 2015-04-30
2015-04-30 1528
1528Почти всегда исходный набор данных или набор данных после обработки аналитику нужно отфильтровать. Фильтрация бывает необходима для разбиения данных на какие-либо группы (например, товарные) для последующей обработки или анализа данных уже отдельно по каждой группе. Также некоторые данные могут не подходить для дальнейшего анализа в силу накладываемых условий (например, если на каком-либо этапе обработки данных были выявлены противоречивые записи, то их следует исключить из последующей обработки). В этом случае также возникает необходимость фильтрации записей.
Фильтрация позволяет из исходного набора данных получить новую таблицу, удовлетворяющую условиям, которые определены аналитиком. В Deductor Studio механизм построения условий фильтрации прост для понимания. В окне Мастера можно задать несколько элементарных условий фильтрации (<ПОЛЕ> <ОТНОШЕНИЕ> <ЗНАЧЕНИЕ>), последовательно связанных логическими операциями (И, ИЛИ).
Рассмотрим ситуацию, когда аналитику необходимо оценить кредитоспособность потенциального заемщика. Предполагается, что заемщики, берущие суммы разного диапазона, ведут себя по-разному, следовательно, модели прогноза должны быть свои для каждой группы, т.е. для дальнейшего построения моделей оценки кредитоспособности различных категорий заемщиков необходимо использовать фильтрацию.
1) Воспользуемся данными файла Credit.txt (исходная ветвь – Иванов. Преобразование даты из файла L2_1.ded).
2) Выполнение фильтрации данных.
Определим для примера группу заемщиков, взявших кредит менее
10 000 руб.
Для этого, находясь на узле импорта данных, из текстового файла запустим Мастер обработки. В нем в качестве метода обработки выберем фильтрацию. На втором шаге Мастера задаем условия фильтрации (при необходимости их можно добавлять или удалять соответствующими кнопками на форме). Поскольку необходимо отфильтровать данные только по заемщикам, взявшим кредит менее 10 000, то в графе Имя поля выбираем поле Сумма кредита, в графе Условие – знак меньше, а в графе Значение пишем 10000 (рис. 2.22).
3) Больше никаких условий не требуется, поэтому переходим на следующий шаг Мастера и запускаем процесс фильтрации. После выполнения обработки можно манипулировать уже только с данными по заемщикам выбранного кредитного диапазона.
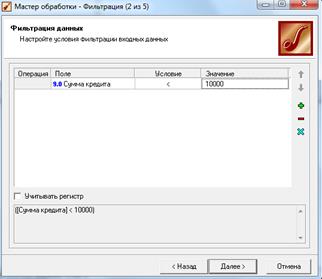
Рисунок 2.22 – Настройка фильтрации данных
В правильности выполненной операции можно легко убедиться, выбрав в качестве визуализации данных Статистику и просмотрев значения минимального и максимального значения поля Сумма кредита (рис. 2.23).
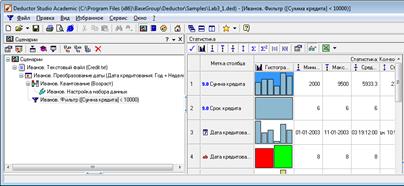
Рисунок 2.23 – Визуализатор данных Статистика
Результат сохранить в том же файле L2_1.ded.

