 2015-04-06
2015-04-06 2627
2627Такие системы не принято считать кластерами, но их принципы в значительной степени сходны с кластерной технологией. Их также называют grid-системами. Главное отличие — низкая доступность каждого узла, то есть невозможность гарантировать его работу в заданный момент времени (узлы подключаются и отключаются в процессе работы), поэтому задача должна быть разбита на ряд независимых друг от друга процессов. Такая система, в отличие от кластеров, не похожа на единый компьютер, а служит упрощенным средством распределения вычислений. Нестабильность конфигурации, в таком случае, компенсируется большим числом узлов.
7. Векторные и векторно-конвейерные ВС. Структура векторного процессора. Матричные ВС.
R В екторный процессор — это процессор, в котором операндами некоторых команд могут выступать упорядоченные массивы данных — векторы. Отличается от скалярных процессоров, которые могут работать только с одним операндом в единицу времени. Абсолютное большинсто процессоров являются скалярными или близкими к ним. Векторные процессоры были распространены в сфере научных вычислений, где они являлись основой большинства суперкомпьютеров начиная с 1980-х до 1990-х. Но резкое увеличение производительности и активная разработка новых процессоров привели к вытеснению векторных процессоров со сферы повседневных процессоров.
R В екторное АЛУ можно представить так:

 Входные векторы
Входные векторы
 |
Векторное АЛУ
Такая машина на входе получает два n -элементных вектора и обрабатывает соответствующие элементы параллельно, используя векторное АЛУ, которое может оперировать n элементами одновременно. В результате получается вектор. Входные и выходные векторы могут сохраняться в памяти или в специальных векторных регистрах.
Векторные компьютеры применяются и для скалярных (невекторных) операций, а также для смешанных векторно-скалярных операций.
Типичный пример — умножение каждого элемента вектора на константу. Иногда быстрее переделать скалярный операнд в вектор, каждое значение которого равно скалярному операнду, а затем выполнить операцию над двумя векторами.
R М атричные вычислительные системы (ВС) обладают более широкими архитектурными возможностями, чем конвейерные ВС: их каноническая архитектура относится к типу SIMD.
Матричные ВС предназначаются для решения сложных задач, связанных с выполнением операций над векторами, матрицами и массивами данных (Data Arrays).
Наиболее распространенными из систем класса один поток команд – множество потоков данных (SIMD) являются матричные системы, которые лучше всего приспособлены для решения задач, характеризующихся параллелизмом независимых объектов или данных. Организация систем подобного типа, на первый взгляд, достаточно проста. Они имеют общее управляющее устройство, генерирующее поток команд и большое число процессорных элементов, работающих параллельно и обрабатывающих каждая свой поток данных. Таким образом, производительность системы оказывается равной сумме производительностей всех процессорных элементов. Однако на практике чтобы обеспечить достаточную эффективность системы при решении широкого круга задач, необходимо организовать связи между процессорными элементами с тем, чтобы наиболее полно загрузить их работой. Именно характер связей между процессорными элементами и определяет разные свойства системы.
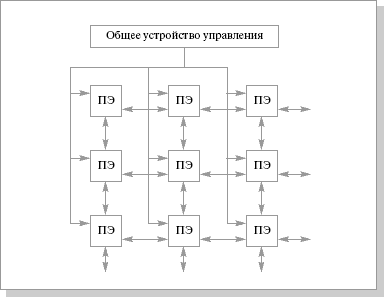
Одним из первых матричных процессоров был SОLОМОN (60-е годы). Система SOLOMON содержит 1024 процессорных элемента, которые соединены в виде матрицы: 32х32. Каждый процессорный элемент матрицы включает в себя процессор, обеспечивающий выполнение последовательных поразрядных арифметических и логических операций, а также оперативное ЗУ емкостью 16 Кбайт. По каналам связи от устройства управления передаются команды и общие константы. В процессорном элементе используется так называемая многомодальная логика, которая позволяет каждому процессорному элементу выполнять или не выполнять общую операцию в зависимости от значений обрабатываемых данных. В каждый момент все активные процессорные элементы выполняют одну и ту же операцию над данными, хранящимися в собственной памяти и имеющими один и тот же адрес.
8. Симметричные (SMP) многопроцессорные ВС. Параллельные ВС-МВК «Эльбрус». Процессор Е2К (Эльбрус-2000).
R Е сли все процессоры имеют равный доступ ко всем модулям памяти и всем устройствам ввода-вывода и каждый процессор взаимозаменим с другими процессорами, то такая система называется SMP (Symmetric Multiprocessor — симметричный мультипроцессор).
Размер мультипроцессоров UMA с одной шиной обычно ограничивается до нескольких десятков процессоров, Чтобы получить более 100 процессоров, нужно что-то предпринять. Отметим, что все модули памяти имеют одинаковое время доступа.
Это наблюдение приводит к разработке мультипроцессоров NUMA (NonUniform Memory Access — с неоднородным доступом к памяти). Как и мультипроцессоры UMA, они обеспечивают единое адресное пространство для всех процессоров, но, в отличие от машин UMA, доступ к локальным модулям памяти происходит быстрее, чем к удаленным.
Машины NUMA имеют три ключевые характеристики, которыми все они обладают и которые в совокупности отличают их от других мультипроцессоров:
1. Существует одно адресное пространство, видимое для всех процессоров.
2. Доступ к удаленной памяти производится с использованием команд LOAD и STORE.
3. Доступ к удаленной памяти происходит медленнее, чем доступ к локальной памяти.
Если кэш-память отсутствует, то такая система называется NC-NUMA (No Caching NUMA — NUMA без кэширования). Если присутствуют согласованные кэши, то система называется CC-NUMA (Coherent Cache NUMA — NUMA с согласованной кэш-памятью).
R Э льбрус – серия советских супер-ЭВМ, разработанных в Институте точной механики и вычислительной техники (ИТМиВТ) в 1970-х — 1990-х гг.
Основным отличием системы Эльбрус является ориентация на языки высокого уровня 1980-х годов. Языки класса Ассемблер в системе отсутствуют. Базовый язык — Автокод Эльбрус Эль-76 (автор В. М. Пентковский), на котором написано общее программное обеспечение (ОСПО), является языком класса Алгол. Он напоминает язык Алгол-68, основное различие состоит в динамическом связывании типов, которое поддержано на аппаратном уровне. При компиляции программа на Эль-76 переводилась в безоперандные команды стековой архитектуры.
R П одход, близкий к IA-64, уже был реализован в России - в произведенном в единственном экземпляре суперкомпьютере Эльбрус-3, выпущенном в 1991 году.
9. Системы массовой параллельной обработки (МРР). Супер ЭВМ фирмы SGI - Cray T3E(T3D) -1200.
R M PP (massive parallel processing) – массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), коммуникационные процессоры (рутеры) или сетевые адаптеры, иногда – жесткие диски и/или другие устройства ввода/вывода. По сути, такие модули представляют собой полнофункциональные компьютеры. Доступ к банку ОП из данного модуля имеют только процессоры (ЦП) из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами.
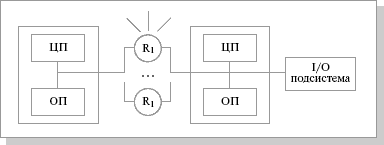
Схематический вид архитектуры с раздельной памятью
Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодня устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (ASCI Red, ASCI Blue Pacific).
Недостатки:
- отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами. Требуется специальная техника программирования для реализации обмена сообщениями между процессорами;
- каждый процессор может использовать только ограниченный объем локального банка памяти;
- вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально использовать системные ресурсы. Именно этим определяется высокая цена программного обеспечения для массивно-параллельных систем с раздельной памятью.
R СRAY T3D
 | Компьютер CRAY T3D - это массивно-параллельный компьютер с распределенной памятью, объединяющий от 32 до 2048 процессоров. Распределенность памяти означает то, что каждый процессор имеет непосредственный доступ только к своей локальной памяти, а доступ к данным, расположенным в памяти других процессоров, выполняется другими, более сложными способами. CRAY T3D подключается к хост-компьютеру (главному или ведущему), роль которого, в частности, может исполнять CRAY Y-MP C90. Вся предварительная обработка и подготовка программ, выполняемых на CRAY T3D, проходит на хосте (например, компиляция). Связь хост-машины и T3D идет через высокоскоростной канал передачи данных с производительностью 200 Mбайт/с. Массивно-параллельный компьютер CRAY T3D работает на тактовой частоте 150MHz и имеет в своем составе три основные компоненты: сеть межпроцессорного взаимодействия (или по-другому коммуникационную сеть), вычислительные узлы и узлы ввода/вывода. |

