2015-05-10
2015-05-10 570
570Типы парных операций:
- MPI point-to-point operations typically involve message passing between two, and only two, different MPI tasks. One task is performing a send operation and the other task is performing a matching receive operation.
- There are different types of send and receive routines used for different purposes. For example:
- Synchronous send
- Blocking send / blocking receive
- Non-blocking send / non-blocking receive
- Buffered send
- Combined send/receive
- "Ready" send
- Any type of send routine can be paired with any type of receive routine.
- MPI also provides several routines associated with send - receive operations, such as those used to wait for a message's arrival or probe to find out if a message has arrived.
Буферизация (Buffering):
- In a perfect world, every send operation would be perfectly synchronized with its matching receive. This is rarely the case. Somehow or other, the MPI implementation must be able to deal with storing data when the two tasks are out of sync.
- Consider the following two cases:
- A send operation occurs 5 seconds before the receive is ready - where is the message while the receive is pending?
- Multiple sends arrive at the same receiving task which can only accept one send at a time - what happens to the messages that are "backing up"?
- The MPI implementation (not the MPI standard) decides what happens to data in these types of cases. Typically, a system buffer area is reserved to hold data in transit.
For example:
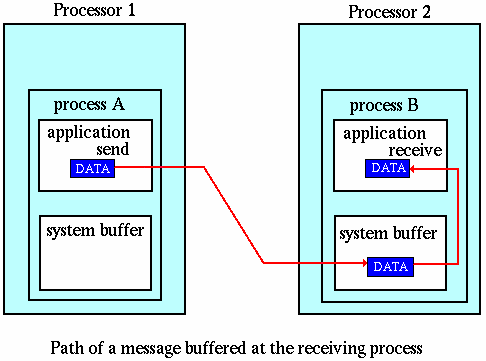
Рис. 3.4.4.1.1.
- System buffer space is:
- Opaque to the programmer and managed entirely by the MPI library
- A finite resource that can be easy to exhaust
- Often mysterious and not well documented
- Able to exist on the sending side, the receiving side, or both
- Something that may improve program performance because it allows send - receive operations to be asynchronous.
- User managed address space (i.e. your program variables) is called the application buffer. MPI also provides for a user managed send buffer.
Blocking vs. Non-blocking
Блокирующий обмен предполагает:
- Для отсылающего процесса – асинхронна, то есть управление будет возвращено в программу сразу же после передачи параметров, но при доступе к отсылаемому массиву данных доступ будет заблокирован до тех пор, пока пересылаемые данные не будут сохранены в промежуточном системном буфере. Цель - модификации массива после отсылки не должны нарушить процедуру приема. При этом поведение принимающей функции не учитывается.
- Для получающего процесса – выполнение следующей за блоком приема программы осуществляется только в случае полного приема данных.
При неблокирующем способе часть сообщений может быть отправлена и принята заранее до момента реальной потребности в пересылаемых данных, обеспечивая обмен данными без блокировки процессов для совмещения процессов передачи сообщений и вычислений (Non-blocking communications are primarily used to overlap computation with communication and exploit possible performance gains).
- Получающий процесс ведет себя подобно посылающему – не ждет завершения операций соединения, а передает управление следующему за ним блоку.
- Пользователь не может предположить когда именно они будут иметь место - они просто запрашивают обеспечение таких операций у библиотеки MPI. Для определения завершения операций – возможности редактирования буфера с пересылаемыми данными - используются функции MPI_Test и MPI_Wait.