 2015-04-01
2015-04-01 1075
1075Основная гипотеза данного подхода заключается в следующем: наилучшая энтропия кластерного разбиения достигается тогда, когда каждый кластер содержит всего один объект.
Сначала для каждого кластера j считается pij – вероятность того, что член кластера j принадлежит некоему классу i из заранее составленного экспертами распределения классов. Энтропия каждого кластера считается в соответствии с классической формулой:
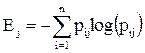 , (26)
, (26)
то есть сумма производится по всем предопределенным классам.
Полная энтропия набора кластеров вычисляется, как сумма энтропий кластеров, с учетом размеров кластеров [3]:
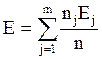 , (27)
, (27)
где nj – размер кластера j, m – количество кластеров, n – общее количество точек пространства.
F-мера
Эта мера объединяет в себе понятия точности и полноты, взятые из теории информационного поиска. Точность (precision) – это доля истинно релевантных (удовлетворяющих запросу) документов в общем числе найденных, и полнота (recall) – доля обнаруженных истинно релевантных документов [2].
Таким образом, можно считать каждый кластер результатом запроса, а каждый предопределенный экспертом класс документов – желаемым результатом запроса, то есть наилучшим по параметрам набором документов, возвращаемых в ответ на запрос. Далее мы подсчитываем значения полноты и точности этого кластера для каждого класса:
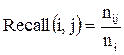 , (28)
, (28)
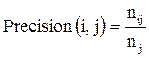 , (29)
, (29)
где j – кластер, i – класс, nij – количество членов класса i в кластере j, nj – количество членов кластера j и ni – количество членов класса i.
F-мера для кластера j и класса i затем задается, как [3]:
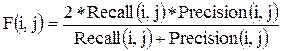 . (30)
. (30)
Для всего кластерного разбиения в случае иерархической кластеризации F-мера равна:
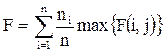 , (31)
, (31)
где максимум берется от всех кластеров на всех уровнях, n – количество документов.








