2015-01-30
2015-01-30 999
999Кластерная многопроцессорная система лучше всего подходит для приложений,
где требуется достаточная гибкость. Это особенно актуально, когда система должна выполнять множество различных задач, причем некоторые из них могут выполняться одновременно. Конфигурация кластерной многопроцессорной системы показана на рис. 7.3. Процессоры SHARC также имеют хост_интерфейс, который позволяет кластеру легко взаимодействовать с хост_процессором или с другим кластером.
Кластерные многопроцессорные системы содержат множество процессоров SHARC, соединенных параллельной шиной, которая позволяет осуществлять межпроцессорное обращение к внутренней памяти, расположенной на кристалле, а также обращение к совместно используемой глобальной памяти. В обычном кластере до шести процессоров SHARC и хост_процессор могут управлять шиной. Расположенная на кристалле логика арбитража шины
позволяет этим процессорам совместно использовать одну шину. Другое
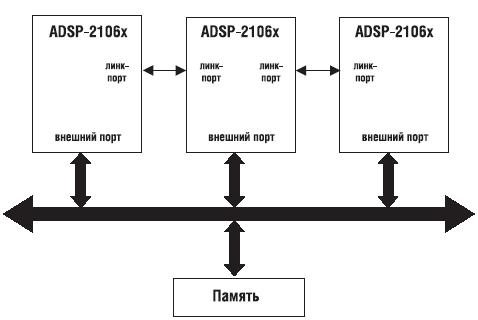
свойство процессоров SHARC помогает устранить необходимость в любых дополнительных аппаратных средствах при конфигурации кластерных многопроцессорных систем. В системах этого типа часто не используются ни локальная, ни глобальная внешняя память.
В ADSP_2106x поддерживаются две схемы приоритетов – фиксированные и вращающиеся приоритеты, а также блокировка шины, ограничение времени использования шины и приостановление фоновых передач по DMA обращением ядра процессора. Логика арбитража шины позволяет осуществлять передачу управления шиной c одним непроизводительным циклом. Запросы шины генерируются всякий раз, когда процессор обращается по внешнему адресу. Из_
за того, что каждый процессор контролирует все запросы шины и применяет одну и ту же логику определения приоритета запросов, каждый процессор может независимо определить, кто будет следующим ведущим. Так как в процессор встроены возможности совместного использования шины, проектировщикам не нужно разрабатывать собственную логику совместного использования шины и синхронизации.
Когда процессор получает управление шиной, он может обращаться не только к
внешней памяти, но и к внутренней памяти и регистрам IOP всех других процессоров. Процессор может прямо передавать данные в другой процессор или инициализировать канал DMA для передачи. Каждый процессор отображается в общую карту памяти. Для идентификации адресного пространства любого процессора внутри объединенной карты памяти кластерной системы каждый
процессор имеет уникальный идентификатор. Регистры IOP, внутренняя память и внешняя память являются частью объединенного адресного пространства.
Совместное использование внутренней памяти устраняет необходимость использования внешней памяти для передачи сообщений между процессорами и упрощает создание программного обеспечения для взаимодействия процессоров.
Процессоры могут записывать прямо в память друг другу, не затрачивая дополнительный цикл на передачу шины. Локальная память может не использоваться, так как SHARC имеет большой объем SRAM. Однако для больших приложений блоки данных и кода могут храниться в совместно используемой памяти и загружаться во внутреннюю память процессора.
Взаимодействие между процессорами упрощается посредством возможности широковещательной записи во все процессоры одновременно. Она может использоваться для реализации взаимных семафоров, когда процессор опрашивает свою внутреннюю копию семафора и использует внешнюю шину только для широковещательной записи во все другие процессоры, когда он хочет изменить семафор. Это снижает трафик внешней шины. Кластерная конфигурация обеспечивает очень высокую скорость передачи данных между процессорами. Она также позволяет просто и эффективно реализовать программируемую модель коммуникации. Например, все требуемые настройки операций передачи по DMA могут быть выполнены процессором на одной передающей стороне. Работа другого процессора не прерывается, пока
передача по DMA не будет выполнена.
Внутренняя память SHARC разработана таким образом, чтобы облегчить ввод_
вывод в многопроцессорных системах. Двухпортовая RAM, расположенная на кристалле, позволяет осуществлять передачу данных между процессорами с максимальной скоростью, а также параллельно выполнять двойной доступ ядра процессора. При этом производительность процессора остается полной – 40 миллионов команд в секунду (MIPS – million instructions per second), 120 миллионов операций с плавающей точкой в секунду (MFLOPS – million floating
operations per second
Прерывание запроса обслуживания линк&порта (LSRQ)
Запрос обслуживания линк_порта дает возможность заблокированному линк_ порту (для которого не назначен буфер или назначен заблокированный буфер) генерировать прерывание при попытке внешнего доступа. Биты состояния запроса приема и передачи в регистре LSRQ (биты 20_31) позволяют процессору ADSP_2106x определить, пытается ли друго й процессор ADSP_2106x послать или принять данные через соответствующий линк_порт. Это дает возможность двум процессорам связываться без предварительного информирования о
направлении передачи, номере линк_порта или без точных сведений о том, когда
будет произведена передача.
Когда LxACK или LxCLK выставляются внешним устройством, генерируется запрос обслуживания линк_порта (LSR – Link Service Request) в заблокированном линк_порту (для которого не назначен буфер или назначен заблокированный буфер). LSR не генерируется для линк_порта, который заблокирован из_за работы в циклическом режиме. Каждый LSR маскируется
битами маски до его фиксации в регистре LSRQ. Шесть возможных LSR для приема и шесть возможных LSR для передачи объединяются по схеме «монтажное ИЛИ» для генерации прерывания запроса обслуживания линк_ порта. Запрос прерывания LSRQ может быть маскирован битом маски LSRQI в регистре IMASK. Когда бит маски установлен, прерывания могут проходить в устройство определения приоритета прерывания. Блок_схема этой логики
показана на рис. 9.5а.
Программа обработки прерывания должна считывать регистр LSRQ для определения номера линк_порта, который надо обслужить, и типа запроса –передача или прием.
Прерывания LSR имеют задержку два цикла. Заметим, что прерывание запроса обслуживания линк_порта отличается от прерываний приема и передачи линк_ порта.
32_разрядный регистр LSRQ содержит маскируемые биты состояния запроса приема или передачи для каждого линк_порта и соответствующие биты маски прерывания. Бит состояния линк_порта устанавливается, когда порт заблокирован и выставлен (высокий уровень) один из сигналов LxACK или LxCLK. Биты состояния LSRQ только для чтения. В табл. 9.5 и на рис. 9.6
показаны биты регистра LSRQ.
Чтобы определить, какой линк_порт надо обслужить,передайте содержимое регистра LSRQ в регистр Rx (в регистровый файл), используя команду обнаружения начальных нулей (Rn=LEFTZ Rx). Rn укажет активизированные линк_порты в порядке приоритета.
Если используются запросы обслуживания линк_порта, то они должны маскироваться при активизации и блокировании буферов, назначенных линк_порту, или при блокировании линк_порта в регистре LAR, в противном случае могут генерироваться ложные запросы обслуживания.
Необходимость этого маскирования возникает из_за задержки «подтягивания» к
земле (если оно разрешено) сигналов LxCLK или LxACK (если они были
выставлены) или из_за задержки при выполнении сброса этих сигналов внешним
устройством ниже логического порога (если «подтягивание» запрещено). При
опросе этих сигналов в течение этой задержки определяется, что они
выставлены, в результате чего генерируется LSRQ.
Чтобы устранить возможность возникновения ложных прерываний, маскируйте
прерывание LSRQ или соответствующий бит запроса в регистре LSRQ и
обеспечьте соответствующую задержку перед демаскированием этого
прерывания. С другой стороны, маскируйте прерывание LSRQ и опрашивайте
соответствующий бит состояния запроса до тех пор, пока он не будет очищен, а
затем демаскируйте прерывание.