 2015-04-23
2015-04-23 434
434Данные таблицы вводим в блок А1:А11 (данные вводим вместе с заголовком).
| Y (рост студента) |
Далее, указав курсором мыши на пункт меню Сервис, выбираем команду Анализ данных. Затем в появившемся списке Инструменты анализа выбираем строку Описательная статистика. В появившемся диалоговом окне (рис. 3.2) указываем входной диапазон – А1:A11. В разделе Группирование: переключатель устанавливается в положение по столбцам. Ставим флажок Метки в первой строке. Указываем выходной диапазон – ячейку С1. Устанавливается флажок в поле Итоговая статистика и флажок Уровень надежности и вероятность 95 % (данный флажок позволит нам определить полуширину доверительного интервала для заданной доверительной вероятности)и нажимаем кнопку ОК.
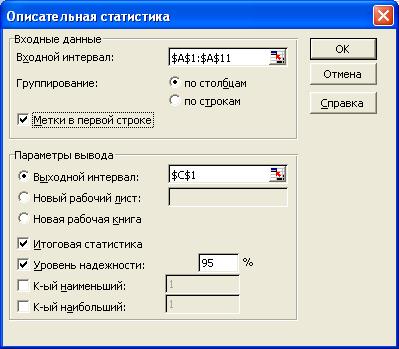
Рис. 3.2
В полученной таблице нас будет интересовать, в первую очередь, последняя строка, т.к. она отображает величину доверительного интервала.
В результате анализа в указанном выходном диапазоне для указанного столбца данных получим:
| Y(рост студента) | |
| Среднее | |
| Стандартная ошибка | 1,849924923 |
| Медиана | 174,5 |
| Мода | |
| Стандартное отклонение | 5,849976258 |
| Дисперсия выборки | 34,22222222 |
| Эксцесс | -0,884972171 |
| Асимметричность | 0,437064711 |
| Интервал | |
| Минимум | |
| Максимум | |
| Сумма | |
| Счет | |
| Уровень надежности(95,0%) | 4,184820908 |
Из таблицы следует, что значение полуширины доверительного интервала равно 4,18 для доверительной вероятности 95 %.
Нахождение доверительного интервала
и доверительной вероятности с помощью
самостоятельно введенных формул
Рассмотрим случай когда задана доверительная вероятность Р и необходимо найти доверительный интервал, который
а) накрывает отдельное значение случайной величины;
б) накрывает математическое ожидание случайной величины.








