 2015-04-01
2015-04-01 590
590Обычно правила грамматики недостаточно полно описывает синтаксис входной программы. Например, ключевые слова являются цепочками символов, хотя в языке это терминалы, между словами языка в тексте программы может быть произвольное количество пробелов и т.д.
Для устранения этих проблем предложения исходной программы удобнее представлять в виде последовательности лексем - элементов языка, внутреннее строение которых несущественно при синтаксическом анализе. Например, лексемой может быть ключевое слово, имя переменной. константа и т. д. Просмотр исходного текста программы, распознавание и классификация различных лексем называется лексическим анализом.
Часть транслятора, которая выполняет лексический анализ, называется сканером. Сканер воспринимает исходный текст программы и преобразует его в последовательность лексем - промежуточный язык, удобный для синтаксического анализа. Кроме этого, сканер строит таблицы (массивы) идентификаторов и констант. Таким образом, основными функциями сканера являются:
· построение последовательности лексем;
· построение таблицы идентификаторов;
· построение таблицы констант;
· расстановка ссылок для передачи управления.
Для повышения эффективности последующих действий лексемы обычно представляются в виде пары (код, значение). На этапе синтаксического анализа используется первая компонента пары - код. Вторая компонента - значение, используется при семантических вычислениях. Для языка МИЛАН будем использовать определения лексем, представленные в табл. 1.1. Заметим, что при распознавании идентификаторов и констант сканером используются следующие правила грамматики:
I—>А|IА|IС,
K—>С|KC,
А—>а|b|...|z,
C—>0|1|…|9.
Таким образом, в последовательности лексем идентификаторы и константы становятся терминалами и грамматика языка упрощается.
Таблица 1.1
Лексемы языка МИЛАН
| Название лексемы | Код | Запись в языке | Обозначение | Значение |
| Служебные слова begin do else end fi if od output read then while | begin do else end fi if od output read then while | begin do else end fi if od output read then while | ||
| Точка с запятой | ; | tz | ||
| Знак отношения = <> < > >= <= | = <> < > >= <= | otn | ||
| + - | + - | ots | ||
| * / присваивание | * / := | out prsv | ||
| ( ) | ( ) | os zs | ||
| Идентификатор | A,B23 | id | Указатель на таблицу идентификаторов | |
| Константа без знака | 32, 0274 | int | Указатель на таблицу констант |
Рассмотрим синтаксическую диаграмму сканера (рис.1.1), который выполняет первые 3 функции: строит массив лексем, таблицы констант и идентификаторов.
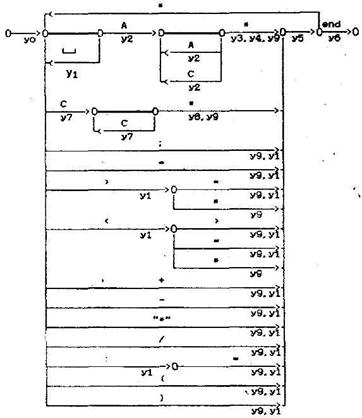
Рис.1.1. Синтаксическая диаграмма сканера
На рисунке приняты следующие обозначения семантических вычислений:
y0: подготовка (инициализация таблиц и переменных);
y1: прочитать следующий символ;
у2: накопление символов ключевого слова или идентификатора;
у3: проверка ключевого слова;
y4: проверка идентификатора;
y5: запись сформированной лексемы в массив лексем;
y6: завершение работы сканера;
y7: обработать цифру;
y8: запись константы в таблицу констант;
у9: формирование лексемы.
Пример. Рассмотрим текст программы, вычисляющей сумму пяти вводимых чисел: begin х:=0; n:=5; while n>0 do Z:=read; x:=x+z; n:=n-l od; output(x) end.
Результаты работы сканера:
1. Последовательность лексем:
| 1. (begin, 0) 2. (id, 1) 3. (prsv, 0) 4. (int, 1) 5. (tz, 0) 6. (id, 2) 7. (prsv,0) 8. (int,2) 9. (tz, 0) 10. (while, 0) 11. (id, 2) 12. (otn,2) | 13. (int, 1) 14. (do, 0) 15. (id.3) 16. (prsv, 0) 17. (read, 0) 18. (tz, 0) 19. (id,1) 20. (prsv, 0) 21. (id, 1) 22. (ots, 0) 23. (id,3) 24. (tz, 0) | 25. (id, 2) 26. (prsv, 0) 27. (id, 2) 28. (ots, 1) 29. (int, 3) 30. (od, 0) 31. (tz,0) 32. (output, 0) 33. (os, 0) 34. (id, 1) 35. (zs,0) 36. (end, 0) |
Массив идентификаторов: {x, n, z}.
Массив констант: {0, 5, 1}.
В языке МИЛАН имеются операторы, изменяющие линейный порядок вычислений. Это операторы цикла и развилки. Для организации правильных вычислений необходимо на некоторые лексемы поставить ссылки на номера лексем, куда будет передано управление при выполнении определенных условий. Такие ссылки будем записывать на место значения лексемы.
Для оператора цикла на лексему do необходимо поставить ссылку r - номер лексемы, следующей за лексемой od. На эту лексему будет передано управление, если условие цикла - ложь. Для лексемы od поставить ссылку s - номер лексемы while, увеличенный на 1.
Это лексема, с которой начинается условие цикла. На нее передается управление после выполнения тела цикла.
Для оператора развилки на лексему then необходимо поставить ссылку r - номер лексемы, стоящей после лексемы else в полной форме оператора развилки, и стоящей после лексемы fi в сокращенной форме. На эти лексемы передается управление при ложном условии оператора развилки.
Пример. После расстановки ссылок в последовательности лексем примера изменятся две лексемы: 14 (do,31) и 30 (od,11).
Алгоритм расстановки ссылок в общем случае должен обрабатывать вложенные структуры циклов и развилок. Для такой обработки необходимо использовать два независимых стека. Синтаксическая диаграмма алгоритма расстановки ссылок представлена на рис.1.2.
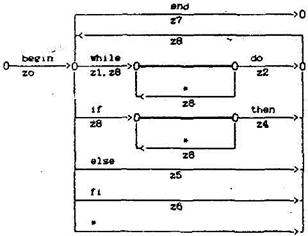
Рис.1.2. Алгоритм расстановки ссылок
Для описания семантических функций z0,z1,...,z8 введем обозначения: q - номер очередной рассматриваемой лексемы в массиве лексем; stack1,stack2 - стеки.
Семантические функции:
z0: инициализация стеков. q:>l. прочитать лексему q;
z1: значение q+1 занести в stack1;
z2: значение q занести в stack1;
z3: снять вершину стека stack1 в переменную s, снять вершину стека stack1 в переменную r, присвоить значение r лексеме с номером q, присвоить значение q+1 лексеме с номером s;
z4: значение q занести в stack2;
z5: снять вершину стека в переменную r. присвоить значение q+1 лексеме с номером r, занести в stack2 значение q;
z6: снять вершину стека в переменную r, значение q+1 присвоить лексеме с номером r;
z7: завершить работу;
z8: q:=q+l, прочитать очередную лексему с номером q.








