| Статистический пакет Анализ данных включает в себя два инструмента для анализа одномерного набора данных: Описательная статистика и Ранг и персентиль. С помощью инструмента Описательная статистика рассчитываются показатели, характеризующие типические значения, изменчивость и асимметрию данных. Инструмент Ранг и персентиль создает таблицу исходных данных, упорядоченных в соответствии с порядковыми числами (рангами) и персентилем. | ||||||||||||||||||||||||||||||||||
| Задать последовательность СВ | ||||||||||||||||||||||||||||||||||
| Применить инструмент анализа Описательная статистика | ||||||||||||||||||||||||||||||||||
| 1.Откройте программу Excel. | Щелкните на кнопке Сохранить на панели инструментов Стандартная. В появившемся диалоговом окне откройте папку Статистика и задайте имя файлу Описательная статистика.xls. | |||||||||||||||||||||||||||||||||
| 2. Запустить инструмент Описательная статистика | Сервис®Анализ данных®Описательная статистика®OK. | |||||||||||||||||||||||||||||||||
| 3. Проверить заданные атрибуты | 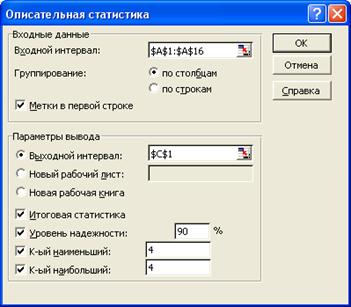 | |||||||||||||||||||||||||||||||||
| 4. Задать положения места построения выходных данных | Включите В области Параметры вывода параметр Выходной интервал:. щелкните в текстовом поле параметра Выходной интервал:, выделите ячейку С1, указывающую адрес левого верхнего угла области вывода данных. | |||||||||||||||||||||||||||||||||
| 5. Задать опцию выхода | Установите следующие флажки: Итоговая статистика Данная опция управляет выводом выходных данных. | |||||||||||||||||||||||||||||||||
| 6. Задать уровень надежности | Уровень надежности: Данная опция вычисляет половину длины доверительного интервала для среднего с заданной значимостью (в %). В нашем примере установите значимость равной 90%. Это означает, что вероятность того, что среднее генеральной совокупности данных находится в пределах доверительного интервала, равна 0,9. | |||||||||||||||||||||||||||||||||
| 7. Задать критерий К наименьшее и наибольшие значения | К-ый наименьший: Эта опция определяет k -ое наименьшее значение из входных данных. К-ый наибольший: Эта опция определяет k -ое наибольшее значение из входных данных. | |||||||||||||||||||||||||||||||||
| 8. Запустить расчет | Щелкните на кнопке OK. Excel вычислит обобщающие показатели и разместит их в виде таблицы в двух столбцах C и D. | |||||||||||||||||||||||||||||||||
| 9. Просмотреть результаты расчета |
| |||||||||||||||||||||||||||||||||
| Интерпретация результатов Проанализировать Среднее Медиану Моду | Выходные данные содержат три обобщающих показателя, которые называются типическими значениями. Среднее можно интерпретировать как равномерное распределение суммы всех значений между элементарными единицами совокупности. Таким образом, если каждое значение из набора данных заменить средним, то общая сумма не изменится. Это свойство среднего полезно в тех ситуациях, когда необходимо планировать общую сумму для большой группы. В этом случае сначала вычисляют среднее для выборки данных из этой группы. Затем полученное среднее умножают на количество элементов в большой группе. В результате получают оценку или прогноз суммы для большей по размеру совокупности. Медиана – значение, расположенное посередине упорядоченного набора данных. Мода – наиболее часто встречающееся значение. Если встречается несколько часто встречающихся значений, то Excel выводит первое из них. Если каждое значение встречается один раз, то Excel выводит запись #Н/Д. В таком случае надо получить таблицу распределения частот, в которой интервал с наибольшей частотой называется модальным интервалом. Для определения модального интервала рекомендуется использовать гистограммы. В таблице описательной статистики имеется несколько показателей, характеризующих изменчивость (разброс) данных. Ü Интервал – размах значений. Определяется как разность между Максимумом и Минимумом. Ü Дисперсия выборки. Вычисляется как результат деления суммы квадратов отклонений каждого значения от Среднего на n -1. Выражается в единицах в квадрате. Ü Стандартное отклонение – корень квадратный из Дисперсии выборки. Стандартное отклонение приближенно показывает, насколько отдельные значения выборки отличаются от их Среднего. Измеряется в тех же единицах, что и входные данные. Ü Стандартная ошибка является характеристикой достоверности Среднего. Вычисляется как Стандартное отклонение, поделенное на 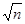 . Данная характеристика показывает, насколько Среднее выборки отличается от среднего генеральной совокупности. Ü Наибольший и Наименьший являются соответственно четвертым наибольшим и четвертым наименьшим значениями входных данных. Ü Уровень надежности (90,0%), определяет половину длины 90%-го доверительного интервала для Среднего. 1. Третья группа показателей характеризует степень симметричности данных. Ü Эксцесс является показателем островершинности симметричных распределений. Если распределение более плоское, чем нормальное (т.е. имеет более «тяжелые» хвосты), то Эксцесс будет положительным. Если же распределение имеет более выраженный пик, чем нормальное (т.е. имеет более «легкие» хвосты), то Эксцесс отрицательный. В нашем примере (см. гистограмму) распределение примерно симметричное с небольшим положительным Эксцессом. Ü Ассиметричность определяет степень симметрии данных. Если большинство экстремальных значений расположено в положительном направлении от центра распределения (скошено вправо), то Ассиметричность положительна. В этом случае Среднее больше Медианы. Если же большинство экстремальных значений расположено в отрицательном направлении от центра распределения (скошено влево), то Ассиметричность отрицательна и Среднее меньше Медианы. Ниже приведена интерпретация показателя Ассиметричности (К) для Excel. K < –0,5 скошено влево –1 £ K £ 1 приблизительно симметрично K > 1 скошено вправо В нашем примере (см. гистограмму) данные приблизительно симметричны с небольшим отрицательным отклонением (скос влево) . Данная характеристика показывает, насколько Среднее выборки отличается от среднего генеральной совокупности. Ü Наибольший и Наименьший являются соответственно четвертым наибольшим и четвертым наименьшим значениями входных данных. Ü Уровень надежности (90,0%), определяет половину длины 90%-го доверительного интервала для Среднего. 1. Третья группа показателей характеризует степень симметричности данных. Ü Эксцесс является показателем островершинности симметричных распределений. Если распределение более плоское, чем нормальное (т.е. имеет более «тяжелые» хвосты), то Эксцесс будет положительным. Если же распределение имеет более выраженный пик, чем нормальное (т.е. имеет более «легкие» хвосты), то Эксцесс отрицательный. В нашем примере (см. гистограмму) распределение примерно симметричное с небольшим положительным Эксцессом. Ü Ассиметричность определяет степень симметрии данных. Если большинство экстремальных значений расположено в положительном направлении от центра распределения (скошено вправо), то Ассиметричность положительна. В этом случае Среднее больше Медианы. Если же большинство экстремальных значений расположено в отрицательном направлении от центра распределения (скошено влево), то Ассиметричность отрицательна и Среднее меньше Медианы. Ниже приведена интерпретация показателя Ассиметричности (К) для Excel. K < –0,5 скошено влево –1 £ K £ 1 приблизительно симметрично K > 1 скошено вправо В нашем примере (см. гистограмму) данные приблизительно симметричны с небольшим отрицательным отклонением (скос влево) |
Обобщающие показатели одномерного набора данных
 2015-04-08
2015-04-08 1293
1293Поделись с друзьями:
|
|
Подборка статей по вашей теме:
- OLAP-системы оперативной аналитической обработки данных
- Система показателей и методика анализа финансовой устойчивости, ликвидности и платежеспособности
- Формы представления статистических данных
- Сводка и группировка данных статистического наблюдения
- Тема 2. Наглядное представление статистических данных
- Система макроэкономических показателей и методы их определения
- Основные типы показателей качества. Методы оценки эффективности и качества продукции
- Показатели информационного обеспечения финансового менеджмента
- Основные показатели деятельности организации
 8491
8491 7934
7934