2015-02-27
2015-02-27 767
767Проведем проверку алгоритма на задаче из репозитория UCI: Statlog (German Credit Data) Data Set. Объектами являются анкеты людей, желавших получить кредит в банке. Изначально анкеты содержали 20 пунктов, таких как состояние банковсого счета заемщика, информация о его кредитной истории, цель займа, величина займа, возраст заемщика, время с момента трудоустройства на текущее место работы и другие. Но так как некоторые из них не были числовыми, а многие алгоритмы (в том числе рассматриваемый в данной статье) работают только с числовыми признаками, то из 20 разнородных признаков было составлено 24 числовых. Ответы - «хорошим» или «плохим» заемщиком оказался человек, получивший кредит. По условию задачи, распознать «плохого» заемщика как «хорошего» в 5 раз хуже, чем «хорошего» как «плохого». При обучении использован алгоритм отбора признаков Add. В выборке представлена 1000 объектов. В качестве обучающей выборки выбраны первые 690 объектов, в качестве контроля 310 оставшихся.
%% Example 'german credits'% Example with real data %% data preparation%% load dataload 'germanDataNumeric.txt';S = germanDataNumeric;PP.XL = S(1:690,1:24);% if votes are equal, it is better to classify as 2nd class. Make new marks %of classesPP.YL = 3-S(1:690,25);% and change cost matrixPP.errCost = [0 5; 1 0];% initialization of d parametrPP.d = 24;%% run add algorithm[features, jBest] = Add(PP);%% run ParAdjust with selected features% initialization of PP, X PP = [];PP.XL = zeros(690,jBest);PP.XL= S(1:690,features(1:jBest));X= S(691:1000,features(1:jBest)); PP.YL = 3-S(1:690,25);PP.errCost = [0 5; 1 0];% run FeaturesStand[p, m] = size(X);[n, m] = size(PP.XL);Z = [PP.XL; X];Z =FeaturesStand(Z);PP.XL = Z(1:n,:); X = Z(n+1:n+p,:);% run ParAdjustPP = ParAdjustMod(PP.XL, PP.YL, PP)%% run WeightKNNY = WeightKNN(X, PP);YTrue = 3- S(691:1000,25);%% count weighted errors and errorsErrW =0;for i = [1:310]ErrW = ErrW+ PP.errCost(YTrue(i), Y(i));endErr = sum(Y~=YTrue);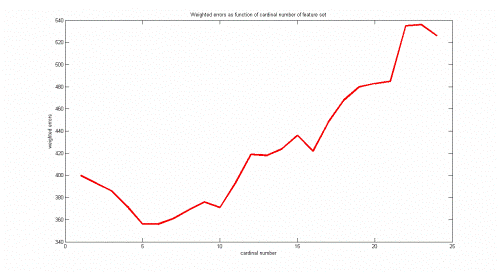
На графике построена зависимость величины взвешенных ошибок при обучении от числа используемых признаков. Алгоритмом Add было отобрано 5 признаков(номера 1, 15, 14, 3, 19). Названия признаков: 1 - текущее состояние банковского счета, 15 - жилье (собственное, снимаете или бесплатно предоставляется), 14 - other installment plans (bank, stores or none), 3 - сведения о ранее выдававшихся кредитах и 19 - один из девяти признаков, полученных в резульате обаботки семи пунктов анкеты (пп 4, 8, 10, 15, 17).
Средней ценой ошибки назовем величину 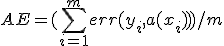 , где, как и ранее,
, где, как и ранее, 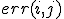 - матрица,
- матрица, 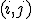 элементом которой является величина ошибки при классификации объекта
элементом которой является величина ошибки при классификации объекта 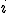 ого класса как объект
ого класса как объект 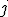 ого класса.
ого класса.
При обучении средняя цена ошибок алгоритма составила 0.52 и 0.83 на контроле. Так как алгоритм допустил значительно больше ошибок на обучении, чем на контроле, то уместно говорить о переобучении.
Отметим также то, что средняя цена ошибок алгоритма k взвешенных ближайших соседей, запущенный без отбора признаков, составила 0.77 при обучении и 0.68 на контроле.
Таким образом, алгоритм отбора признаков существенно снизил число с 24 до 5, понизив качество классификации.
Приведем результаты работы разных алгоритмов на данной выборке:
| Название алгоритма | Стоимость ошибкок при обучении | Стоимость ошибкок на контроле |
| Discrim | 0.509 | 0.535 |
| Quadisc | 0.431 | 0.619 |
| Logdisc | 0.499 | 0.538 |
| SMART | 0.389 | 0.601 |
| ALLOC80 | 0.597 | 0.584 |
| k-NN | 0.000 | 0.694 |
| k-NN,k=17, eucl,std | - | 0.411 |
| CASTLE | 0.582 | 0.583 |
| CART | 0.581 | 0.613 |
| IndCART | 0.069 | 0.761 |
| NewID | 0.000 | 0.925 |
| AC2 | 0.000 | 0.878 |
| Baytree | 0.126 | 0.778 |
| NaiveBay | 0.600 | 0.703 |
| CN2 | 0.000 | 0.856 |
| C4.5 | 0.640 | 0.985 |
| ITrule | * | 0.879 |
| Cal5 | 0.600 | 0.603 |
| Kohonen | 0.689 | 1.160 |
| DIPOL92 | 0.574 | 0.599 |
| Backprop | 0.446 | 0.772 |
| RBF | 0.848 | 0.971 |
| LVQ | 0.229 | 0.963 |
| WKNN, std | 0.770 | 0.732 |
| WKNN, std, Add | 0.516 | 0.839 |
Последние две строки таблицы - результат работы алгоритма, рассматриваемого в данной статье(WKNN, std - без отбора признаков, WKNN, std, Add - с отбором). Данные для построения таблицы взяты с https://www.is.umk.pl/projects/datasets-stat.html.
https://www.basegroup.ru/library/analysis/regression/knn/