 2015-01-30
2015-01-30 2227
2227Тема 17
Стр.
1. Технологии отыскания эффективных решений с учетом
относительной важности критериев …………………………………………... 2
2. Технология реализации базовых методов решения
многокритериальных задач …..…………………………………..…….……... 10
Литература ……………………………………………………………….…….. 28
Санкт-Петербург - 2012
1. Технологии отыскания эффективных решений с учетом
относительной важности критериев
Суждения об относительной важности частных критериев ЛПР может выразить как в качественной, так и в количественной шкале. Если частные критерии измеряются в различных, а тем более разных по классам шкалах (количественных и качественных), их оценки не могут быть пересчитаны в некоторую объективную шкалу оценивания (например, в универсальный денежный эквивалент), то трудно представить, как соизмерить их относительную важность. А сделать это иногда требуется как можно быстрее и как можно адекватнее, чтобы можно было сразу представить себе ценность какой-то конкретной альтернативы. В подобных ситуациях, когда информацию об относительной важности требуется получить и использовать как можно быстрее и при этом обеспечить высокую адекватность и надежность суждений, более предпочтительным представляется учет относительной важности частных критериев в качественной шкале (так называемая «качественная информация об относительной важности»). К качественной информации об относительной важности частных критериев будем относить следующие вербальные суждения:
§ «критерий с номером i важнее критерия с номером j»; информацию такого типа будем формально обозначать как inf= i pre j, от английского «preference»;
§ «критерии с номерами s и t равноценны по важности»; краткое обозначение inf=s ind t, от английского слова «indifference».
Напрямую использовать информацию inf=pre или inf=ind для дальнейшего сокращения размера множества eff(wr iop) эффективных альтернатив и поиска наилучшего решения среди них можно только для некоторых частных случаев. Во-первых, это случай, когда шкалы всех частных критериев, относительно которых получена информация inf=pre или inf=ind, однородны и имеют небольшое число дискретных градаций. Чаще всего для этих целей используют 3...7-балльные шкалы. Это обусловлено тем, что дискретные однородные шкалы имеют важную особенность. Если в какой-то исходной векторной оценке, имеющей значения в однородной дискретной шкале, например, w(a)=(2, 4, 7, 3, 5) значения частных критериев поменять местами, скажем так: (7,2, 4, 3, 5), то полученная оценка, назовем ее w(b), также будет иметь осмысленное значение. То есть ЛПР будет воспринимать оценку w(b)=(7, 2, 4, 3, 5) как вполне возможную и уместную.
Второй частной ситуацией, когда возможно прямое использование качественной информации о равноценности или превосходстве в важности одних частных критериев над другими, является такая, в рамках которой фигурируют сообщения о равноценности всех критериев между собой, об абсолютно строгом (лексикографическом) упорядочении критериев по важности, а также — о симметрически-лексикографическом упорядочении частных критериев по важности. Обозначениями для этих особых случаев будут inf=sym, inf=lex и inf=sl соответственно. Заметим, что информация inf=lex о лексикографическом упорядочении настолько сильна, что позволяет всегда получить наилучшее решение даже непосредственно из исходного множества. Технология использования лексикографической информации для поиска решения задачи выбора даже не требует преобразования шкал критериев к однородной. Однако за подобные технологические «удобства» приходится подчас жестоко расплачиваться потерей адекватности результата. Поэтому лексикографической моделью предпочтений следует пользоваться крайне осторожно.
Самая сложная в получении, но и самая действенная — это информация об относительной важности критериев в количественной форме. Это информация о величинах замещений значений критериев между собой, о значениях коэффициентов важности частных критериев, количественная информация о допустимой степени взаимной компенсации значений тех или иных критериев, а также — о виде функции агрегирования частных критериев в обобщенные критерии. В некоторых случаях такая информация поступает от ЛПР сразу. Но это — скорее исключение из правил. Значительно чаще количественную информацию приходится получать по частям.
Рассмотрим наиболее часто встречающиеся способы реализации технологий отыскания эффективных решений с учетом относительной важности критериев.
Технология преобразования натуральных шкал критериев в однородную дискретную шкалу. По всему множеству альтернатив 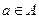 определяют множество {wHi(a)} возможных значений оценок каждого частного критерия wHi в натуральной шкале. Затем ЛПР (или эксперт) решает вопрос о том, сколькими классами толерантных, то есть похожих, оценок это множество можно концептуально описать. Например, ЛПР решило, что можно множество всех возможных значений оценок критерия wHi — «устойчивость фирмы при совершении финансовых операций» — концептуально характеризовать пятью классами значений с градациями: «Удовлетворительный», «Вполне удовлетворительный», «Хороший», «Весьма хороший», «Отличный». Затем классы нумеруют в порядке возрастания предпочтительности введенных градаций. В нашем примере концептуальная оценка была произведена таким образом:
определяют множество {wHi(a)} возможных значений оценок каждого частного критерия wHi в натуральной шкале. Затем ЛПР (или эксперт) решает вопрос о том, сколькими классами толерантных, то есть похожих, оценок это множество можно концептуально описать. Например, ЛПР решило, что можно множество всех возможных значений оценок критерия wHi — «устойчивость фирмы при совершении финансовых операций» — концептуально характеризовать пятью классами значений с градациями: «Удовлетворительный», «Вполне удовлетворительный», «Хороший», «Весьма хороший», «Отличный». Затем классы нумеруют в порядке возрастания предпочтительности введенных градаций. В нашем примере концептуальная оценка была произведена таким образом:
1. «Удовлетворительный»;
2. «Вполне удовлетворительный»;
3. «Хороший»;
4. «Весьма хороший»;
5. «Отличный».
После этого множество значений wHi оценок каждого частного критерия в натуральной шкале графически отображают в виде интервала 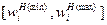 . Этот интервал представляют ЛПР (или эксперту). ЛПР ставит на отрезке точки, которые приблизительно отображают его преставления о границах толерантных значений критерия. Пусть для примера ЛПР рассматривает критерий «устойчивость фирмы при совершенствовании финансовых операций». Этот критерий имеет множество возможных значений в натуральной шкале, измеряющей вероятность «непотопляемости» фирмы конкурентами в ходе совершения финансовых операций. Пусть оказалось, что все значения этого критерия лежат в диапазоне от 0,3 до 0,87. На рис. 1.1,а диапазон оценок критерия «устойчивость...» представлен в виде отрезка прямой, границы которого помечены значениями 0,3 и 0,87.
. Этот интервал представляют ЛПР (или эксперту). ЛПР ставит на отрезке точки, которые приблизительно отображают его преставления о границах толерантных значений критерия. Пусть для примера ЛПР рассматривает критерий «устойчивость фирмы при совершенствовании финансовых операций». Этот критерий имеет множество возможных значений в натуральной шкале, измеряющей вероятность «непотопляемости» фирмы конкурентами в ходе совершения финансовых операций. Пусть оказалось, что все значения этого критерия лежат в диапазоне от 0,3 до 0,87. На рис. 1.1,а диапазон оценок критерия «устойчивость...» представлен в виде отрезка прямой, границы которого помечены значениями 0,3 и 0,87.

Рис.1.1. Схема преобразований натуральных шкал критериев в дискретную однородную шкалу
На рис. 1.1.а также обозначены точки, с помощью которых ЛПР указало приблизительные границы введенных толерантных градаций. Так множество значений критерия «устойчивость...» на уровне «Удовлетворительный» отделены от множества значений на уровне «Вполне удовлетворительный» точкой со значением 0,45. Аналогично точки со значениями 0,70, 0,80 и 0,85 разделяют множества значений «Хороший», «Весьма хороший» и «Отличный» соответственно. Поскольку градации пронумерованы числами от 1 до 5 в порядке возрастания предпочтений, любую оценку критерия в натуральной шкале вероятности устойчивости предприятия или фирмы в ходе совершения финансовой операции легко превратить в оценку, имеющую значения в шкале {1,2,3, 4, 5}. Например, оценка вероятности 0,4 трансформируется в значение 3 для дискретного однородного критерия, а значение вероятности 0,86 — в значение 5. Если какой-то критерий имеет оценки в натуральной шкале, отрицательно ориентированные по предпочтению, схема преобразований остается прежней, только более предпочтительные значения дискретного однородного критерия будут соответствовать меньшим значениям критерия в натуральной шкале. Для примера на рис. 1.1,б показано, как на диапазоне [16,... 48} значений критерия wH2 «Продолжительность непрерывной работы персонала при составлении годового бухгалтерского баланса» в часах. Этот критерий желательно минимизировать. ЛПР разместило на числовой оси разделяющие точки 20, 24, 32, 40 так, как, по его мнению, располагаются границы представленных пяти градаций предпочтительности. Однако теперь более предпочтительное значение в однородной шкале, равное 5, получат оценки продолжительности непрерывной работы персонала, лежащие в диапазоне от 16 до 20 часов.
Рассмотренная схема преобразований имеет ряд преимуществ. Во-первых, ЛПР работает в привычном для него режиме, так как от него требуется делать лишь качественные суждения (типа «Удовлетворительно»,..., «Отлично») о значениях оценок критериев, исходя из понятного для него их смысла и ориентируясь на ясное представление о цели предстоящей операции. Во-вторых, такая схема не только превращает значения натуральных критериев в однородную шкалу, но и делает все новые однородные критерии положительно ориентированными по предпочтению. В-третьих, сравнительно небольшое число градаций однородного критерия существенно повышает действенность аксиомы Парето, так как существенно уменьшается число несравнений по правилу (wi(a) 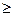 wi(b), i=l, 2,…..,m). В то же время использовать описанную технологию преобразования шкал следует достаточно осторожно. Это обусловлено тем, что на адекватность получаемых результатов и рекомендаций существенное влияние оказывают число градаций выбранной ранговой шкалы и адекватность сортировки натуральных значений шкалы на толерантные градации.
wi(b), i=l, 2,…..,m). В то же время использовать описанную технологию преобразования шкал следует достаточно осторожно. Это обусловлено тем, что на адекватность получаемых результатов и рекомендаций существенное влияние оказывают число градаций выбранной ранговой шкалы и адекватность сортировки натуральных значений шкалы на толерантные градации.
Технология использования информации inf=ind. С целью обеспечения краткости изложения материала по этой и последующим технологиям будем векторные оценки критериев в однородных шкалах для различных альтернатив обозначать не w(a), w(b), w(c) и т.п., а х, у, z и т.п. Пусть, например, inf=s ind t; это означает, что ЛПР считает, что частный критерий с номером s и частный критерий с номером t имеют для него одинаковую относительную важность. Технология отыскания эффективных альтернатив с учетом такой поступившей информации реализуется по следующему алгоритму:
1) преобразовать все натуральные шкалы критериев в однородную дискретную шкалу с одинаковым числом градаций;
2) выбрать какую-то альтернативу из исходного множества, например х;
3) включить ее во множество недоминируемых;
4) взять очередную альтернативу из исходного множества; назовем ее «претендент» и обозначим через у;
5) проверить, не доминируется ли «претендент» у альтернативой х из множества недоминируемых. Для этого построить специальное множество Y ind, состоящее из исходной оценки у и всех ей равноценных по информации ind. Равноценные по информации ind оценки получают из исходной оценки у путем перестановки в ней местами оценок с номерами s и t. Оценку х сравнивают по Парето со всеми элементами из множества Ymd, то есть действуют по правилу:
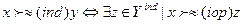 .
.
Иначе говоря, х не менее предпочтителен, чем у по информации о равноценности частных критериев, если найдется хотя бы одна оценка z из множества Ymd (формально записывается как 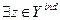 ), которая менее предпочтительна, по Парето, чем х. Если при сравнении по Парето, по правилу (wi(a) wi(b), i=l, 2,…..,m), хотя бы одно из нестрогих неравенств будет выполняться как строгое, то х доминирует над z, а следовательно, и над исходной векторной оценкой у;
), которая менее предпочтительна, по Парето, чем х. Если при сравнении по Парето, по правилу (wi(a) wi(b), i=l, 2,…..,m), хотя бы одно из нестрогих неравенств будет выполняться как строгое, то х доминирует над z, а следовательно, и над исходной векторной оценкой у;
6) если «претендент» у не доминируется, то проверить, не доминирует ли у над х (для этого надо будет по аналогии с множеством Y'nd построить множество Xind); если «претендент» у доминирует над х, исключить альтернативу х из числа недоминируемых, а «претендента» у включить в число недоминируемых, иначе — «претендента» у также включить в число недоминируемых;
7) если среди альтернатив исходного множества осталась хотя бы одна еще не проверенная на эффективность, назначить ее «претендентом», иначе — перейти к шагу 4;
8) последовательно проверять, не доминируется ли «претендент» какой-либо из альтернатив, уже включенных во множество недоминируемых; при первом же обнаружении факта доминирования над «претендентом» его из дальнейшего анализа исключить и перейти к шагу 7;
9) последовательно проверять, не доминирует ли «претендент» над какой-то из альтернатив, ранее уже включенных во множество недоминируемых; если окажется, что «претендент» доминирует над какой-то из альтернатив, уже включенных во множество недоминируемых, эту альтернативу из множества недоминируемых исключить;
10) перейти к шагу 7;
11) проверить, все ли сообщения типа inf= s ind t использованы; если нет — обратиться к очередному сообщению inf = s ind t и перейти к шагу 5;
12) «Stop».
Технология использования информации inf=pre. Эта технология аналогична технологии для информации inf=ind за одним исключением: на шагах алгоритма используются не множества Yind и Xind оценок, эквивалентных по предпочтительности соответствующим исходным оценкам у и х, а специальные множества «улучшенных по сравнению с исходными оценками» — Ypre и Хpre, соответственно. Чтобы из исходной оценки, например у, получить множество Ypre улучшенных по информации inf=s pre t оценок необходимо:
1) преобразовать все натуральные шкалы критериев в однородную дискретную шкалу с одинаковым числом градаций;
2) проверить, является ли компонент уs исходной векторной оценки у больше по величине компонента yt;
3) если компонент ys>yt, то получить оценку z из исходной оценки у путем перестановки в ней местами компонентов ys и yt;
4) включить оценку z во множество Ypre;
5) проверить, есть ли еще сообщения типа s pre t для других номеров s и t;
6) если другие сообщения типа s pre t есть, перейти к шагу 1;
7) «Stop».
Технология использования информации inf=ind и inf=pre. Вначале для «претендента» строят множества Yind и Ypre как это описано в предыдущих двух алгоритмах. Затем эти множества корректируют — из оценок множества Yind, используя информацию типа inf= s pre t, получают дополнительные оценки z для включения их во множество Ypre, а из оценок множества Ypre, используя информацию типа inf= s ind t, получают дополнительные оценки z для включения их во множество Yind. Расширенные таким образом множества Yind и Ypre используются затем для поиска недоминируемых альтернатив, как это уже было описано.
Технология использования информации inf=sym. Наличие такой информации свидетельствует о равноценности всех частных критериев между собой, то есть для всех s и t верны сообщения типа inf=s ind t. Это позволяет воспользоваться более простой технологией для отыскания эффективных альтернатив, чем та, которая была описана для отдельного сообщения (или нескольких сообщений) вида inf= s ind t.
Выполняется следующая последовательность шагов:
1) преобразовать все натуральные шкалы критериев в однородную дискретную шкалу с одинаковым числом градаций;
2) сравниваемые оценки х и у преобразовать в оценки z(x) и z(y), соответственно, для чего в исходных оценках все компоненты упорядочить по возрастанию значений;
3) сравнить по Парето оценки z(x) и z(y);
4) если 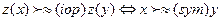 , если
, если 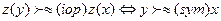 , иначе— х и у несравнимы и, следовательно, обе эффективны;
, иначе— х и у несравнимы и, следовательно, обе эффективны;
5) если остались еще оценки, которые не проверялись на эффективность, перейти к шагу 3;
6) «Stop».
2. Технология реализации базовых методов решения
многокритериальных задач
Рассмотрим базовые методы решения задачи выбора, получившие широкое распространение в практике принятия решений. Наиболее известными и широко применяемыми из них являются;
— лексикографический метод и его модификации;
— метод последовательных уступок;
— метод главного критерия;
— метод агрегированного критерия («обобщенного показателя»).
Все эти методы объединяет общий прием поиска наилучшего решения: векторный критерий тем или иным способом превращается в скалярную целевую функцию, а затем решается задача оптимизации.
Лексикографические задачи. Пусть ситуация обоснования решений характеризуется сведениями об абсолютном превосходстве в важности одних частных критериев над другими. В определенном смысле подобная ситуация полярно противоположна ситуации с информацией sym о предпочтениях ЛПР. Основанием для вывода об абсолютном превосходстве в важности одних частных критериев над другими является следующее. При предъявлении ЛПР для сравнения векторных оценок оно, прежде всего, обращает внимание на значения какого-то вполне определенного частного критерия. Следовательно, именно этот частный критерий ЛПР считает абсолютно самым важным среди других частных критериев. ЛПР сравнивает значения оценок у альтернатив вначале только по этому, самому важному частному критерию.
Если для какой-либо из альтернатив значение именно этого критерия окажется наиболее предпочтительным, то такую альтернативу ЛПР безоговорочно признает наилучшей. Другими словами, ЛПР делает свой выбор вне зависимости от того, какие у этой альтернативы значения оценок по остальным критериям. Если же значения самого важного частного критерия у некоторых альтернатив оказались одинаковы, ЛПР обращает внимание на значения другого (также вполне определенного) частного критерия, который является следующим по важности в абсолютно упорядоченном ряду частных критериев, и т.д. Информация об абсолютном упорядочении критериев по важности столь совершенна, что позволяет задать связное отношение нестрогого предпочтения на множестве даже неоднородных векторных оценок, выделить из них лучшую и поставить ей в соответствие оптимальную стратегию. Информацию такого типа будем называть лексикографической и обозначать inf=lex, а задачи с подобной информацией об относительной важности критериев будем называть задачами лексикографической оптимизации. Информация lex является весьма сильной в том смысле, что для дискретных множеств стратегий А она дает возможность практически всегда выделять единственное решение. В то же время описанный алгоритм лексикографического выбора имеет существенные недостатки. Во-первых, получаемые решения обладают резко выраженной ортодоксальностью в том смысле, что они ориентированы исключительно на более предпочтительные частные критерии. В итоге допускается любой мыслимый ущерб значениям остальных критериев. Во-вторых, в основе идеи перехода к сравнению последующего по важности компонента лежит вывод об «одинаковости значений». На самом деле точно одинаковыми значения частных критериев могут оказаться только при использовании дискретных шкал, что само по себе достаточная редкость, а, следовательно, делая подобный вывод, ЛПР всегда имеет в виду некоторую зону неразличимости (нечувствительности) к значениям критериев.
Симметрически лексикографические задачи. Иногда, рассматривая задачи с равноценными однородными критериями, ЛПР может считать недопустимой компенсацию уменьшения меньших значений одинаково важных критериев сколь угодно значительным увеличением больших. Основанием для вынесения такого суждения может служить следующий факт. При сравнении альтернатив ЛПР обращает внимание на самые низкие значения частных критериев, вне зависимости от их конкретного наполнения. Если у каких-либо альтернатив самые малые значения частных компонентов векторных оценок равны (но больше, чем у остальных альтернатив), то ЛПР принимает во внимание следующие по величине компоненты и т.д. Поскольку эта информация о равноценных частных критериях, сравнение величин которых ЛПР осуществляет, по сути, лексикографически, то подобный частный случай информации о равноценности будем обозначать symlex или информацией sl. Информация sl является более сильной, чем просто информация sут о равноценности частных критериев, так как обладает всеми преимуществами лексикографической. Но одновременно symlex -задачи приобретают и все недостатки лексикографических.
Искусственные лексикографические задачи. В практике часто применяют прием сведения задачи обоснования решений с различающимися по важности частными критериями к задаче лексикографической оптимизации. Без потери общности можно считать, что упорядочение частных критериев по относительной важности задается информацией
{1 рrе 2,2 рrе 3,..., (т-1) рrе т}.
Еще раз подчеркнем, что различие в важности по информации {r рге t} не носит абсолютного, лексикографического характера. От ЛПР получают информацию о том, какие минимальные значения wdj по каждому из частных критериев wi его бы вполне устроили. Информацию об этих «уровнях притязаний» в виде ограничений вида w i>wdi i=l,2,...,m вводят в условия задачи. После этого в ходе поиска наилучшего решения вначале стремятся достигнуть минимально допустимой величины по первому критерию (или немного превысить уровень притязания), затем — минимально допустимой величины по второму критерию, при условии, что значение первого критерия не опускается ниже уровня притязания и т.д. Этот прием формально соответствует преобразованию исходного критерия W скомпонентами wi, в новый критерий Wупс лексикографическим упорядочением компонентов wi уп = min {wi, wdi}.
Метод последовательных уступок. В его основе лежит идея понижения размерности исходной задачи путем назначения главного критерия в специально формируемых двухмерных подзадачах условной оптимизации. Для этого в ходе вербального анализа исходов операции все частные критерии wi, i = 1, 2,..., т ранжируют и нумеруют в порядке убывания важности. Затем максимизируют первый, самый важный критерий w1 и находят его наибольшее значение W1max. Далее, исходя из практических соображений, лицом, принимающим решения, назначается некоторая уступка 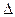 1 от достигнутого значения W1max. Величина уступки — это своеобразная плата за возможность повысить значения очередного по важности критерия w2 от его достигнутого к данному шагу уровня w2(a) для альтернативы а, обеспечивающей величину W 1max. В результате второй критерий может достичь величины w2max( 1), зависящей, естественно, от величины 1 уступки по первому критерию. Затем назначают уступку 2 по критерию w2 (от значения w2max( 1), ценой которой стремятся увеличить значения критерия w3, и т.д. Таким образом, величины уступок последовательно назначаются в результате анализа только попарной взаимосвязи критериев. Выбирая уступки, ЛПР должно рассматривать только зависимость Wi(Wi+1), не обращая внимания на остальные критерии. При этом чаще всего вначале даже незначительная уступка i от значения Wimax приводит к существенному увеличению значения критерия Wi+1, а затем с ростом величины уступки маргинальные приращения в значениях критерия Wi+1 резко уменьшаются. Сопоставляя получаемый в этом случае выигрыш по критерию Wi+1 с потерями в значениях критерия Wi, ЛПР окончательно назначает величину уступки
1 от достигнутого значения W1max. Величина уступки — это своеобразная плата за возможность повысить значения очередного по важности критерия w2 от его достигнутого к данному шагу уровня w2(a) для альтернативы а, обеспечивающей величину W 1max. В результате второй критерий может достичь величины w2max( 1), зависящей, естественно, от величины 1 уступки по первому критерию. Затем назначают уступку 2 по критерию w2 (от значения w2max( 1), ценой которой стремятся увеличить значения критерия w3, и т.д. Таким образом, величины уступок последовательно назначаются в результате анализа только попарной взаимосвязи критериев. Выбирая уступки, ЛПР должно рассматривать только зависимость Wi(Wi+1), не обращая внимания на остальные критерии. При этом чаще всего вначале даже незначительная уступка i от значения Wimax приводит к существенному увеличению значения критерия Wi+1, а затем с ростом величины уступки маргинальные приращения в значениях критерия Wi+1 резко уменьшаются. Сопоставляя получаемый в этом случае выигрыш по критерию Wi+1 с потерями в значениях критерия Wi, ЛПР окончательно назначает величину уступки 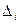 и определяет значение Wj+1max(). Следовательно, именно ранжирование критериев по важности позволяет ЛПР ограничиваться назначением величины уступки для предыдущего критерия только с учетом поведения последующего.
и определяет значение Wj+1max(). Следовательно, именно ранжирование критериев по важности позволяет ЛПР ограничиваться назначением величины уступки для предыдущего критерия только с учетом поведения последующего.
Модифицированный лексикографический метод. Для ослабления недостатков лексикографических методов и получения устойчивых решений даже для непрерывных шкал критериев можно использовать следующий прием. Введем для каждого из т-2 лексикографически упорядоченных компонентов векторного критерия W функции 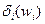 , i=2,3,..., m-1величин пороговых значений зон неразличимости. Для построения функций необходимо предъявлять ЛПР значения
, i=2,3,..., m-1величин пороговых значений зон неразличимости. Для построения функций необходимо предъявлять ЛПР значения 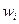 критерия Wi из области его возможных значений и выяснять, при каких значениях одинаковы по предпочтительности оценки
критерия Wi из области его возможных значений и выяснять, при каких значениях одинаковы по предпочтительности оценки 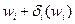 и
и 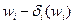 . После этого задача отыскания компромиссного решения осуществляется на основе идеи последовательных уступок. Таким образом, для получения компромиссного решения достаточно иметь информацию о величинах , i=1,2,..., m-1 и рассматривать их как величины предельных уступок, используемых в методе последовательных уступок.
. После этого задача отыскания компромиссного решения осуществляется на основе идеи последовательных уступок. Таким образом, для получения компромиссного решения достаточно иметь информацию о величинах , i=1,2,..., m-1 и рассматривать их как величины предельных уступок, используемых в методе последовательных уступок.
Метод главного критерия. Здесь агрегирование сводится к назначению одного из критериев, например Wj, главным и дополнительно требуют, чтобы значения всех остальных, «неглавных» критериев , 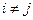 , у довлетворяли дополнительным ограничениям. Обычно указанная подобласть задается ограничениями-неравенствами вида
, у довлетворяли дополнительным ограничениям. Обычно указанная подобласть задается ограничениями-неравенствами вида 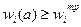 , поэтому задача оптимизации принимает вид:
, поэтому задача оптимизации принимает вид:
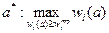 . (2.1.)
. (2.1.)
Альтернатива а*, выделенная в ходе решения задачи (2.1.), как это следует из п. 3 темы 5, будет эффективной.
Метод агрегированного критерия («метод обобщенного показателя»). В этом методе частные компоненты вектора W сворачиваются в скаляр с помощью некоторой агрегирующей функции 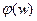 , которая затем максимизируется с целью отыскания оптимальной альтернативы а*. Вид функции агрегирования для данного метода устанавливается на основе сложившихся в данной сфере деятельности традиций; на основе предшествующего опыта или исходя из удобства вычислений, или на основе анализа допустимой компенсации увеличения значений одних критериев за счет уменьшения значений других. В любом случае использование такого подхода может считаться корректным лишь тогда, когда ЛПР четко представляет, к каким последствиям приводит использование того или иного вида функции агрегирования.
, которая затем максимизируется с целью отыскания оптимальной альтернативы а*. Вид функции агрегирования для данного метода устанавливается на основе сложившихся в данной сфере деятельности традиций; на основе предшествующего опыта или исходя из удобства вычислений, или на основе анализа допустимой компенсации увеличения значений одних критериев за счет уменьшения значений других. В любом случае использование такого подхода может считаться корректным лишь тогда, когда ЛПР четко представляет, к каким последствиям приводит использование того или иного вида функции агрегирования.
Если из существа задачи следует, что допустима компенсация уменьшения абсолютных значений одних критериев за счет суммарного абсолютного увеличения других, то в качестве функции агрегирования может быть принята аддитивная функция
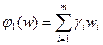 , (2.2.)
, (2.2.)
где 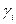 — коэффициенты относительной важности однородных положительно ориентированных частных критериев wi, удовлетворяющие условию нормировки
— коэффициенты относительной важности однородных положительно ориентированных частных критериев wi, удовлетворяющие условию нормировки
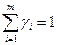 ,
, 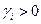 , i=1,2,…,m.
, i=1,2,…,m.
Задачи, в которых выполняются условия для задания функции агрегирования в аддитивной форме, весьма часто встречаются в практике исследования операций. Подобные задачи связаны с критериями суммарного ущерба или прибыли, дохода, денежных или временных затрат по годам планирования или по этапам жизненного цикла экономических информационных систем и т.п., то есть там, где считается допустимым, что низкая ценность одной частной характеристики результата компенсируется высокой ценностью другого. При этом глобальная ценность результата представляется взвешенной коэффициентами важности суммой частных ценностей.
Иногда допустимой может считаться не абсолютная, а относительная компенсация изменения значений одних критериев другими, то есть ЛПР согласно с тем, что суммарная степень относительного снижения одних критериев эквивалентна суммарному уровню относительного увеличения остальных. Это приводит к мультипликативной функции агрегирования:
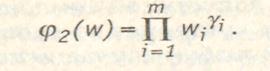 (2.3.)
(2.3.)
Если из существа задачи следует полная недопустимость компенсации значений одних критериев другими, то есть требуется обеспечить равномерное «подтягивание» значений всех критериев к их наилучшему уровню, то используют агрегирующую функцию следующего вида:
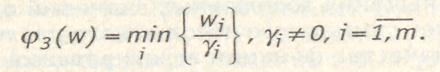 . (2.4.)
. (2.4.)
Такой критерии часто используют в задачах планирования «по узкому месту».
Общим случаем функции агрегирования является средняя степенная функция
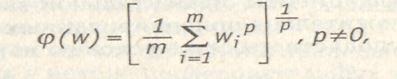 (2.5).
(2.5).
где величина р, стоящая в показателях степени, отражает допустимую степень компенсации малых значений одних равноценных критериев большими значениями других критериев. Чем больше значение величины р, тем больше степень возможной компенсации. Так, например, если величина 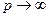 , то есть не допустима никакая компенсация и требуется выравнивание значений всех критериев, то предельный вид агрегирующей функции совпадает с выражением (2.4). Если
, то есть не допустима никакая компенсация и требуется выравнивание значений всех критериев, то предельный вид агрегирующей функции совпадает с выражением (2.4). Если 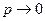 , то есть требуется обеспечение примерно одинаковых уровней значений отдельных частных критериев, то функция агрегирования описывается выражением (2.3.). Важными частными случаями среднестепенной функции являются линейная аддитивная (при р=1 получаем выражение (2.2)) и квадратичная (р=2) свертки, которые широко используются в задачах математической статистики, теории автоматического регулирования, математическом программировании и т.д. Во всех этих случаях полагают, что
, то есть требуется обеспечение примерно одинаковых уровней значений отдельных частных критериев, то функция агрегирования описывается выражением (2.3.). Важными частными случаями среднестепенной функции являются линейная аддитивная (при р=1 получаем выражение (2.2)) и квадратичная (р=2) свертки, которые широко используются в задачах математической статистики, теории автоматического регулирования, математическом программировании и т.д. Во всех этих случаях полагают, что 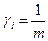 . В задачах планирования ударов «по узкому месту» может считаться допустимой компенсация увеличения одного из критериев сколь угодно большим уменьшением остальных, то есть . В этом случае оказывается приемлемой свертка вида;
. В задачах планирования ударов «по узкому месту» может считаться допустимой компенсация увеличения одного из критериев сколь угодно большим уменьшением остальных, то есть . В этом случае оказывается приемлемой свертка вида;
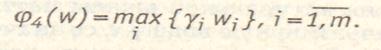 (2.6.)
(2.6.)
Для преобразования однородных шкал частных критериев, с целью последующей подстановки их значений в качестве аргументов функции агрегирования, целесообразно использовать следующий простой прием:
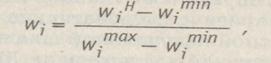 (2.7)
(2.7)
где 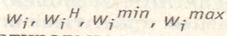 — нормированное, натуральное, натуральное наименьшее и натуральное наибольшее из значений критерия i соответственно.
— нормированное, натуральное, натуральное наименьшее и натуральное наибольшее из значений критерия i соответственно.
Метод семантического структурно-компенсационного исследования. С целью смягчения недостатков, присущих методам последовательных уступок, главного и агрегированного критерия, а также сокращения затрат времени на поиск наилучшего решения и повышения убедительности выводов и рекомендаций в 1993 г. разработан специальный эвристический метод исследования проблемной ситуации и решения задач построения функции выбора в условиях определенности. Основу метода составляет процесс построения двух специальных графов, названных иерархическая семантическая структура (ИСС) и иерархическая компенсационная структура (ИКС) соответственно. Кроме того, в этом методе предложен специальный алгоритм преобразования натуральных шкал частных критериев в однородную шкалу и эвристический подход к определению коэффициентов важности этих критериев в интерактивно формируемой функции агрегирования. С понятием ИСС мы уже встречались выше и знаем, как эта иерархическая структура строится. Что касается ИКС, то это граф, вершинами которого являются частные функции агрегирования типа (2.2)...(2.6.) групповых и терминальных критериев, фигурирующих в ИСС.
Начнем рассмотрение существа метода семантического структурно-компенсационного исследования с изучения предложенного автором алгоритма преобразования натуральных шкал критериев.
Пусть W — векторный критерий, а функция S(wi) отображает значения натуральной шкалы частного i-го критерия Wi в безразмерную шкалу хi со значениями из интервала [0; I]. Требуется установить, как особенности решаемой задачи (семантика частного критерия) и предпочтения ЛПР влияют на вид функции S(wi). При решении задачи установления вида преобразования S(wi), прежде всего, обратимся к главному принципу формирования критериев и, следовательно, отметим те особенности частной натуральной шкалы, которые обусловлены семантикой частной цели ЛПР. Углубленный семантический анализ разнообразных практических целей и задач позволил автору выявить как характерные в предпочтениях ЛПР следующие особенности:
— «нижние» и (или) «верхние» уровни притязаний;
— «зоны нечувствительности» на отдельных фрагментах натуральной шкалы частного критерия;
— точки натуральной шкалы частного критерия, к которым явно устремлено предпочтение ЛПР или которые являются нормативно заданными (квалификационными) значениями.
Поясним эти особенности на примере. Пусть исходная ситуация (статус-кво) по какому-то критерию в момент принятия решений чрезвычайно неблагоприятна для ЛПР. Значения всех частных критериев в статус-кво примем за наименее предпочтительные. В таком случае любое улучшение значения этого критерия от наименее предпочтительного уровня может рассматриваться ЛПР как вполне ощутимый успех. После того как значение рассматриваемого критерия достигнет некоторого уровня, ощутимого как явный сдвиг к улучшению, ЛПР, скорее всего, будет отождествлять любые превышения этого уровня как весьма полное (скажем на 70...80%) удовлетворение. Именно по этой причине такое значение было названо «нижний уровень притязаний». По аналогии было введено понятие «верхнего уровня притязаний». Это уровень, достаточно близкий к идеальным по предпочтительности значениям частного критерия. Превышение «верхнего уровня притязаний» по сравнению со status quo связывается в сознании ЛПР с предельным значением ценности.
Введем далее понятие «зоны нечувствительности», которое отражает одну из следующих особенностей предпочтений ЛПР:
— для ЛПР не представляют ценности значения критерия в некотором диапазоне значений, близких к статус-кво (такое положение означает, что в модели предпочтений ЛПР присутствует «нечувствительность слева»);
— остается неизменной ценность значений критерия в некотором диапазоне, примыкающем к наиболее предпочтительным его значениям (такое восприятие исходов означает, что в модели предпочтений ЛПР присутствует «нечувствительность справа»).
Рассмотрим теперь случай, когда в натуральной шкале критерия присутствуют некоторые точки, на которые ЛПР прежде всего обращает внимание при принятии решений с использованием этого критерия. Например, успех финансово-хозяйственной операции может сильно зависеть.от того, насколько точно по времени сопровождаемый груз прибудет в пункт назначения. Если он окажется в этом пункте раньше — его можно оставить на ответственное хранение без разгрузки, а можно разгрузить за счет сверхурочных работ такелажников (за дополнительную плату). Если груз прибудет позже — придется платить штраф за опоздание. В этом примере явно проглядывает «сходящийся» тип предпочтений: ценность значений критерия вне окрестностей какой-то особой точки резко убывает. Или другой пример. При характеристике должностного лица руководитель особое внимание обращает на то, исполняет или нет это лицо нормативную нагрузку по занимаемой должности. В подобных ситуациях при оценке должностных лиц ЛПР обычно по-разному оценивает скорость изменения ценности значений критерия загруженности работников в случае недовыполнения и перевыполнения нормативных заданий. Проведенное С.Н. Воробьевым системное исследование описанных особых случаев предпочтений ЛПР позволило сформировать классы функций S(wi), отображающие натуральные шкалы критериев wi в безразмерную шкалу Xi со значениями из интервала [0; I]. На рис. 2.1. представлены концептуальные графики функций S(wi).
Обозначения на рис. 2.1 имеют следующий смысл:
W- — минимальное значение критерия;
W-np — значение нижнего уровня притязаний;
W+np — значение верхнего уровня притязаний;
W-л — пороговое значение критерия при нечувствительности слева;
W+п — пороговое значение критерия при нечувствительности справа;
Wc — значение критерия, к которому сходятся предпочтения ЛПР;
WH — значение критерия при «нормативном» типе предпочтений.
На рис. 2.1, а представлен концептуальный график, характеризующий наличие «нижнего уровня притязаний» в модели предпочтений ЛПР по рассматриваемому частному критерию Wi. Из анализа этого рисунка следует, что до уровня W-np значений частного критерия wi степень их предпочтительности изменяется весьма незначительно: достигает 0,1...0,2. В области значений, близких к уровню W-np, наблюдается резкое повышение ценности результатов по этому критерию для ЛПР.
Рис. 2.1. Концептуальные графики функций S(wi)
Рост ценности заканчивается на уровне 1,0 для наилучшего значения W+ рассматриваемого частного критерия. На рис. 2.1, б наибольший темп роста ценности значений частного критерия wi наблюдается на интервале его значений от W- до W+np. Здесь достигается основная доля ценности, примерно 0,8...0,9 от максимального значения. При дальнейшем увеличении значений критерия, на участке от W+np до W+ темп нарастания ценности резко снижается, что свидетельствует о наличии верхнего уровня притязаний в модели предпочтений ЛПР.
На рис. 2.1, в, г представлены концептуальные графики, дающие представление об определенной нечувствительности слева и справа соответственно. На отрезке [W-,W-л ] значения критерия никакой ценности для ЛПР не представляют (значения S(w)=0), а на отрезке [Wn+, W+] ЛПР не ощущает никакого прибавления ценности (значения S(w) постоянны и равны 1,0). Рис. 2.1,д представляет концептуальную модель сходящегося типа предпочтений ЛПР, а на рис. 2.1.е — нормативного типа предпочтений.
Следует иметь в виду, что все графики на рис. 2.1. отражают лишь тенденции изменения ценности для различных значений натуральных шкал частного критерия. В каждом конкретном случае эти тенденции отображаются выпуклыми (в том числе линейными) или вогнутыми функциями, которые соответствуют убывающим (постоянным) или возрастающим скоростям изменения ценности в направлении возрастания значения критерия в натуральной шкале. Кроме того, при построении интерактивных проблемно-ориентированных систем поддержки решений в каждом конкретном случае отдельно решается вопрос о значениях таких компонентов концептуальных моделей, как величины W-np, Wл, Wn, Wc, WH, Xc.
Предположим теперь, что ИСС уже построена. Условимся группы критериев, находящихся на самых нижних уровнях иерархии, называть финальными. Критерии финальных групп будем называть терминальными. Пусть теперь натуральные шкалы всех терминальных критериев преобразованы в соответствии с представленным алгоритмом, и теперь необходимо ответить на вопрос, какими способами оценивать коэффициенты важности групп и частных критериев в них.
Будем относительную важность групп характеризовать числами Гj >0, в сумме равными единице в пределах своего уровня иерархии. Относительную важность отдельных частных критериев будем измерять только в пределах своей группы и определять числами , в сумме также равными единице. Таким образом, если в какой-то группе будет только один частный критерий, то его важность будет приниматься равной единице. Каждый способ определения коэффициентов важности имеет определенную точность и может быть охарактеризован некоторыми затратами.
Воробьев С.Н. предложил целесообразность выбора того или иного способа определения коэффициентов важности ставить в зависимость от уровня иерархии группы, в которую входит тот или иной критерий, от важности самой группы, а также — от числа частных критериев в группе. Почему так? А вот почему. Несомненно, что чем выше уровень иерархии, тем большую концептуальную значимость имеет каждая входящая в него группа по сравнению с группами нижележащих уровней, и, следовательно, тем точнее требуется метод для взвешивания важностей групп. Но более точный метод одновременно и более сложный и требует более высоких затрат на получение результата. Концептуальный анализ совокупности указанных характеристик качества для наиболее употребительных методов оценки коэффициентов важности позволил затем получить результаты, которые удобно изобразить в виде номограммы-классификатора способов оценки важности критериев и их групп в ИСС. Такая номограмма-классификатор представлена на рис. 2.2.
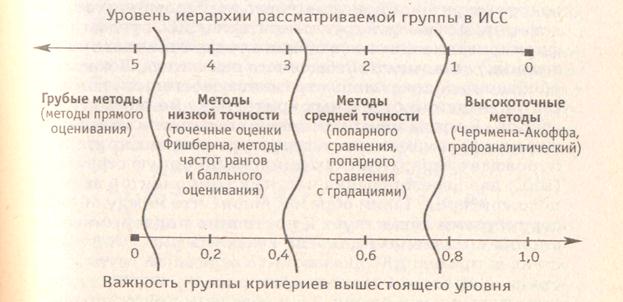
Рис. 2.2. Номограмма-классификатор способов оценки важности критериев и их групп в ИСС
Итак, будем считать, что мы выбрали способ и оценили коэффициенты важности Гi и . Это значит, что мы получили почти всю информацию, необходимую для построения функции агрегирования как отдельных групп, так и терминальных критериев в них. Осталось выбрать только функцию для сворачивания оценок отдельных групп и частных критериев в обобщенный критерий.
Так вот, основное преимущество методики семантического структурно-компенсационного исследования состоит в том, что для каждой группы критериев ИСС предлагается формирование своего (в общем случае отличного от остальных) локального обобщенного показателя. Локальный обобщенный показатель отражает особенности компенсации значений отдельных критериев именно в данной группе. В итоге иерархия целей операции и соответствующая ей семантическая структура частных критериев порождает иерархическую компенсационную структуру (ИКС) для агрегирования частных компонентов векторного критерия. Таким образом видим, что между обеими структурами существует и постоянно поддерживается вполне «осязаемая» для ЛПР связь. На рис. 2.3. представлен пример ИКС для какой-то отдельной группы, состоящей из восьми частных критериев W1 W2, W3,...,W8.
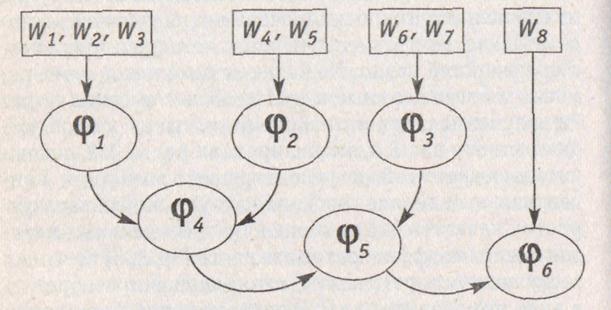
Рис. 2.3. Пример ИКС для группы критериев
Прямоугольниками на рис. 2.3. обведены подгруппы рассматриваемой группы критериев, которые будут локально сворачиваться с использованием какого-то вполне определенного типа агрегирующей функции. Выражение 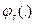 как раз и означает конкретный вид s функции свертки.
как раз и означает конкретный вид s функции свертки.
Процесс агрегирования геометрически представлен на рис. 2.3. в виде стрелок, направленных от соответствующих подгрупп критериев к эллипсу с вписанным в него типом функции свертки. Анализ примера на рис. 2.3. позволяет сделать вывод о том, что сворачиваться могут не только отдельные частные критерии в подгруппах, но и подгруппы между собой. Например, с использованием свертки вида 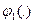 сворачиваются три критерия из подгруппы {W1,W2, W3}, критерии {W4, W5} локально агрегируются сверткой типа
сворачиваются три критерия из подгруппы {W1,W2, W3}, критерии {W4, W5} локально агрегируются сверткой типа 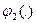 после чего функция
после чего функция 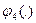 сворачивает три уже свернутые подгруппы {W1, W2, W3}, {W4, W5} и {W6, W7}.
сворачивает три уже свернутые подгруппы {W1, W2, W3}, {W4, W5} и {W6, W7}.
Свертка вида 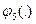 сворачивает полученный с помощью свертки вида результат со значениями терминального частного критерия W8.
сворачивает полученный с помощью свертки вида результат со значениями терминального частного критерия W8.
Следует отметить, что в случае построения иерархической компенсационной структуры для одной группы критериев (групповых или терминальных), важность каждого из критериев рассматриваемой группы обязательно должна быть пересчитана. Иначе относительная важность подгруппы частных критериев, объединяемых в рамках общей для этой подгруппы схемы компенсации, может кардинально исказиться. Поясним это на примере. Пусть рассматривается группа критериев, входящих в глобальный критерий, которая сворачивается с абсолютной суммарной (линейной) степенью компенсации. Эту функцию можно представить как сумму двух сумм, т.е.
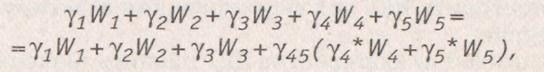
где коэффициенты 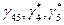 должны подбираться так, чтобы выполнялось равенство значений сумм (глобального критерия). Следовательно, должно выполняться равенство:
должны подбираться так, чтобы выполнялось равенство значений сумм (глобального критерия). Следовательно, должно выполняться равенство:
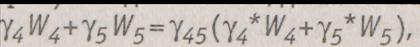
из которого следует, что
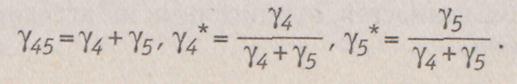
Таким образом, укрупненная методика построения функции агрегирования на основе локальных обобщенных показателей включает следующие действия:
1. Построить ИСС критериев, определить оценки Гj важности групп.
2. Оценить важность критериев внутри каждой финальной группы. Рациональный способ оценивания выбрать, сообразуясь с важностью и уровнем иерархии группы.
3. При необходимости скорректировать оценки важности групп и критериев внутри их с учетом возможных конфигураций, которые могут образовывать группы и критерии между собой.
4. Выделить группы критериев, вносящие «основную долю вклада» в достижение цели на данном уровне иерархии. На основании анализа значений коэффициентов Гj важности групп и в соответствии с правилом «20/80» установить подгруппу критериев, вносящую «основную долю вклада» для рассматриваемого уровня иерархии.
5. В каждой группе на основании анализа значений коэффициентов 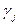 критериев в ней выделить критерии, вносящие «основную долю вклада» в данной группе (также по правилу «20/80»).
критериев в ней выделить критерии, вносящие «основную долю вклада» в данной группе (также по правилу «20/80»).
6. Проанализировать группы по п.4 с целью установления допустимой степени компенсации между обобщенными оценками, которые будут вычислены для групп.
7. Проанализировать подгруппы по п.5 в них с целью установления допустимой степени компенсации между оценками критериев в каждой группе.
8. На основании ИСС по п.1 и результатов анализа по п.п.б и 7 построить ИКС для формирования агрегирующего критерия.
9. Для каждой из альтернатив ЛПР оценить значения всех терминальных критериев. После чего в соответствии с ИКС, двигаясь вверх по уровням ее структуры, произвести последовательное «сворачивание» значений оценок финальных критериев в агрегированный.
10. Все альтернативы упорядочить по значениям нормированных ценностей, приписанных им агрегирующим критерием.
Обратим внимание еще на одну из особенностей предлагаемой методики. Эта особенность состоит в том, что выбор вида свертки для агрегированного критерия в подгруппе в соответствии со сформированной ИКС производят с учетом степени допустимой компенсации не всех групп рассматриваемого уровня ИСС и не всех критериев каждой группы, а только той их части, которая дает «основную долю вклада». Это делается для групп на каждом из уровней ИСС. Подобный прием позволяет не сковывать себя ограничением по числу групп и числу критериев в группе, что создает более комфортные условия для работы ЛПР и экспертов. После определения коэффициентов важности и применения правила «20/80» задача редукции числа групп и числа критериев в группах будет решена автоматически.
На основе рассмотренного метода семантического структурно-компенсационного исследования еще в 1994 г. разработана концепция машинной реализации интерактивной проблемно-ориентированной системы эвристического выбора (ИПОС ЭВ). Концепция получила условное имя «DEMIS» (Decision Making Interactive System), которая была программно реализована в 1995 г. с именем «DEMIS». Многолетняя эксплуатация ИПОС ЭВ «DEMIS» показала высокую эффективность этого программного продукта.
Литература
1.Балдин К. В., Воробьев С. Н. Управленческие решения: теория и технологии принятия. Учебник для вузов. – М.: Проект, 2004. – 304 с.

