2015-04-30
2015-04-30 2050
2050Одна из серьезных проблем, часто встречающаяся на практике, –
наличие в данных дубликатов и противоречий.
Противоречивыми являются группы записей, в которых содержатся строки с одинаковыми входными факторами, но разными выходными. В такой ситуации непонятно, какое результирующее значение верно. Если противоречивые данные использовать для построения модели, то она окажется неадекватной. Поэтому противоречивые данные чаще всего лучше вообще исключить из исходной выборки.
Также в данных могут встречаться записи с одинаковыми входными факторами и одинаковыми выходными, т.е. дубликаты. Таким образом, данные несут избыточность. Присутствие дубликатов в анализируемых данных можно рассматривать как способ повышения «значимости» дублирующийся информации. Иногда они даже необходимы, например, если при построении модели нужно особо выделить некоторые наборы значений. Но все равно включение в выборку дублирующей информации должно происходить осознанно: в большинстве случаев дубликаты в данных являются следствием ошибок при подготовке данных.
Так или иначе, возникает задача выявления дубликатов и противоречий. В Deductor Studio для автоматизации этого процесса есть соответствующий инструмент – обработка Дубликаты и противоречия.
Суть обработки состоит в том, что определяются входные (факторы) и выходные (результаты) поля. Алгоритм ищет во всем наборе записи, для которых одинаковым входным полям соответствуют одинаковые (дубликаты) или разные (противоречия) выходные поля. На основании этой информации создаются два дополнительных логических поля – Дубликат и Противоречие, принимающие значения «правда» или «ложь». В дополнительные числовые поля Группа дубликатов и Группа противоречий записываются номер группы дубликатов и группы противоречий, в которые попадает данная запись. Если запись не является дубликатом или противоречием, то соответствующее поле будет пустым.
1) Рассмотрим механизм выявления дубликатов на примере данных файла Anketa.txt. В этом файле находится информация об анкетных данных граждан, участвующих в кредитовании. Попробуем вычислить присутствие дубликатов.
Импортируем в новом проекте данные из текстового файла и посмотрим их в виде таблицы (рис. 1.45).
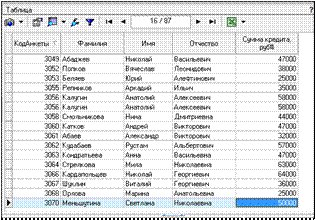
Рисунок 1.45 – Данные после импорта
2) Поиск дубликатов и противоречий.
Для выявления дубликатов запустим Мастер обработки. В нем выберем тип обработки Дубликаты и противоречия (рис. 1.46).
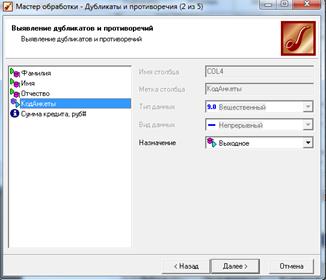
Рисунок 1.46 – Выбор типа обработки
На втором шаге Мастера необходимо настроить назначение полей.
3) На следующем шаге необходимо запустить процесс обработки.
4) После завершения выявления дубликатов просмотрим результат в виде таблицы дубликатов и противоречий.
Опции визуализатора Дубликаты и противоречия:
–  включение данной опции позволяет отображать в таблице строки, не являющиеся дубликатами или противоречиями;
включение данной опции позволяет отображать в таблице строки, не являющиеся дубликатами или противоречиями;
–  включение данной опции позволяет отображать в таблице строки, содержащие дубликаты (рис. 1.47).
включение данной опции позволяет отображать в таблице строки, содержащие дубликаты (рис. 1.47).
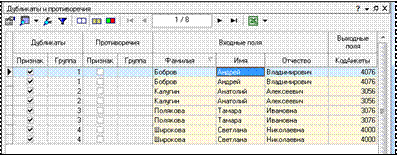
Рисунок 1.47 – Отображение в таблице дубликатов
 –
–  включение данной опции позволяет отображать в таблице строки, содержащие противоречия (рис. 1.48).
включение данной опции позволяет отображать в таблице строки, содержащие противоречия (рис. 1.48).
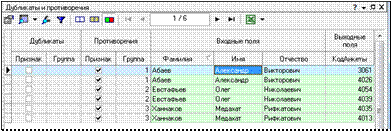
Рисунок 1.48 – Отображение в таблице противоречий
Результат сохранить в файле L1_9.ded.
Вопросы для проверки
1. Как работает обработчик Сортировка?
2. Можно ли отсортировать набор данных по нескольким полям?
3. Для чего предназначен узел Замена данных?
4. Как определить в Мастере обработки, что для поля настроена замена?
5. Как работает Замена данных?
6. Какие существуют способы заполнить таблицу подстановок?
7. Для чего предназначен узел Фильтр?
8. Какие условия фильтрации существуют?
9. Что делать, если нужно поставить фильтр по значению, которого в данный момент нет в рассматриваемом наборе данных?