 2015-05-13
2015-05-13 1351
1351cost = test(t,'test',X,y)
использует тестовую выборку X и y, применяет дерево решений t к этому набору примеров, и возвращает вектор cost количества или стоимости ошибок, вычисленных для тестового примера.
cost = test(t,'crossvalidate',X,y)
использует 10-шаговую кросс-валидацию для вычисления вектора cost. X и y должны быть обучающей выборкой, то есть примером, который использовался для построения дерева t. Функция делит пример на 10 подмножеств, выбранных случайным образом, ноприблизительно равного размера с сохранением пропорций классов обучающей выборки. Для каждого подмножества test создает дерево для оставшихся данных и использует его для предсказания классов подмножества. Затем объединяет информацию по всем подмножествам, чтобы оценить ошибку cost для всей выборки.
Пример 2.3. Выполним классификацию ирисов Фишера по двум параметрам с помощью построения дерева решений. Создадим дерево решений и посмотрим насколько хорошо работает этот метод.
t = classregtree(meas(:,1:2), species,'names',… {'SL' 'SW' });Посмотрим как дерево решений разделяет плоскость.
[grpname,node] = t.eval([x y]);gscatter(x,y,grpname,'grb','sod')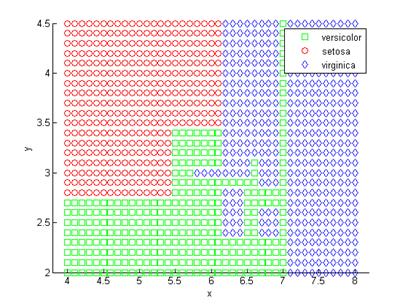
Рисунок 2.6 – Разделение плоскости значений параметров классификации деревом решений
Другой путь увидеть дерево решений – нарисовать диаграмму правил принятия решений и определения классов.
view(t);Это громоздко смотрящееся дерево (рис. 2.7) использует серию правил в форме "SL < 5.45" чтобы классифицировать каждую запись по одному из 19 узлов. Чтобы определить класс для какого-либо наблюдения, начните с верхнего узла и применяйте правила. Если значение удовлетворяет правилу, вы выбираете левый путь, если нет, то правый. В конечном итоге вы попадете в лист, который определяет для данного наблюдения один из трех классов.
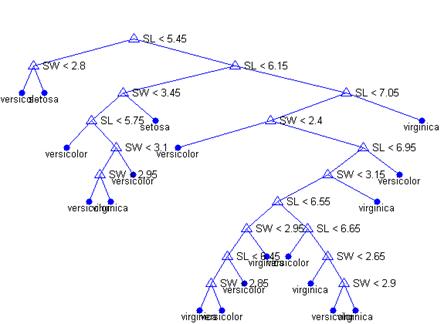
Рисунок 2.7 – Дерево решений для задачи классификации ирисов Фишера по двум параметрам
Вычислим ошибку на обучающем множестве и ошибку кросс-валидации для дерева решений.
dtclass = t.eval(meas(:,1:2));bad = ~strcmp(dtclass,species);dtResubErr = sum(bad) / N dtClassFun = @(xtrain,ytrain,xtest) (eval(classregtree(xtrain,ytrain),xtest));dtCVErr = crossval('mcr',meas(:,1:2),species,... 'predfun', dtClassFun,'partition',cp)dtResubErr = 0.1333dtCVErr = 0.3200Для построенного дерева решений ошибка кросс валидации оказалась значительно больше, чем ошибка на обучающем множестве. Это свидетельствует о переобучении. Другими словами, это дерево, которое классифицирует обучающее множество хорошо, но структура дерева чувствительна к обучающей выборке так что классификация на новых данных работает заметно хуже. Часто возможно построить более простое дерево, которое будет работать лучше.
Попробуем сократить дерево. Прежде всего вычислим ошибку классификации на обучающем (resubstitution) множестве для различных подмножеств исходного дерева. Затем вычислим ошибку кросс-валидации на поддеревьях. График показывает, что ошибка на обучающем множестве достаточно оптимистическая. Она всегда уменьшается с ростом дерева, однако, начиная с некоторой точки, ошибка кросс-валидации растет с ростом узлов дерева.
resubcost = test(t,'resub');[cost,secost,ntermnodes,bestlevel] = test(t,'cross',meas(:,1:2),species);plot(ntermnodes,cost,'b-', ntermnodes,resubcost,'r--')figure(gcf);xlabel('Number of terminal nodes');ylabel('Cost (misclassification error)')legend('Cross-validation','Resubstitution')Очевидно, что следует выбрать дерево, которое дает минимальную ошибку кросс-валидации и приемлемую ошибку на обучающем множестве. Для этого примера выбираем простейшее дерево, которое дает минимальную ошибку. Это правило используется по умолчанию classregtree/test методом.Это можно показать на графике, вычисляя величину cutoff, которая равна минимальной стоимости+1 ошибки. «Лучший» уровень, вычисляемый методом classregtree/test , это минимальное дерево для заданного порога отсечения cutoff. (Заметим, что bestlevel=0 соответствует несокращенному дереву, поэтому добавляем 1, чтобы использовать значение как индекс в выходном векторе classregtree/test.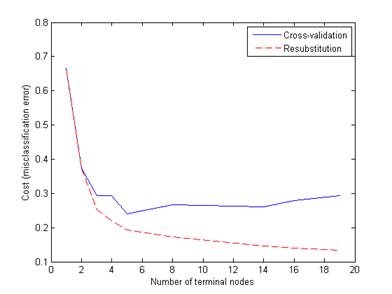
Рисунок 2.8 - Ошибки классификации в зависимости от размера дерева решений
[mincost,minloc] = min(cost);cutoff = mincost + secost(minloc);hold onplot([0 20], [cutoff cutoff], 'k:')plot(ntermnodes(bestlevel+1), cost(bestlevel+1), 'mo')legend('Cross-validation','Resubstitution','Min + 1 std. err.','Best choice')hold off Наконец, посмотрим на сокращенное дерево и вычислим ошибку классификации.pt = prune(t,bestlevel);view(pt) cost(bestlevel+1)ans = 0.2400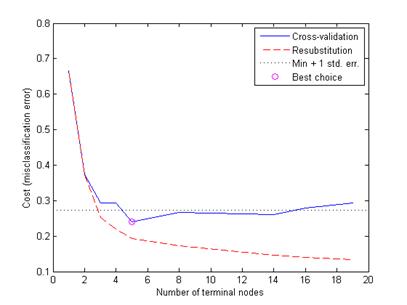
Рисунок 2.9 – Выбор оптимального количества узлов
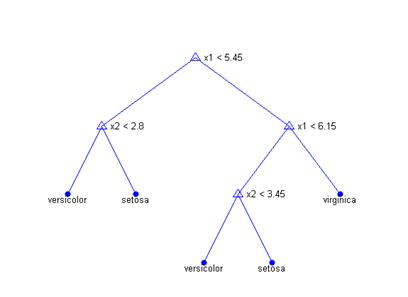
Рисунок 2.10 – Сокращенное дерево решений

