 2015-05-18
2015-05-18 1157
11571. Уравнение множественной линейной регрессии имеет вид:
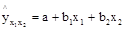 ,
,
где 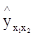 – урожайность зерновых с 1 га, ц;
– урожайность зерновых с 1 га, ц;
х1 – внесено органических удобрений на 1 га, ц;
х2 – насыщенность севооборота, %;
а, b1 и b2 – параметры уравнения.
Для расчета параметров а, b1 и b2 сначала построим уравнение множественной регрессии в стандартизированном масштабе:
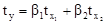
где 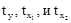 - стандартизированные переменные;
- стандартизированные переменные;
β1 и β2 – стандартизированные коэффициенты регрессии.
Стандартизированные коэффициенты регрессии определим по формулам:
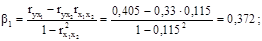
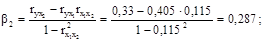
Уравнение множественной регрессии в стандартизированной форме имеет вид:
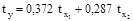 .
.
Стандартизированные коэффициенты регрессии позволяют сделать заключение о сравнительной силе влияния каждого фактора на урожайность зерновых. Более значимое влияние оказывает первый фактор, а именно, количество внесенных органических удобрений. В целом же можно сказать, что влияние факторов на урожайность практически одинаково.
Для построения уравнения в естественной форме рассчитаем b1 и b2, используя формулы перехода от βi к bi:
независимо от истинного закона распределения Xj. Наиболее часто используемая множественная линейная модель регрессионного анализа имеет вид:
у = b0 + b1∙xi1 + b2∙xi2 +...+ bj∙xij +...+ bk∙xik.
Отметим, что эта модель линейна относительно неизвестных параметров b0, b1, b2,..., bj,..., bkи аргументов. Коэффициент регрессии bj показывает, на какую величину в среднем изменится результативный признак Y, если переменную Xj увеличить на единицу измерения, т.е. является нормативным коэффициентом.
Классическая линейная регрессионная модель с одной переменной – это модель вида:
уi = b0 + b1∙x + u,
в которой x – детерминированная (неслучайная) величина, u – случайная составляющая; у – результативный признак.
Статистическую значимость уравнения регрессии определяют с помощью F-критерия Фишера. Наблюдаемое (фактическое) значение находится по формуле:
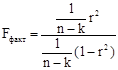
Найденное значение сравнивается с табличным (приложение 2). Если фактическое значение критерия больше табличного, то это свидетельствует о статистической значимости уравнения регрессии в целом и показателя тесноты связи r, то есть они статистически надежны и сформировались под неслучайным воздействием фактора х.
Оценить качество модели регрессии можно с помощью средней ошибки аппроксимации:
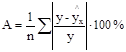
Чем меньше рассеяние эмпирических точек вокруг теоретической линии регрессии, тем меньше средняя ошибка аппроксимации. Ошибка аппроксимации меньше 7% свидетельствует о хорошем качестве модели.
Коэффициент эластичности характеризует силу связи фактора х с результатом у, показывающий, на сколько процентов изменится значение у при изменении значения фактора х на 1%. Средний коэффициент эластичности линейной зависимости можно рассчитать по следующей формуле:

Обобщающий коэффициент эластичности показывает, на сколько процентов изменится у относительно своего среднего уровня при росте х на 1% относительно своего среднего уровня.

