2015-04-30
2015-04-30 1157
1157Факторный анализ служит для понижения размерности пространства входных факторов. Обработку можно выполнять как в автоматическом
режиме (с указанием порога значимости), так и вручную (основываясь на значениях матрицы значимости).
1) Рассмотрим применение обработчика на примере данных из файла
Anketa1.txt. Он содержит таблицу с информацией о кредитах граждан.
Выявим значение факторов, влияющих на возврат кредита. Выполните импорт текстового файла Anketa1.txt
При импорте указываем следующие параметры (рис. 1.34):
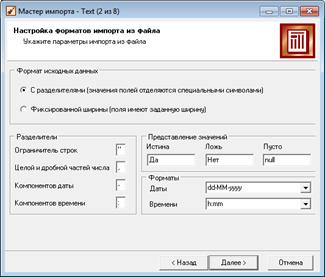
Рисунок 1.34 – Настройка параметров импорта
Обратите внимание на типы данных (рис. 1.35).
В качестве средства визуализации выбираем таблицу (рис. 1.36).
2) В Мастере обработки выберем Факторный анализ и зададим входные поля – Личный доход в месяц, Сумма кредита, Стаж работы, Рыночная стоимость автомобиля, Рыночная стоимость недвижимости, Количество лет проживания в регионе (рис. 1.37).
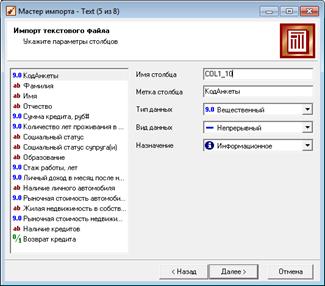
Рисунок 1.35 – Настройка типов данных
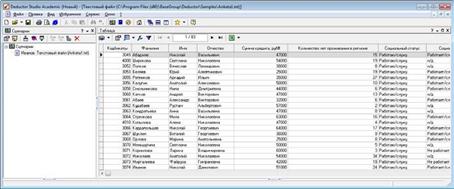
Рисунок 1.36 – Таблица с данными
3) На следующем шаге предлагается запустить процесс понижения размерности пространства входных факторов. После завершения процесса можно выбрать, какие из полученных в результате обработки факторы оставить для дальнейшей работы. Это делается путем указания необходимого порога значимости (рис. 1.38).
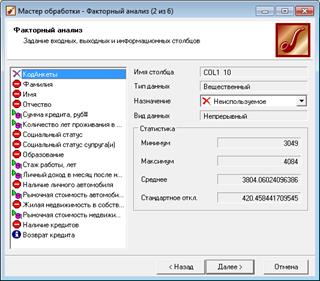
Рисунок 1.37 – Факторный анализ при помощи Мастера обработки
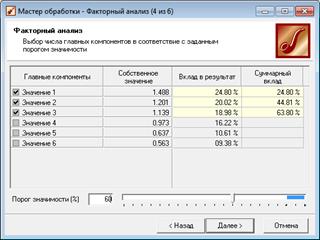
Рисунок 1.38 – Изменение порога значимости при помощи Мастера обработки
4) Теперь необходимо перейти к следующему шагу и выбрать способ визуализации; результаты просмотрим в таблице (рис. 1.39).
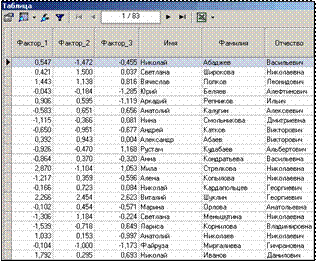
Рисунок 1.39 – Результаты визуализации
Для получения такого рода визуализации необходимо выполнить настройку полей и установить для факторов число десятичных знаков равное трем (рис. 1.40).
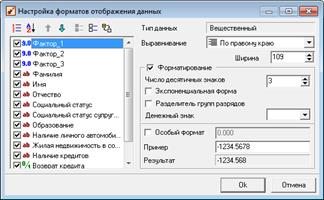
Рисунок 1.40 – Настройка параметров визуализации
Результаты сохранить в файле L1_7.ded.