 2015-04-08
2015-04-08 4138
4138Существует множество способов повышения эффективности работы с большими объемами информации. Например, для ускорения доступа к данным в таблицах можно использовать предварительное упорядочивание таблицы в соответствии со значениями ключей. При этом могут быть использованы методы поиска в упорядоченных структурах данных, что существенно сокращает время поиска данных по значению ключа. Однако при добавлении новой записи требуется переупорядочить таблицу. Потери времени на повторное упорядочивание справочника часто превышают выигрыш от сокращения времени поиска. Рассмотрим способы организации данных, лишенные указанного недостатка. Это – различные формы хеширования данных.
На рис. 2.1 показана базовая структура данных при открытом хешировании. Основная идея метода заключается в том, что множество данных (возможно, очень большое) разбивается на конечное число классов. Для В классов, пронумерованных от 0 до В-1, строится хеш-функция h такая, что для любого элемента x исходного множества функция h(x) принимает целочисленное значение из интервала 0, …, В-1, которое соответствует классу, которому принадлежит элемент x. Элемент x называют ключом, h(x) – хеш-значением х, а классы – сегментами. Массив (таблица сегментов), проиндексированный номерами сегментов 0, 1, … В-1, содержит заголовки для В списков. Элемент х i -го списка – это элемент исходного множества, для которого h(x)=i.
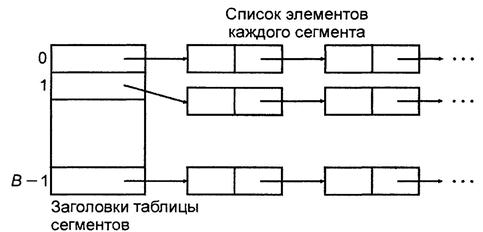
Рис. 2.1 Организация данных при открытом хешировании
Если сегменты приблизительно равны по размеру, то в этом случае списки всех сегментов должны быть наиболее короткими при данном числе сегментов. Если исходное множество состоит из N элементов, тогда средняя длина списков будет N/B элементов. Если удается оценить величину N и выбрать B как можно ближе к этой величине, то в каждом списке будет один-два элемента. Тогда время выполнения операций с данными будет малой постоянной величиной, зависящей от N или от В. Однако не всегда ясно, как выбрать хеш-функцию h так, чтобы она примерно поровну распределяла элементы исходного множества по всем сегментам.
Идеальной хеш-функцией является такая, которая для любых двух неодинаковых ключей выдает неодинаковые адреса, т.е.

Однако подобрать такую функцию можно в случае, если все возможные значения ключей известны заранее. Такая организация данных носит название «совершенное хеширование». Если заранее не определено множество значений ключей, и длина таблицы ограничена, подбор совершенной функции затруднителен. Поэтому часто используют хеш-функции, которые не гарантируют выполнение условия (1).
Рассмотрим хеш-функцию, определенную на символьных строках, которая не является совершенной, однако значения h(x) будут «хорошими». Идея построения этой функции заключается в том, чтобы представить символы в виде целых чисел, используя для этого машинные коды символов. В языке Delphi есть встроенная функция ord(c), которая возвращает целочисленный код символа с. Таким образом, если х – это ключ, тип данных ключей определен как строка символов, тогда можно использовать хеш-функцию, код которой приведен ниже. В этой функции суммируются все целочисленные коды символов, результат суммирования делится на B и берется остаток от деления, который будет целым числом из интервала от 0 до B-1.

