 2015-05-20
2015-05-20 1304
1304Для изображения DFD-диаграмм традиционно используются две различные нотации: Йордана и Гейна-Сарсона. Алфавит, используемый для построения DFD-диаграмм, представлен в таблице 3.1.
Таблица 3.1. Нормативная система (нотация) DFD.
| Элемент алфавита | Нотация Йордана | Нотация Гейна-Сарсона |
| Поток данных Используется для моделирования передачи информации (или даже физических компонент) из одной части системы в другую. На диаграммах изображаются именованными стрелками, ориентация которых указывает направление потока. | ||
Процесс Используется для моделирования процесса преобразования входного потока в выходной. Его имя должно содержать гла   гол в неопределенной форме с последующим дополнением (например, «Вычислить высоту»). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы, который совместно с номером диаграммы уникален во всей модели. гол в неопределенной форме с последующим дополнением (например, «Вычислить высоту»). Кроме того, каждый процесс должен иметь уникальный номер для ссылок на него внутри диаграммы, который совместно с номером диаграммы уникален во всей модели. | ||
| Хранилище (накопитель) данных Используется для моделирования данных (или даже физических компонент), которые будут сохраняться между процессами. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда поток данных входит или выходит в/из хранилища, и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме. | ||
| Внешняя сущность (терминатор) Используется для моделирования сущностей вне системы (контекстных сущностей), являющихся источником или приемником системных данных. Ее имя должно содержать существительное, например, «Склад». Предполагается, что объекты, представленные такими сущностями, не должны участвовать ни в какой обработке. | ||
| Управляющий поток Используется для моделирования связи, через которую передается управляющая информация. Его имя не должно содержать глаголов, а только существительные и прилагательные. Обычно управляющий поток имеет дискретное, а не непрерывное значение. Это может быть, например, сигнал, представляющий состояние или вид операции. Имеются следующие типы управляющих потоков: а) Т-поток (trigger flow) – поток управления, который может вызывать выполнение процесса. При этом процесс как бы включается одной короткой операцией. Это аналог выключателя света, единственным нажатием которого «запускается» процесс горения лампы. б) А-поток (activator flow) – поток управления, который может изменять выполнение процесса. Используется для обеспечения непрерывности выполнения процесса до тех пор, пока поток «включен» (т.е. течет непрерывно); с «выключением» потока выполнение процесса завершается. Это – аналог переключателя лампы, которая может быть как включена, так и выключена. в) E/D-поток (enable/disable flow) – поток управления, который может переключать выполнение процесса. Течение по Е-линии вызывает выполнение процесса, которое продолжается до тех пор, пока не возбуждается течение по D-линии. Это аналог выключателя с двумя кнопками: одной для включения света, другой для его выключения. Можно использовать 3 типа таких потоков: Е-поток, D-поток, E/D-поток. | ||
| Управляющий процесс Используется для моделирования преобразователя входных управляющих потоков в выходные управляющие потоки; при этом точное описание этого преобразования должно задаваться в спецификации управления. Его имя указывает на тип управляющей деятельности, описанной в спецификации. Логически управляющий процесс есть командный пункт, реагирующий на изменения внешних условий, которые сообщаются ему с помощью управляющих потоков, и продуцирующий в соответствии со своей внутренней логикой команды для других процессов системы. | ||
| Управляющее хранилище Используется для моделирования управляющей информации, которая будут сохраняться между процессами. Содержащаяся в нем управляющая информация может использоваться в любое время после ее занесения в хранилище, при этом соответствующие данные могут быть использованы в произвольном порядке. Имя управляющего хранилища должно идентифицировать его содержимое и быть существительным. Управляющее хранилище отличается от традиционного тем, что может содержать только управляющие потоки; все другие их характеристики идентичны. | ||
| Групповой узел Используется для моделирования расщепления и объединения потоков. | ||
| Узел-предок Используется для связывания входящих и выходящих потоков между детализируемым процессом и детализирующей DFD-диаграммой. | ||
 Неиспользуемый узел Используется для моделирования ситуации, когда декомпозиция данных производится в групповом узле, при этом требуются не все элементы входящего в узел. Неиспользуемый узел Используется для моделирования ситуации, когда декомпозиция данных производится в групповом узле, при этом требуются не все элементы входящего в узел. | ||
     Узел изменения имени Используется для обеспечения возможности неоднозначного именования потоков, содержимое которых эквивалентно. Например, если при проектировании разных частей системы один и тот же фрагмент данных получил различные имена, то эквивалентность соответствующих потоков данных обеспечивается узлом изменения имени. При этом один из потоков данных является входным для данного узла а другой – выходным. Узел изменения имени Используется для обеспечения возможности неоднозначного именования потоков, содержимое которых эквивалентно. Например, если при проектировании разных частей системы один и тот же фрагмент данных получил различные имена, то эквивалентность соответствующих потоков данных обеспечивается узлом изменения имени. При этом один из потоков данных является входным для данного узла а другой – выходным. | ||
| Текст В свободном формате в любом месте диаграммы. |
Построение модели
Главная цель построения модели в виде иерархического множества DFD-диаграмм заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого рекомендуется пользоваться следующими правилами [20]:
1. Размещать на каждой диаграмме от 3 до 6-7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один или два процесса.
2. Не загромождать диаграммы несущественными на данном уровне детализации сущностями.
3. Декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов; эти две работы должны выполняться одновременно, а не одна после завершения другой.
4. Выбирать ясные, отражающие суть дела, имена процессов и потоков для улучшения восприятия диаграмм, при этом не рекомендуется использовать аббревиатуры.
5. Однократно определять функционально идентичные процессы на самом верхнем уровне иерархии, где такой процесс необходим, и ссылаться на него на нижних уровнях иерархии.
6. Пользоваться простейшими диаграммными техниками: если что-либо возможно описать с помощью DFD-диаграмм, то это и необходимо делать, а не использовать для описания более сложные объекты.
7. Отделять управляющие структуры от обрабатывающих структур (т.е. процессов), локализовать управляющие структуры.
В соответствии с этими рекомендациями процесс построения модели разбивается на следующие этапы [20]:
1. Идентификация внешних (контекстных) объектов, с которыми система должна быть связана.
2. Расчленение множества требований и организация их в основные функциональные группы.
3. Идентификация основных видов информации, циркулирующей между системой и внешними объектами.
4. Предварительная разработка контекстной диаграммы, на которой основные функциональные группы представляются процессами, внешние (контекстные) объекты – внешними сущностями, основные виды информации – потоками данных между процессами и внешними сущностями.
5. Изучение предварительной контекстной диаграммы и внесение в неё изменений по результатам ответов на возникающие при этом изучении вопросы по всем её частям.
6. Построение контекстной диаграммы путём объединения всех процессов предварительной диаграммы в один процесс, а также группирования потоков.
7. Формирование DFD-диаграммы первого уровня на базе процессов предварительной контекстной диаграммы.
8. Проверка основных требований по DFD-диаграмме первого уровня.
9. Декомпозиция каждого процесса текущей DFD-диаграммы с помощью детализирующей диаграммы или спецификации процесса.
10. Проверка основных требований по DFD-диаграмме соответствующего уровня.
11. Добавление определений новых потоков в словарь данных при каждом их появлении на диаграммах.
12. Параллельное (с процессом декомпозиции) изучение требований (в том числе и вновь поступающих), разбиение их на элементарные и идентификация процессов или спецификаций процессов, соответствующих этим требованиям.
13. После построения двух-трех уровней проведение ревизии с целью проверки корректности и улучшения понимаемости модели.
14. Построение спецификации процесса (а не простейшей диаграммы) в случае, если некоторую функцию сложно или невозможно выразить комбинацией процессов.
Важную специфическую роль в модели играет специальный вид DFD-диаграммы – контекстная диаграмма, моделирующая систему наиболее общим образом. Контекстная диаграмма отражает интерфейс системы с внешним миром, а именно, информационные потоки между системой и внешними сущностями, с которыми она должна быть связана. Она идентифицирует эти внешние сущности, а также, как правило, единственный процесс, отражающий главную цель или природу системы насколько это возможно. И хотя контекстная диаграмма выглядит тривиальной, несомненная ее полезность заключается в том, что она устанавливает границы анализируемой системы. Каждый проект должен иметь ровно одну контекстную диаграмму, при этом нет необходимости в нумерации единственного ее процесса.
Декомпозиция DFD-диаграммы осуществляется на основе процессов: каждый процесс может раскрываться с помощью DFD-диаграммы нижнего уровня. DFD-диаграмма первого уровня строится как декомпозиция процесса, который присутствует на контекстной диаграмме. Построенная диаграмма первого уровня также имеет множество процессов, которые в свою очередь могут быть декомпозированы. Таким образом строится иерархия DFD-диаграмм с контекстной диаграммой в корне дерева. Этот процесс декомпозиции продолжается до тех пор, пока процессы могут быть эффективно описаны с помощью коротких (до одной страницы) спецификаций процессов.
При таком построении иерархии DFD-диаграмм каждый процесс более низкого уровня необходимо соотнести с процессом верхнего уровня. Обычно для этой цели используются структурированные номера процессов. Так, например, если мы детализируем процесс номер 2 на диаграмме первого уровня, раскрывая его с помощью DFD-диаграммы, содержащей три процесса, то их номера будут иметь следующий вид: 2.1, 2.2 и 2.3. При необходимости можно перейти на следующий уровень, т.е. для процесса 2.2 получим 2.2.1, 2.2.2. и т.д.
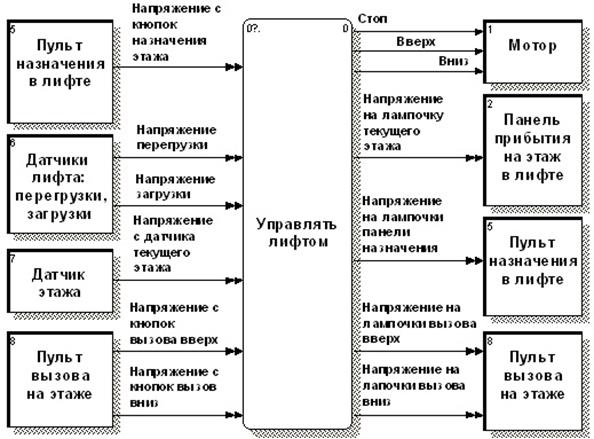
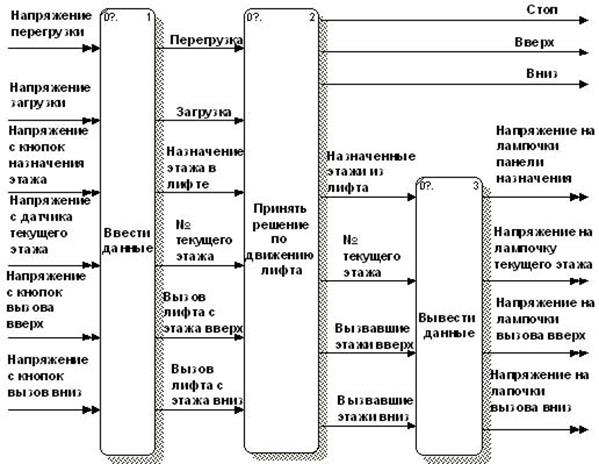
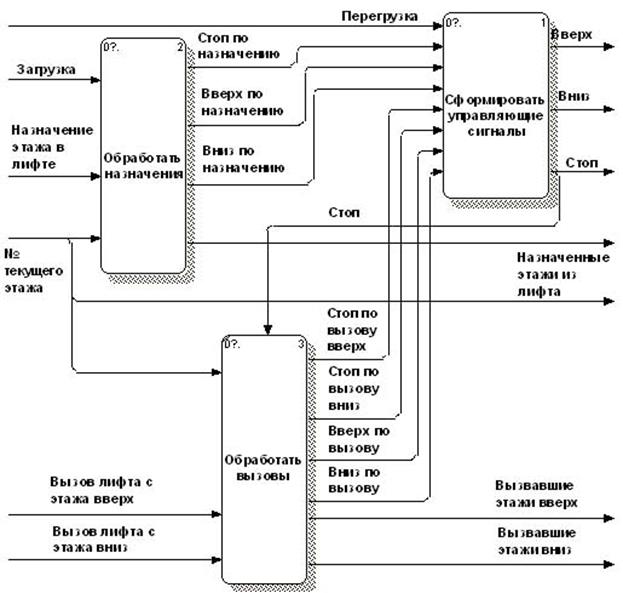
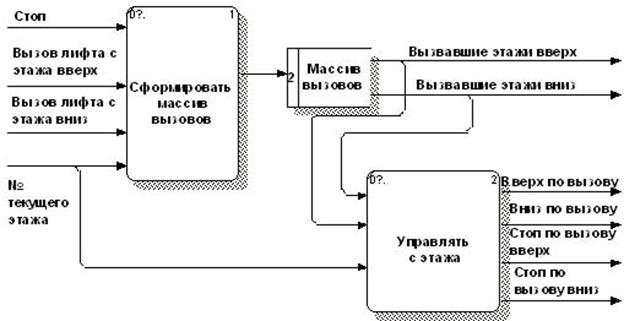
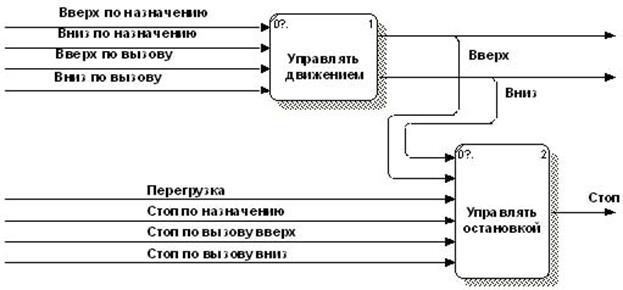
Пример иерархии DFD-диаграмм, описывающих систему управления лифтом, аналогичную представленной в работе [32] (Elevator Control System – ECS), подготовленный с применением инструментального пакета BPwin, изображен на рисунках 3.2 – 3.7. Дополнительные возможности нотации позволяют, в частности, с помощью двойных стрелок отличить материальные потоки от информационных. Данный пример используется далее для описания различных аспектов технологии моделирования 3VM.
Диаграммы (3.2 – 3.7) построены с учетом следующих требований к системе управления лифтом [32, стр. 15-17]:
- лифт используется для перевозки людей в 40-а этажном офисном здания обычным способом (при вызове лифта с этажа он должен останавливаться при попутном движении; лифт не должен менять направления, пока едущие в нем пассажиры не достигнут назначенных этажей; пустой лифт должен стоять там, где он остановился последний раз);
|
|
|
|
|
|
- ECS должна реагировать на электромагнитные сигналы от датчиков (каждого этажа и состояния лифта), а также кнопок (панелей вызова лифта с каждого этажа и панели назначения этажа в лифте);
- должна обеспечиваться индикация этажа прибытия лифта и принятия ECS вызовов и назначений;
- ECS должна обеспечивать «связанное с этажом» составление расписания движения лифта, путем выработки управляющих сигналов «стоп», «вверх» «вниз» на мотор в зависимости от текущего этажа, нажатых кнопок и состояния лифта.
Словарь данных
Диаграммы потоков данных обеспечивают описание взаимодействий функциональных компонент системы (ее структуры), но не имеют, сами по себе, средств для описания связей между компонентами и их функций, а именно, какая информация преобразуется процессами и как она преобразуется. Для решения первой из перечисленных проблем предназначено текстовое средство моделирования, служащее для описания содержания преобразуемой информации. Оно получило название «словарь данных».
Словарь данных представляет собой определенным образом организованный список всех элементов, составляющих потоки данных системы с их точными определениями. Это дает возможность различным категориям пользователей (от системного аналитика до программиста) иметь общее понимание всех входных и выходных потоков и компонент хранилищ.
Определение элементов данных в словаре осуществляется с помощью описаний следующих видов [20]:
- описанием характеристик потоков и хранилищ, изображенных на DFD-диаграммах;
- описанием композиций данных, движущихся вдоль потоков, т.е. комплексных данных, которые могут расчленяться на элементарные (например, «Адрес» содержит «Индекс», «Город», «Улица» и т.д.);
- описанием композиций данных в хранилище.
Для каждого потока данных в словаре необходимо хранить имя потока, его тип и атрибуты. Информация по каждому потоку состоит из ряда словарных статей, каждая из которых начинается с ключевого слова – заголовка соответствующей статьи, которому предшествует символ «@».
Типы потоков определяются в словаре как:
- простые (элементарные) или групповые (комплексные) потоки;
- внутренние (существующие только внутри системы) или внешние (связывающие систему с другими системами) потоки;
- потоки данных или потоки управления;
- непрерывные (принимающие любые значения в пределах диапазона) или дискретные (принимающие определенные значения) потоки.
- Атрибуты потока данных включают:
- имена-синонимы потока данных в соответствии с узлами изменения имени;
- определение с помощью БНФ-нотации (см. далее) в случае группового потока;
- единицы измерения потока;
- диапазон значений для непрерывного потока, типичное его значение и информацию по обработке экстремальных значений;
- список значений и их смысл для дискретного потока;
- список номеров диаграмм, в которых поток встречается;
- список потоков, в которые данный поток входит;
- комментарий, включающий дополнительную информацию (например о цели введения данного потока).
БНФ-нотация позволяет формально описать расщепление/объединение потоков. Поток может расщепляться на собственные отдельные ветви, на компоненты потока-предка или на то и другое одновременно.
При расщеплении/объединении потока существенно, чтобы каждый компонент потока-предка являлся именованным. При объединении подпотоков нет необходимости осуществлять исключение общих компонент, а при расщеплении подпотоки могут иметь такие общие (одинаковые) компоненты.
Точные определения потоков содержатся в словаре данных, а не на диаграммах. Например, на диаграмме может иметься групповой узел с входным потоком Х и выходными подпотоками Y и Z. Однако, это вовсе не означает, что соответствующее определение в словаре данных обязательно должно быть X=Y+Z. Это определение может быть следующим: Х=А+В+С; Y=A+B; Z=B+C. Такие определения хранятся в словаре данных в так называемой БНФ-статье.
БНФ-статья используется для описания компонент данных в потоках данных и в хранилищах. Ее синтаксис имеет следующий вид:
@БНФ = < простой оператор >! < БНФ-выражение >,
где < простой оператор > есть текстовое описание, заключенное в «/», а < БНФ-выражение > есть выражение в форме Бэкуса-Наура, заключенное в «[]» и допускающее следующие операции и отношения: = – означает «композиция из»; + – означает «И»;! – означает «ИЛИ»; () – означает, что компонент в скобках не обязателен; {} – означает итерацию компонента в скобках; «» – означает литерал.
Итерационные скобки могут иметь нижний и верхний предел, например:
3 {болт} 7 – от 3 до 7 итераций
1 {болт} – 1 и более итераций
{шайба} 3 – не более 3 итераций
БНФ-выражение может содержать произвольные комбинации операций:
@БНФ = [ винт! болт + 2 {гайка} 2 + (прокладка)! клей ]
Ниже приведен пример описания потока данных подсистемы принятия решений ECS «№ текущего этажа» (рис. 3.3 – 3.6) с помощью БНФ-статьи:
@ИМЯ = № текущего этажа
@ТИП = Простой, внутренний, дискретный поток данных
@БНФ = [«1»! «2»! …! «39»! «40»]
Далее приведен пример описания входных потоков данных блока формирования управляющих сигналов на примере потока «Перегрузка», а также выходных потоков этого блока на примере потока «Стоп» (рис. 3.7):
@ИМЯ = перегрузка
@ТИП = Простой, внутренний, дискретный поток данных
@БНФ = [«0»! «1»]
@ИМЯ = стоп
@ТИП = Простой, внешний, дискретный поток управления
@БНФ = [«0»! «1»]
Спецификация процесса
Спецификация процесса (СП) используется для описания процесса, когда нет необходимости детализировать его с помощью DFD-диаграммы (т.е. если он невелик и его описание может занимать не более одной страницы текста). СП представляет собой описание алгоритма, соответствующего данному процессу и трансформирующего входные потоки данных в выходные. Множество всех СП является полной спецификацией системы. СП содержит номер и/или имя процесса, списки входных и выходных данных и тело (описание) процесса.
Известно большое число разнообразных методов, позволяющих задать тело процесса: от структурированного естественного языка или псевдокода до визуальных языков проектирования (типа FLOW-форм), а также формальных языков программирования.
Независимо от используемого метода СП должна начинаться со следующих ключевых слов:
@ВХОД = <имя символа данных >
@ВЫХОД = <имя символа данных>
@СПЕЦПРОЦ
где <имя символа данных> – соответствующее имя из словаря данных.
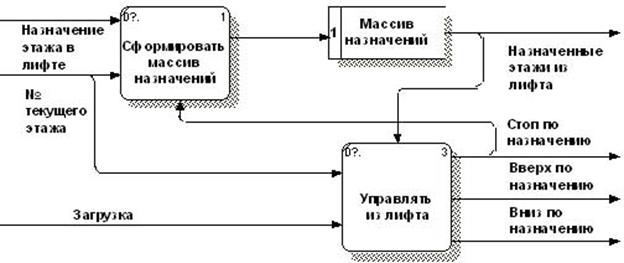
Например, для процессов формирования массивов (рис. 3.5 и 3.6),
@ВХОД = Назначение этажа в лифте; № текущего этажа; Стоп по назначению
@ВЫХОД = Массив назначений
@СПЕЦПРОЦ

