 2015-04-12
2015-04-12 1731
1731В этом разделе рассматривается двухэтапная процедура построения нечетких моделей типа Сугэно. На первом этапе синтезируются нечеткие правила из экспериментальных данных с использование субтрактивной кластеризации. На втором этапе настраиваются параметры нечеткой модели с помощью ANFIS-алгоритма. Субтрактивная кластеризация может использоваться как быстрый автономный метод синтеза нечетких правил из данных. Кроме того, этот метод может рассматриваться как своего рода препроцессинг для ANFIS-алгоритма - синтезированная нечеткая модель является начальной точкой для обучения. Важным преимуществом применения кластеризации для синтеза нечеткой модели является то, что правила базы знаний получаются объектно-ориентированными. Это понижает возможность "комбинаторного взрыва" - катастрофического увеличения объема базы знаний при большом числе входных переменных. Изложение материала проводится на примере построения нечеткой модели зависимости количества автомобильных поездок из пригорода от его демографических показателей.
Исходные данные для моделирования были собраны из 100 транспортных зон округа Ньюкасл (Делавэр). Необходимо узнать как зависит количество автомобильных поездок, заказанных из района, от пяти его демографических показателей: количество жителей; количество домов; количество автомобилей, средний уровень доходов на один дом; уровень занятости населения. Синтезируемая нечеткая модель будет иметь один выход и пять входов.
Для загрузки данных необходимо напечатать команду tripdata. Сценарий tripdata создает в рабочей области несколько переменных. 75 из 100 пар данных "входы-выход" используются как обучающая выборка (переменные datin and datout). Для проверки генерализирующих свойств модели используется тестирующая выборка (переменные chkdatin и chkdatout), содержащая оставшиеся 25 пар данных. На рис. 10 приведена обучающая выборка. Эти графики построены командами:
subplot(2,1,1), plot(datin);
subplot(2,1,2), plot(datout);
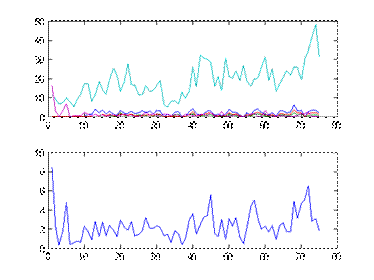
Рисунок 10 - Обучающая выборка: демографические показатели района (вверху) и количество автомобильных поездок (внизу)
Функция genfis2 синтезирует нечеткую модель типа Сугэно с использование субтрактивной кластеризации. При вызове этой функции необходимо указать радиусы кластеров. Радиусы определяют насколько далеко от центра кластера могут быть его элементы. Значения радиусов должны находится в диапазоне [0, 1] в связи с тем, что при кластеризации исходные данные масштабируется на единичный гиперкуб. Обычно малые значения радиусов приводят к нахождению множества мелких кластеров, и, следовательно, к очень детализированной базе нечетких правил. Большие значения радиусов приводят к нахождению всего нескольких крупных кластеров и тем самым обеспечивают компактную базу знаний. Однако при этом можно упустить некоторые особенности моделируемой зависимости. Как правило, хорошие нечеткие базы знаний синтезируют при значениях радиусов из диапазона [0.2, 0.5]. Радиусы кластеров задаются третьим аргументом функции genfis2. Будем считать, что в кластерном анализе все координаты являются равноважными, поэтому значение этого аргумента можно задать скаляром. Следующая команда вызывает функцию genfis2 при значении радиусов кластера равных 0.5: fis=genfis2(datin,datout,0.5).
Используемый функцией genfis2 горный метод субтрактивной кластеризацией позволяет быстро экстрагировать нечеткие правила из данных. Это однопроходный метод, не использующий итерационных процедур оптимизации. В результате выполнения вышеприведенной команды синтезируется нечеткая модель Сугэно первого порядка с тремя правилами. Для вычисления ошибки моделирования на обучающей выборке вызовем следующие команды:
fuzout=evalfis(datin,fis);
trnRMSE=norm(fuzout-datout)/sqrt(length(fuzout))
В результате получим значение корня квадратного из средней квадратической невязки равное: trnRMSE = 0.5276. Теперь проверим как работает модель вне точек обучения ‑ на тестирующей выборке. Для этого выполним аналогичные команды для тестирующей выборки:
chkfuzout=evalfis(chkdatin,fis);
chkRMSE=norm(chkfuzout-chkdatout)/sqrt(length(chkfuzout))
Значение ошибки на тестирующей выборке равно: chkRMSE = 0.6170. Неудивительно, что ошибка на тестирующей выборке больше, чем на обучающей. Сравним экспериментальные данные из тестирующей выборки с результатами нечеткого моделирования применяя команды:








