективными оценками по шкале MOS.
| Метод кодирования РС | Стандарт / Год принятия | Цифровая скорость, кбит/с | Оценка качества по шкале MOS |
| ИКМ (PCM) | ITU-T G.711/1960 | 4,1…4,5 | |
| АДИКМ (ADPCM) | ITU-T G.726/1984 | 32/64 | 3,8 / 4,6 |
| IMBE | INMARSAT-M/1990 | 6,4 | 3,1 |
| LD-CELP | ITU-T G.728/1992 | 3,8 | |
| RPE-LTP | ETSI GSM/1992 | 3,6 | |
| VSELP | EIA/TIA IS54/1992 | 3,45 | |
| CELP | FS-1016 (США) | 4,8 | 3,15 |
| MP-MLQ | ITU-T G.723.1/1996 | 6,4 | 3,9 |
| ACELP | ETSI TETRA/1996 | 4,8 | 3,4 |
| MELP | США/1998 | 2,4 | 3,5 |
| LPC-10 | ANSI | 2,4 | 2,9 |
Так, при точном квантовании в ИКМ шум можно считать стационарным процессом с равномерной спектральной плотностью мощности (СПМ). В то же время при адаптивном квантовании, когда шаг квантования изменяется в соответствии с дисперсией нестационарного РС, дисперсия ошибки квантования оказывается с ней связанной, т.е. шум квантования становится также нестационарным. Обычно ОСШК не учитывает ни спектральных соотношений сигнала и шума, ни их нестационарного характера. При субъективном же восприятии важно соотношение не только дисперсий, но и СПМ РС и шума. Поэтому за основу объективного критерия, учитывающего свойства слухового восприятия, должны быть приняты оценки кратковременных СПМ РС и ошибки квантования. Корректность критерия качества передачи характеризуется корреляцией объективных оценок, вычисленных с его использованием, и субъективных оценок качества передачи.
Объективная оценка качества РС может производиться как во временной области, так и в частотной области. Во временной области критерием качества является ОСШК. В адаптивных речевых кодеках шаг квантования изменяется в соответствии с дисперсией РС, поэтому дисперсия ошибки квантования зависит от дисперсии РС. При исследованиях таких кодеков важны значения кратковременных ОСШК, вычисленных на коротких сегментах РС длительностью 10...30 мс. Такое сегментное ОСШК учитывает сегментный характер слухового восприятия элементов речи и является лучшей мерой искажений, при которой паузы в РС не учитываются. Однако чтобы их игнорировать, они должны быть обнаружены.
При кодировании с адаптивным предсказанием параметры предсказателя изменяются в соответствии с кратковременной СПМ РС, что делает необходимым учет сегментно-спектрального характера слухового восприятия в пределах временного сегмента РС. Так как область слышимых частот разделяется на критические полоски, то в каждой из них установлено оптимальное для слухового восприятия соотношение спектральных мощностей сигнала и ошибки квантования. С точки зрения простоты вычислений, длительности необходимого для анализа речевого материала (около 3 с, т.е. одна - две фразы), а также хорошей корреляцией с объективными оценками качества показатель качества на основе сегментного ОСШК может рассматриваться как весьма эффективный инструмент при исследованиях кодеков различных типов.
В частотной области критерием качества является степень искажения спектральной огибающей. Было установлено, что использование критерия качества в частотной области в большей степени соответствует субъективным оценкам, чем критериям во временной области. Так, при оценке качества звучания сигнала в вокодерных методах передачи, где форма реализаций речевых сигналов в дискретном времени на входе кодера xt и выходе декодера xt* может существенно различаться, основным показателем является близость оценок СПМ xt и x*t. Существует множество показателей, контролирующих эту близость. В частности, определение критерия качества в частотной области базируется на LPC кепстральном расстоянии (CD). (Термин "кепстр" был введен в США в начале 60-ых годов и является в настоящее время общепринятым для обозначения обратного преобразования Фурье логарифма спектра мощности сигнала). Спектральное искажение как мера качества речи определяется здесь через спектральное расстояние между спектром входного и выходного сигналов. В свою очередь, мерой спектрального расстояния служит кепстральное расстояние CD.
Этот метод используют для оценки качества РС в системе линейного предсказания. Он незначительно отличается от субъективного метода MOS (коэффициент корреляции между этими методами около 0,96) - чем больше кепстральное расстояние CD, тем ниже средняя оценка мнений MOS. Такая зависимость справедлива не только для систем LPC, но и ИКМ, АДИКМ и других систем.
15. Повышение помехоустойчивости цифрового канала передачи
При передаче цифровых данных по каналу с шумом и, тем более, с замираниями, обусловленными многолучевым распространением радиоволн, всегда существует вероятность того, что принятые данные будут содержать ошибки. Частота появления ошибок, при превышении которой принятые данные использовать нельзя, определяется свойствами слухового восприятия человека. А именно - должна быть установлена допустимая вероятность ошибок Рош, не приводящая к заметным на слух искажениям на аналоговом выходе. Поэтому средняя вероятность ошибочного приема элемента сигнала Рош является основной характеристикой помехоустойчивости цифрового канала связи. Снижение вероятности ошибок может быть достигнуто путем повышения требований к энергетическим характеристикам радиосистемы передачи – мощности радиопередатчиков, коэффициенту усиления антенн, шумовой температуре приемников. Однако далеко не всегда эти меры экономически оправданы и позволяют снизить вероятность ошибок до пренебрежимо малой величины.
Одним из важнейших средств в обеспечении достоверности передачи цифровых данных является использование канальногокодирования с исправлением ошибок(FEC coding). Кодирование канала (иначе – избыточное или помехоустойчивое кодирование), основанное на применении специальных корректирующих кодов, реализуется путем добавления по определенному алгоритму в каждый кодовый блок некоторого количества поверочных символов. Эта избыточность позволяет корректирующему ошибки декодеру детектировать и исправлять неверно дошедшие данные и восстанавливать исходный поток данных по принятому потоку
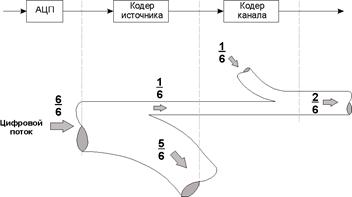 Выбор типа корректирующего кода и его параметров зависит от требуемой достоверности приема, допустимой скорости передачи, вида ошибок в канале, сложности (стоимости) реализации схем декодирования. Учитывается также, что в результате эффективного устранения избыточности в процессе кодирования источника, предшествующего кодированию канала, информационная ценность каждого передаваемого в канал бита резко возрастает. Приблизительное соотношение естественной избыточности речевого сигнала и искусственной избыточности, вносимой в канал кодером канала, иллюстрирует рис. 15.1.
Выбор типа корректирующего кода и его параметров зависит от требуемой достоверности приема, допустимой скорости передачи, вида ошибок в канале, сложности (стоимости) реализации схем декодирования. Учитывается также, что в результате эффективного устранения избыточности в процессе кодирования источника, предшествующего кодированию канала, информационная ценность каждого передаваемого в канал бита резко возрастает. Приблизительное соотношение естественной избыточности речевого сигнала и искусственной избыточности, вносимой в канал кодером канала, иллюстрирует рис. 15.1.
Рис. 15.1. Иллюстрация процессов кодирования источника и канала
Обсудим простые модели канала, описывающие процессы, происходящие между кодером и декодером (см. также рис. 6.1). На рис. 15.2 представлено несколько базовых моделей каналов, применимых для анализа канального кодирования. Наиболее простая модель называется двоичным симметричным каналом (ДСК) без памяти (рис. 15.2, а). Входы и выходы этого канала - двоичные. Переданные и принятые блоки данных соблюдают побитовый порядок и на входе, и на выходе модели канала. Каждый бит кодируемой последовательности приходит на выход канала в неизменном виде с вероятностью 1 – Рош. С вероятностью Рош передаваемые биты инвертируются, т.е. возникают битовые ошибки. Декодер принимает решение о переданной закодированной последовательности с по принятой двоичной последовательности г. В процессе принятия решения декодером могут применяться только те отношения алгебраической независимости между отдельными битами переданной последовательности, которые были установлены правилом кодирования. Отсутствие у рассматриваемой модели памяти приводит к тому, что ошибки статистически становятся взаимно независимыми, т.е. возникновение ошибок в предшествующие моменты времени никак не влияет на вероятность появления ошибок в текущий момент.
Очень немногие реальные каналы передачи могут считаться действительно не имеющими памяти. В большинстве случаев ошибки возникают пакетами. С другой стороны, существует множество алгоритмов декодирования, разработанных специально для исправления случайных ошибок, т.е. ориентированных на каналы без памяти. С целью обеспечения достаточно высокой эффективности коррекции ошибок предпринимаются дополнительные меры для разбиения пакетов ошибок в приемнике, в частности, метод перемежения (interleaving) данных.
Вторая модель канала (рис. 15.2, б) учитывает пакетную природу ошибок, возникающих в канале передачи данных. Это значит, что появление одной ошибки в конкретный момент времени увеличивает вероятность появления ошибки в следующий момент. В этом случае говорят, что канал обладает памятью о своих предыдущих состояниях. Для таких ситуаций разработаны специальные коды и алгоритмы декодирования.
В третьей модели (рис. 15.2, в), которая аналогично первой не имеет памяти, декодер использует не только знания об алгебраических соотношениях между отдельными битами, но и дополнительную информацию, поступающую из канала и позволяющую оптимизировать процесс декодирования. Для получения такой информации отсчет сигнала, полученный в приемнике в процессе демодуляции, квантуется в М -уровневом квантователе.
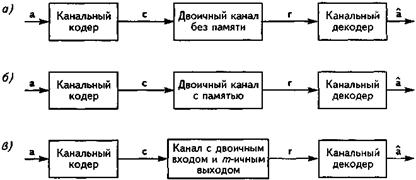
Рис. 15.2. Модели каналов с точки зрения канального кодирования
Если каждому возможному уровню квантования поставить в соответствие число от 0 до М – 1, то будет получена модель канала с двоичным входом и т-ичным выходом (рис. 15.3). В такой модели сигнал на выходе канала измеряется намного точнее, чем в модели двоичного канала. Это позволяет использовать дополнительную информацию, содержащуюся в принятом символе для повышения качества декодирования, т.е. снизить вероятность принятия неверного решения о принимаемой кодированной последовательности. Декодирование, при котором используется дополнительная информация канала, называется декодированием с мягким решением. В противовес ему, декодирование с использованием только информации двоичных символов называется декодированием с жестким решением. В большинстве применяемых в современной цифровой сотовой телефонии алгоритмов декодирования используются мягкие решения.
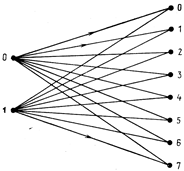
Рис. 15.3. Модель двоичного канала, обеспечивающего мягкие решения при M = 8.
В современных цифровых системах связи и вещания для обнаружения и исправления ошибок применяют либо блочные (блоковые) корректирующие (n,k)-коды, либо сверточные коды (СК). Определяющее различие между кодерами для кодов этих двух типов состоит в наличии или отсутствии памяти.
Кодер для блокового кода отображает последовательности из k входных символов в последовательности из n выходных символов, причем всегда п > k.. При этом каждый блок из n символов зависит только от соответствующего блока из k символов и не зависит от других блоков. Параметрами блокового кода являются n, k, R = k/n – скорость кода и d - кодовое расстояние. Кодовоерасстояние является основным показателем корректирующей способности кода. Оно равно минимальному числу позиций, в которых кодовые комбинации отличаются друг от друга. Если в пределах блока кода при передаче появляется q ошибочных символов, то считают, что произошла ошибка кратности q. Кратность обнаруживаемых qо и исправляемых qи кодом ошибок связаны с кодовым расстоянием соотношением d = qо + qи + 1, причем всегда qо ³ qи. Конкретный тип кода задается тремя параметрами: n, k и d. При q > 3…5 эффективность блоковых кодов заметно снижается, то есть существенно возрастает требуемая при этом избыточность. Поэтому в современных СПРС используются более эффективные сверточные коды.
Сверточный код - это линейный рекуррентный код. В общем случае он образуется следующим образом. В каждый тактовый момент времени на вход кодирующего устройства (регистр сдвига с K ячейками) поступает m символов сообщения; n выходных символов формируются с помощью рекуррентного соотношения из K = m + q символов сообщения, среди которых m поступили в данный тактовый момент времени, а q - в предшествующие. Символы сообщения, из которых формируются выходные символы, хранятся в памяти кодера. Параметр K часто называют длиной кодового ограничения данного кода. СК характеризуются также скоростью R = m / n и свободным расстоянием dсв, аналогичным параметру d блоковых кодов. Типичные значения параметров СК: m,n = 1 - 8, R = 1/4 - 7/8, K = 3 -10.
Введение при кодировании канала в информационный сигнал избыточных символов сопровождается негативным эффектом — снижением, при неизменной скорости цифрового потока (Rц), скорости передачи полезной нагрузки (Сц) обратно пропорционально скорости кода (R): Rц = Сц / R, бит/с. Поэтому для сохранения скорости передачи полезной нагрузки необходимо расширение полосы частот канала в R раз или повышение кратности модуляции.