2015-04-01
2015-04-01 785
785Рассмотрим построение конечного автомата (процессора), который по представленному входному слову с концевым маркером устанавливает его идентичность некоторому элементу множества.
Пример:
Возможная организация лексического блока
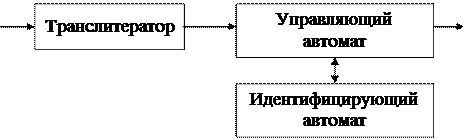 |
Управляющая программа знает, что некоторая цепочка букв, появившаяся в некотором месте программы, должна быть словом, и подает эти буквы на вход идентифицирующего конечного автомата для анализа. Когда управляющий автомат обнаруживает, что слово кончилось, он посылает на вход идентифицирующего автомата концевой маркер. Предполагаем, что буквы уже переведены в символьные лексемы типа (БУКВА, значение). Под действием входного символа буква управляющий автомат передает значение этой буквы на вход идентифицирующего автомата и сам совершает определенный переход. Если идентифицирующий автомат использовать таким образом, то язык должен быть таким, чтобы управляющий автомат узнавал какие входные символы, следуя друг за другом, образуют слово.
Автомат, идентифицирующий некоторое множество слов может быть построен путем введения в него состояния для любой подцепочки, которая может быть префиксом какого-либо слова из этого множества. Множество префиксов включает в себя пустую цепочку, которая служит префиксом для всех слов, а также сами заданные слова.
Пример:
Построить конечный процессор, имеющий входной алфавит {О, Б, С, К, А, ð} для идентификации множества {ОСА, БОК, БОКА, БАК}.
| О | Б | С | К | А | ð | |
| e | О | Б | ||||
| О | ОС | |||||
| Б | БО | БА | ||||
| ОС | ОСА | |||||
| БО | БОК | |||||
| БА | БАК | |||||
| ОСА | «ОСА» | |||||
| БОК | БОКА | «БОК» | ||||
| БАК | «БАК» | |||||
| БОКА | «БОКА» |
Элементы таблицы в кавычках означают, что автомат идентифицировал соответствующее слово. Пустые ячейки соответствуют выходам «слово Ï множеству». Сообщение об ошибке откладывается, пока слово не просмотрено полностью. Переходы не сопровождаются никакими действиями, кроме изменения состояния.
Вопросы и упражнения
Построить конечный процессор, имеющий входной алфавит {О, М, С, Ы, И, А, ð} для идентификации множества {САМ, СОМ, САМИ, СОМЫ, МЫС}.