 2015-04-01
2015-04-01 976
976В отсутствии какой-либо дополнительной информации, такой как экспертное распределение документов на классы, внутреннее сходство кластеров, может использоваться как внутренняя мера качества. Это свойство дает нам возможность определить кластер как скопление точек в многомерном пространстве, относительно плотное по сравнению с иными областями этого пространства, которые либо вообще не содержат объектов, либо содержат их малое количество.
Иными словами, внутреннее сходство показывает, насколько данный кластер является компактным, или же наоборот – разреженным. Несмотря на достаточную очевидность этого свойства, однозначного способа вычисления такого показателя (плотности) не существует.
Однако, как правило, все функции внутреннего качества кластеров используют значение общего внутреннего сходства объектов внутри этих кластеров, то есть сумму всех значений мер близости для всех пар объектов, принадлежащих кластеру. Причем сходства могут быть не только локальными, основанными только на непосредственной близости объекта ко всем остальным, но и глобальными, зависящими также от общей разреженности пространства, количестве близлежащих объектов и так далее (ROCK, CHAMELEON). В этом случае говорят о внутренней связности кластера.
Мера внутреннего сходства для набора документов, входящих в кластер С (d, d’ – векторы документов, принадлежащих C), основанная на мере сходства косинуса [3] может быть попарной взвешенной (среднее внутреннее сходство):
 , (32)
, (32)
где |C| – количество векторов в кластере.
Надо сказать, это выражение равно ||c||2, то есть квадрату длины среднего вектора кластера, что значительно упрощает вычисление данной меры [3]. Стоит отметить, что если все документы d в кластере С тождественны друг другу, то среднее внутреннее сходство будет стремиться к 1, если наоборот, документы сильно различаются по смыслу, то среднее сходство будет близко к 0 [12].
Во всех вариантах, общее внутреннее сходство, как правило, усредняется с учетом размера кластера, что, в принципе, и позволяет говорить о плотности объектов внутри кластера, то есть о степени близости на 1 объект в кластере. Преимущество среднего внутреннего сходства перед общим внутренним сходством заключается в возможности использования его в качестве целевой функции на различных этапах алгоритмов кластеризации.
Добавление объекта в кластер всегда повышает общее внутренне сходство кластера, но может способствовать и его разрежению, уменьшению его плотности, если она основана на среднем внутреннем сходстве. Для алгоритмов иерархической кластеризации (актуальных для нашей задачи в первую очередь) такая функция позволяет сформировать подходящее правило объединения, дающее возможность на каждом шаге получать кластеры, обладающие наибольшей плотностью.
Эти меры в наибольшей степени чувствительны к характеристикам получаемых кластеров, потому что, в отличие от остальных, не используют априорного представления об их свойствах (о форме – сферическая, продолговатая или о размере – малый, крупный, равный). Такие ограничения, возникающие, как правило, в виду несовершенства методов объединения, мешают получать наиболее плотные кластеры, независимо от их формы и размера.
Мера внутреннего сходства может быть и невзвешенной центроидной [12]:
 . (33)
. (33)
Таким образом, можно посчитать общее качество разделения Q некоего разбиения {Cj}kj=1 набора документов (или поднабора):
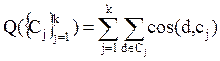 (34)
(34)
или
 , (35)
, (35)
где С1 … Сk – кластеры образующие оцениваемое разбиение. d – вектор документа, сj – средний вектор кластера Cj (центроид). Часто именно эта функция является целевой [12].
Также в качестве целевой функции может быть взята общая внутригрупповая сумма квадратов отклонения векторов документов d от средних векторов сj кластеров Сj [12]:
 . (36)
. (36)
Надо сказать, что, для задач кластеризации документов такая целевая функция способствует получению неудовлетворительных разбиений потому, что использует неадекватную для многомерных пространств Евклидову метрику.








