 2015-04-01
2015-04-01 483
483После лексической обработки и простановки ссылок последовательность лексем, массивы идентификаторов и констант поступают на обработку интерпретатору. Задача интерпретатора - распознать конструкции языка и выполнить действия, предписанные входной программой. Учитывая, что синтаксический разбор Судет производиться над массивом лексем, уточним грамматику языка МИЛАН, которая будет использована для синтаксического анализа последовательности лексем, множество терминалов в уточненной грамматике - это множество лексем.
1) W ->begin L end
2) L ->S|S;L
3) S ->I:=E | output(E) | while В do L od | if В then L fi| if В then L else L fi
4) В ->ЕОЕ
5) E ->T | NT | TNT | NTNT
6) T ->P | PMP
7) P -> I | K | read | (E)
8) I ->id(1)|...| id(m)
9) К ->int(1)|...|int(n)
10) O ->otn(0)|...|otn(5)
11) M ->otu(0)|otu(1)
12) N ->ots(0)|ots(1)
Здесь m и n - число идентификаторов и констант, * нетерминалы обозначают конструкции языка: W - <программа>, начальный символ грамматики; L - <последовательность операторов>; S - <оператор>; В - <условие>; Е - <выражение>; Т - <терм>; Р - <множитель>; К -<константа>; 0 - <знак отношения>; М - <операция типа умножения>; N - <операция типа сложения>; I - <идентификатор>.
Построим синтаксические диаграммы (рис.2.1).
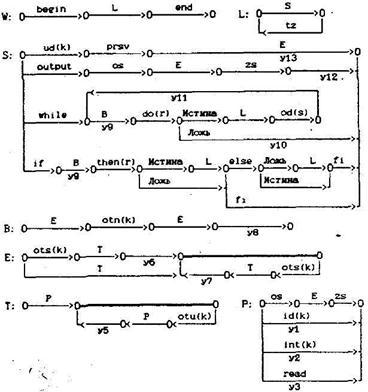
Рис.2.1. Диаграммы синтаксического анализатора
Из диаграмм видно, что грамматика языка является LL(1) грамматикой. Введем следующие обозначения: q - номер очередной лексемы, stack - стек для вычислений, к - значение лексемы.
Опишем семантические функции синтаксического анализатора:
y1: значение k-го идентификатора положить в stack, q:=q+l;
у2: k-ю константу положить в stack, q:=q+l;
y3: прочитать число с терминала и положить его в stack; q:=q+l;
у5: в переменную b снять со стека число, в переменную а снять со стека число, выполнить умножение или деление в зависимости от значения к лексемы otu. результат (a*b или а/b) занести в stack;
y6: если к=1, то снять число со стека, сменить знак этого числа и занести в stack, q:=q+1;
y7: в переменную b снять со стека число, в переменную а снять со стека число, выполнить сложение или вычитание в зависимости от значения k лексемы ots, результат (а+b или а-b) занести в stack;
у8: в переменную b снять со стека число, в переменную а снять со стека число, выполнить операцию сравнения a otn(k) b. результат (О - истина, 1 - ложь) занести в stack;
y9; в переменную b снять со стека число, если b=0, то это истина, иначе это ложь;
y10: перейти на лексему номер r, т.е. q:=r; y11; перейти на лексему номер s, т.е. q:=s;
у12: в переменную b снять со стека число, напечатать b;
y13: в переменную b снять со стека число, идентификатору с номером k присвоить значение b.
Пример. begin х:=2; у:-5; output(x+y) end.
Массив лексем:
| 1. (begin, 0) 2. (id, 1) 3. (prsv, 0) 4. (int, 1) 5. (tz, 0) 6. (id, 2) | 7. (prsv, 0) 8. (int, 2) 9. (tz, 0) 10. (output, 0) 11. (os, 0) 12. (id, 1) | 13. (ots, 0) 14. (id, 2) 15. (zs, 0) 16. (end, 0) |
Массивы идентификаторов и констант: {х, y}, {1, 2}.








