 2015-05-18
2015-05-18 3505
3505АНАЛИЗ ЭМПИРИЧЕСКИХ ДАННЫХ
Анализ собранной информации - самый увлекательный этап исследования. Мы проверяем, насколько верны были исходные предположения, получаем ответы на заданные вопросы и выявляем новые проблемы. Методологический инструмент анализа — гипотезы, сформулированные в программе, и те, что возникают по мере их проверки и отвержения уже в процессе анализа собранных данных.
Вспомним, что гипотезы подразделяются на описательные и объяснительные. Соответственно этому выделим два класса процедур анализа. К первому отнесем дескриптивные процедуры: группировку, классификацию и типологизацию. Второй класс образуют аналитико-экспериментальные процедуры, назначение которых - установление связей взаимодействия и детерминации.
ГРУППИРОВКА И ТИПОЛОГИЗАЦИЯ
Простая группировка - это классификация или упорядочение данных по одному признаку. Связывание фактов в систему осуществляется здесь в соответствии с описательной гипотезой относительно ведущего признака группировки (или признака классификации). Так, в зависимости от гипотез можно сгруппировать выборочную совокупность по возрасту, полу, роду занятий, образованию, по высказанным суждениям и т.д.
Квантифицированные данные или количественные показатели группируются в ранжированные ряды по возрастанию (убыванию) признака, качественные или атрибутивные группируются по принципу построения неупорядоченных номинальных шкал.
Все операции последующего анализа покоятся на изучении сгруппированных данных.
Число членов группы называют частотой или численностью группы, а отношение данной численности к общему числу наблюдений - долей или относительной частотой. Статистические приемы поиска средней тенденции (мода, медиана, среднеарифметическая), подсчет дисперсии отклонения позволяют оценить сгруппированный ряд в емком показателе и отобразить результаты графически (с. 90, рис. 6). Простейший анализ группировки — исчисление частот по процентам.
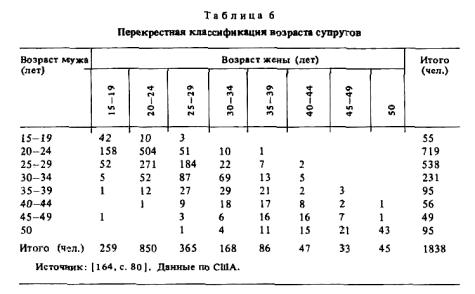
Перекрестная группировка (или перекрестная классификация) — это связывание фактов предварительно упорядоченных по двум признакам (свойствам, показателям) с целью: (а) обнаружить какие-то взаимозависимости, (б) осуществить взаимоконтроль показателей (например, ответов на основной и контрольный вопросы — с, 112, схема 18), сформировать новый составной показатель (индекс) на основе совмещения двух свойств или состояний объекта, определить (об этом ниже) направление связей влияния одного явления (характеристики, свойства) на другое.
Перекрестная классификация (группировка) производится в таблицах, где указывается наименование таблицы, (какие признаки, свойства сопрягаются) и общая численность включенных в группировку объектов (см. схему 8, с. 89).
Одна из задач перекрестной классификации: поиск устойчивых связей, выявляющих структурные свойства изучаемого явления. Например, можно выявить типические соотношения возрастов мужей и жен (табл. 6).
Мужья в большинстве случаев старше жен. Так, из 719 мужчин в возрасте 20-24 лет 158 (21%) имеют супруг моложе себя, а 62 (8,6%) -старше. Из 850 женщин в том же возрасте только 10 старше своих мужей, но в 336 случаях (39,5%) они моложе мужей.
Табл. 7 иллюстрирует использование перекрестной группировки для установления зависимости между предметной областью научного знания и длительностью "полужизни" публикаций (последняя определяется как период сокращения ссылок вдвое сравнительно с первоначальным периодом). Из таблицы видно, что наибольшим "долголетием" обладают публикации по экономике, наименьшим - в ряде естественнонаучных экспериментальных дисциплин и в математике.

Наконец, типичный случай использования перекрестной группировки — поиск тенденции, динамики процесса (табл. 8). Приведенные в табл. 8 данные хорошо иллюстрируются графически (рис. 13).
Эмпирическая типологизация — наиболее сильный прием анализа по описательному плану. Этот метод можно характеризовать как поиск устойчивых сочетаний свойств социальных объектов (или явлений), рассматриваемых в соответствии с описательными гипотезами в нескольких измерениях одновременно.
Так, нетрудно вообразить свойства социальной группы в трехмерном физическом пространстве, т.е. в декартовой системе координат. Скажем, свойство А будем откладывать в "высоту", свойство В - в "ширину", а С - в "длину".
Более сложная задача - проанализировать степень скопления или рассеяния признаков (свойств) в многомерном пространстве. Такое пространство нельзя наглядно представить в трехмерной системе координат, его можно описать в математических символах. Задачи многомерной эмпирической типологизации свойств решают с помощью математических процедур распознавания образов - таксономии, причем в этом случае исходные данные могут быть представлены в упорядоченных (метрических также) или в неупорядоченных шкалах.
Теоретическая типологизация - обобщение признаков социальных явлений на основе идеальной теоретической модели и по теоретически обоснованным критериям. Такая типология отличается от рассмотренной выше, где устойчивость свойств типа находится путем многократного перебора, тогда как в теоретической типологии критерии свойств выявляются путем логического анализа.
В современной логике существует понятие "идеализированный" (идеальный) объект, которым обозначают реальный объект или целый класс объектов, отраженных в сознании в виде некоторой абстракции, идеальной системы, воспроизводящей его в упрощенном, схематизированном виде [285, с. 151-156].
Идеальная социальная модель строится на основе абстракций двоякого рода: тех, что логически вытекают из более общих социологических понятий или принципов, а также абстракций на основе наблюдения эмпирических данных. Разумеется, и те и другие имеют своей посылкой реальную действительность. Именно потому, что конструированная таким путем идеальная модель соотносится с системой теоретического знания, она выполняет важные функции включения теории в непосредственный анализ эмпирических данных.
Модель такого рода обладает рядом особенностей: она определяет идеальные (в смысле абстракции) границы социального объекта; включает критерии (или параметры), на основе которых определяется жесткая, устойчивая связь его свойств и характеристик; если параметры, составляющие модель, представляют континуумы, фиксируются также количественные границы идеализированного объекта.
Анализ эмпирических данных, согласно теоретической типологии, предполагает, во-первых, определение частот распределения по каждому типу; во-вторых, изучение отклонений от идеализированных моделей по отдельным параметрам и, если возможно, измерение интенсивности и вероятности этих отклонений [295].
Короче говоря, метод теоретической типологизации ведет к объяснению, тогда как эмпирическая типологизация допускает лишь описание полученных данных и их интерпретацию.
2. ПОИСК ВЗАИМОСВЯЗЕЙ МЕЖДУ ПЕРЕМЕННЫМИ
Перекрестная группировка по двум и более признакам — прямой путь к обнаружению возможных связей взаимодействия между переменными. Для этого нужно составить таблицу определенным образом, например, подсчитать пропорции частот одного признака в зависимости от частот другого.
Правила процентирования — вовсе не так просты, как может показаться неопытному исследователю. Основной вопрос: принимать ли за 100% данные по строке или по столбцу? Это зависит от двух обстоятельств: от характера выборки обследованных и от логики анализа. Выборка может быть либо репрезентативной (выборочная совокупность есть микромодель генеральной совокупности), либо нерепрезентативной. В последнем случае нам как минимум неизвестны пропорции существенных характеристик в генеральной совокупности, или мы знаем, что эти пропорции в выборке не соблюдаются. Возможна двоякая логика анализа "от причин к следствию" или "от следствий к причинам", что определяется гипотезой и содержанием данных.
Если выборка представительна и отражает пропорции изучаемых групп в генеральной совокупности (данного завода, например), тогда можно вести двоякий анализ данных: по логике "от причин к следствию" и "от следствия к причинам ".
Если выборка нерепрезентативна, процентирование можно вести только в рамках каждой подвыборки раздельно. Обычно такие подвыборки образуют по признакам, являющимся возможными причинами искомых связей: половозрастные, профессионально-квалификационные, группы по уровню образования, другим объективным характеристикам социального статуса, места проживания и т.д. Здесь несоответствие долей подвыборок реальному распределению выделенных групп в генеральной совокупности не исказит вывод (логика табл. 10 а). В противном же случае (по логике табл. 106) достоверность вывода будет прямо зависеть от уровня представительности выборки.
Наконец, в случаях, когда представительность перекрестной классификации в принципе нельзя установить (например, при совмещении данных об удовлетворенности условиями труда и быта, где распределение в генеральной совокупности заранее вообще неизвестно), расчет процентов допустим в обоих направлениях и по диагонали с условием, что установленные связи требуют дополнительной проверки, ориентировочны. Для такой проверки используют систему так называемых контрольных (промежуточных) переменных.
Анализ взаимосвязи двух переменных с помощью контрольного фактора — прием, используемый для того, чтобы установить прямые и опосредованные, причинные и сопутствующие связи, а также уточнить их напряженность. Рассмотрим три вымышленных примера, в которых проиллюстрируем основные логические проблемы этого метода.
Здесь действует следующее правило: если введение контрольной переменной уменьшает связь между двумя исходными переменными, но связь между контрольной переменной и каждой из исходных достаточно высока, контрольная переменная выступает либо в качестве интерпретирующей, либо в качестве объясняющей. Различие же между интерпретацией и объяснением состоит в следующем. Интерпретация — способ истолкования факторов, рассматриваемых как посредствующие переменные какого-то процесса, причины которого неясны. Объяснение суть истолкование ряда факторов, рассматриваемых в качестве причинных переменных.
Чтобы иллюстрировать метод обнаружения интерпретирующей и объясняющей связи, рассмотрим другой пример, используя ту же логику рассуждения и те же цифровые данные.
Исследование многомерных взаимосвязей и взаимозависимостей — типичная задача в социологии. Как правило, такие зависимости не удается "схватить" сразу каким-то единственным математическим методом. Прибегают к различным средствам анализа в поисках наиболее "наглядного", убедительного отображения. Один из широко используемых сегодня способов такого рода — метод отображения взаимосвязей в корреляционном графе, предложенный эстонским математиком Л. Выханду [55].
Граф — это фигура, состоящая из точек (их называют вершинами графа) и отрезков, соединяющих некоторые из этих точек (ребра графа). О графе мы уже упоминали, рассматривая социометрические процедуры. Изображение связей в группе с помощью социограммы есть граф (рис. 12, с. 178). В социограмме указываются вершины графа (члены группы) и связи между ними (ребра графа).
Если бы удалось измерить корреляции или тесноту связей между всеми членами группы (вершинами) и соответственно этому выделить наиболее близкие и наиболее отдаленные связи, такое изображение можно было бы назвать корреляционным графом.
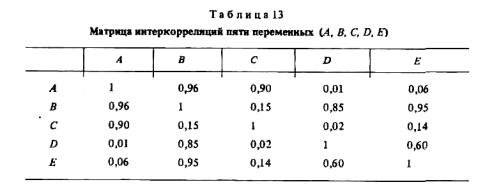
Чтобы построить корреляционный граф, измеряют парные связи между всеми переменными, обозначенными на графе как его вершины. Например, имея пять переменных А, В, С, D и Е, покажем, как связана каждая из них с каждой другой в матрице интеркорреляций (табл. 13).
Связи между выделенными переменными можно описать графом, изображенном на рис. 16.
Между вершинами А, В и С существуют взаимосвязи RBA = 0,96; RAC = 0,90; RBC = 0,15. Связь RBC можно опустить, так как она намного слабее ("длиннее"), чем связь С и В через вершину А.
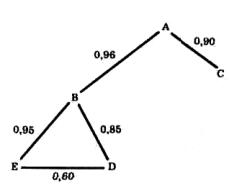
Рис.16. Корреляционный граф по методу Выханду
Иными словами, переменная А является для В и С либо объясняющей, либо интерпретирующей (В и С связаны как сопутствующие).
Иная связь между вершинами В, D и Е. Все они взаимодействуют на уровне R более 0,60. Но каждая из них связана с вершиной С очень слабо (от 0,02 до 0,14). В является промежуточной между А, с одной стороны, Е и D — с другой так как связи Е с А гораздо слабее, чем их связи с В, которая, в свою очередь, тесно связана с А.
В корреляционном графе отображаются лишь те связи между вершинами, которые соединяют их кратчайшим путем (т.е. являются наиболее тесными), и опускаются другие, менее тесные связи. На языке теории графов [36] это означает, что мы разрываем замкнутые дуги и оставляем только те ребра, которые связывают вершины наиболее тесно.
С помощью методов факторного анализа выявляют структурные взаимосвязи множества переменных [93, 136,138,140, 197].Сначала устанавливаются парные корреляции всех изучаемых переменных, а затем отыскиваются своего рода корреляционные плеяды или "узлы" связей. Иными словами, выделяют такие переменные, которые, будучи наиболее тесно взаимосвязаны в рамках своей плеяды, слабо связаны с другими корреляционными узлами. Выявленные "узлы" и есть факторы. Название фактора всегда условно и подбирается по ассоциации с теми переменными, которые наиболее сильно связаны с данным фактором — имеют наибольшие "факторные нагрузки".
Далее, на основе обнаружения этих двух структур (их может быть больше, если мы продолжим извлечение факторов, т.е. начнем разукрупнять факторную модель на более дробные составляющие) каждому обследованному могут быть приписаны "веса" по двум показателям (двум факторам): удовлетворенности условиями и содержанием труда. Теперь мы знаем, какой соотносительный "вес" имеет в этих двух факторах оценка каждого частного элемента производственной ситуации. Мы знаем также индивидуальную оценку данным рабочим каждого из элементов производственной ситуации и путем несложных арифметических действий можем приписать всем обследованным "персональные индексы" удовлетворенности условиями и содержанием труда более обоснованно, чем это было бы сделано без использования факторного анализа.
Таким образом, факторный анализ позволяет взвесить значимость каждого из элементов производственной ситуации в обшей структуре оценок удовлетворенности и соответственно учесть эти поправки при расчетах интегральных индивидуальных показателей удовлетворенности условиями труда и содержанием труда, т.е. будут получены два обобщенных показателя на каждого обследуемого вместо 14 исходных.








