 2015-05-13
2015-05-13 25134
25134Сортировка вставками (Insertion sort) – простой алгоритм сортировки, при которой очередной элемент добавляется всегда в конец списка, а затем перемещается в начало списка до тех пор, пока он меньше предыдущего элемента.
Таким образом, формально, находится правильное место для вставки (например, сортировка карточек в библиотеке). Этот алгоритм будет иметь следующую последовательность шагов.
1. Шаг инициализации. Массив из одного элемента является уже отсортированным по возрастанию и выступает в виде начального списка.
2. Шаг итерации. Для всех последующих элементов со второго по n -1, очередной элемент i сравнивается со всеми предыдущими элементами от 0 до (i -1), пока текущий элемент i меньше или равен предыдущему. После этого будет найдена позиция для вставки или будет достигнуто начало списка. После этого элемент вставляется в найденную позицию.
3. Шаг выхода. Шаг итерации продолжается до тез пор, пока не будут просмотрены все элементы массива.
Пример
Пусть дан следующий массив:
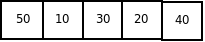
Шаг инициализации
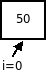
Проход 1
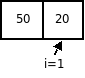

Проход 2
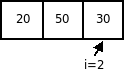
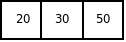
Проход 3
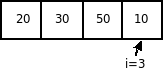

Проход 4
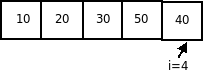
Анализ вычислительной сложности показывает, что в любом случае необходимо произвести (n-1) проход. В каждом из этих проходов в наилучшем случае, когда массив отсортирован по возрастанию, потребуется одно сравнение. В этом случае перестановок не будет, а вычислительные затраты будут
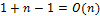 .
.
В наихудшем случае, когда массив отсортирован по убыванию, на каждый из (n -1) проходов потребуется i сравнений с предыдущими элементами 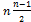 . Вычислительная сложность пропорциональна
. Вычислительная сложность пропорциональна  . В среднем, на каждом проходе потребуется на половину меньше. Следовательно, в среднем
. В среднем, на каждом проходе потребуется на половину меньше. Следовательно, в среднем 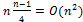 . Вычислительная сложность все равно пропорциональна
. Вычислительная сложность все равно пропорциональна 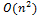 .
.
Блок-схема алгоритма сортировки вставками имеет вид:
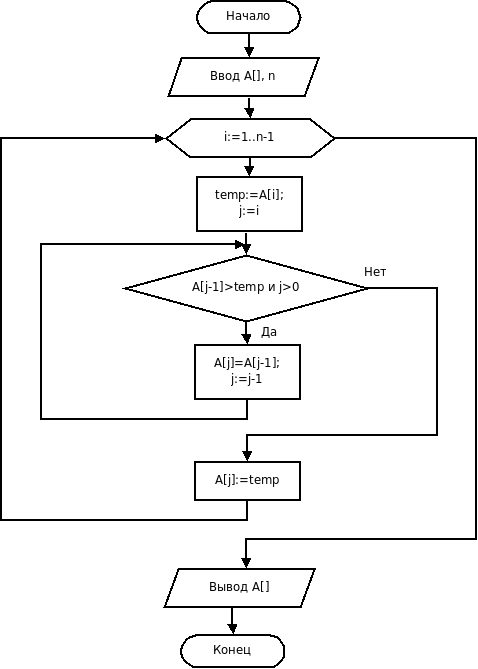
Реализовать данный алгоритм на языке С++ можно следующим образом:
template < class T>
void InsertSort(T *A, const int n)
{
T Temp;
int j;
for (int i = 1; i < n; i++)
{
Temp = A[i];
j=i;
while (j > 0 && Temp < A[j-1])
{
A[j] = A[j-1];
j--;
};
A[j] = Temp;
}
}
«Быстрая сортировка»
Алгоритм быстрой сортировки (Quick Sort), разработан английским информатиком Чарльзом Хоаром, и является самым быстрым в настоящее время среди всех остальных видов сортировок. Он основан на уникальном взаимодействии двух индексов ScanUp и ScanDown, и его можно описать следующим образом:
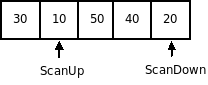
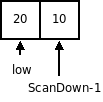
1. Шаг инициализации. На вход алгоритма передается массив и индексы начального элемента (low) и конечного (high). После этого находится индекс элемента, который находится посередине списка 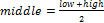 . Затем первый и серединный элемент меняются местами
. Затем первый и серединный элемент меняются местами 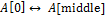 , таким образом серединный элемент будет располагаться в нулевой позиции и будет сравниваться со всеми остальными элементами с индексами от (low +1) до high. Индекс ScanUp пробегает весь список и останавливается, если будет найден элемент больший, чем серединный (вначале ScanUp = low +1). Индекс ScanDown будет пробегать список от конца до начала, пока не встретит элемент меньший или равный серединному элементу. Первоначально он устанавливается на конец списка.
, таким образом серединный элемент будет располагаться в нулевой позиции и будет сравниваться со всеми остальными элементами с индексами от (low +1) до high. Индекс ScanUp пробегает весь список и останавливается, если будет найден элемент больший, чем серединный (вначале ScanUp = low +1). Индекс ScanDown будет пробегать список от конца до начала, пока не встретит элемент меньший или равный серединному элементу. Первоначально он устанавливается на конец списка.
2. Шаг итерации. Для всех элементов начиная с позиции ScanUp до конца, ScanUp увеличивается на 1, пока не будет найден элемент, который больше серединного элемента или, пока не будет достигнут конец списка. Таким образом, ScanUp будет указывать на элемент, который находится не в своем подсписке, т.е. все элементы до ScanUp будут меньше или равны серединному. После этого индекс ScanDown уменьшается на 1, пока не будет найден элемент меньший или равный серединному, либо пока не будет достигнуто начало списка (ScanDown < ScanUp). Данный индекс указывает на элемент, который так же не находится в своем списке, т.е. все элементы после ScanDown будут больше или равны серединному элементу. Если ScanUp > ScanDown, то это означает, что каждый элемент находится в своем подсписке и их переставлять друг с другом нет необходимости. В противном случае элементы переставляются местами.
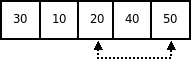
3. Шаг выхода. Шаг итерации выполняется до тех пор, пока ScanDown не станет меньше ScanUp. Это означает, что весь список разделен на две части: со значениями меньшими или равными серединному элементу и со значениями большими серединного элемента. Их разделяет позиция индекса ScanDown. После этого серединный элемент в нулевой позиции и элемент с индексом ScanDown переставляются местами.
4. Шаг рекурсии. Шаги 1-3 повторяются для левого подсписка с элементами от low до ScanDown -1 и правого – от ScanDown +1 до high до тех пор, пока список не останется пустым или одноэлементным.
Пример
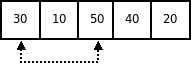
Пусть исходный массив имеет вид:
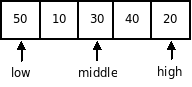
Шаг инициализации
Проход 1
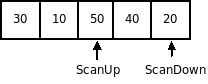
Проход 2
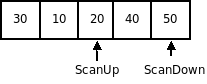
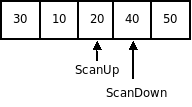
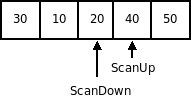
Шаг выхода
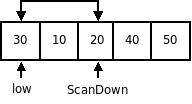
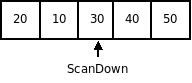
Шаг рекурсии
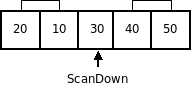
  | 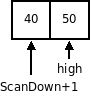 |
Рекурсия продолжается пока не будет одноэлементный список или пустой.
Анализ вычислительной сложности в общем случае затруднен. Если исходный массив можно представить в виде бинарного дерева, то в общем случае необходимо будет осуществить 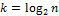 рекурсивных вызовов. Для каждого из этих вызовов, на первом необходимо просмотреть n элементов находящихся в двух подсписках. Среднее число сравнений будет
рекурсивных вызовов. Для каждого из этих вызовов, на первом необходимо просмотреть n элементов находящихся в двух подсписках. Среднее число сравнений будет 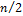 . На второй итерации надо будет просмотреть 4 подсписка. В каждом из которых нужно сделать
. На второй итерации надо будет просмотреть 4 подсписка. В каждом из которых нужно сделать 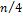 сравнений. Общее число будет
сравнений. Общее число будет 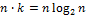 . Таким образом, затраты будут пропорциональны
. Таким образом, затраты будут пропорциональны 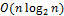 . Если массив отсортирован по возрастанию или убыванию, вычислительные затраты не изменяются. Наихудший случай появляется, когда в каждом подсписке серединный элемент оказывается максимальным или минимальным. Тогда один из подсписков будет оставаться пустым, а во втором подсписке будут находиться всегда n элементов. В этом случае преимущество «быстрой сортировки» исчезает и появляется обычная сортировка выборкой, затраты которой
. Если массив отсортирован по возрастанию или убыванию, вычислительные затраты не изменяются. Наихудший случай появляется, когда в каждом подсписке серединный элемент оказывается максимальным или минимальным. Тогда один из подсписков будет оставаться пустым, а во втором подсписке будут находиться всегда n элементов. В этом случае преимущество «быстрой сортировки» исчезает и появляется обычная сортировка выборкой, затраты которой 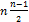 . Таким образом, в патологическом случае затраты станут пропорциональны .
. Таким образом, в патологическом случае затраты станут пропорциональны .
В отличие от других видов сортировки данный метод является самым быстрым, однако, если не устраивает патологический случай, то можно воспользоваться пирамидальной сортировкой. Она имеет туже вычислительную сложность, и у нее нет никаких ограничений. Затраты всегда остаются , в независимости от исходных данных.
Блок-схема алгоритма быстрой сортировки имеет следующий вид:
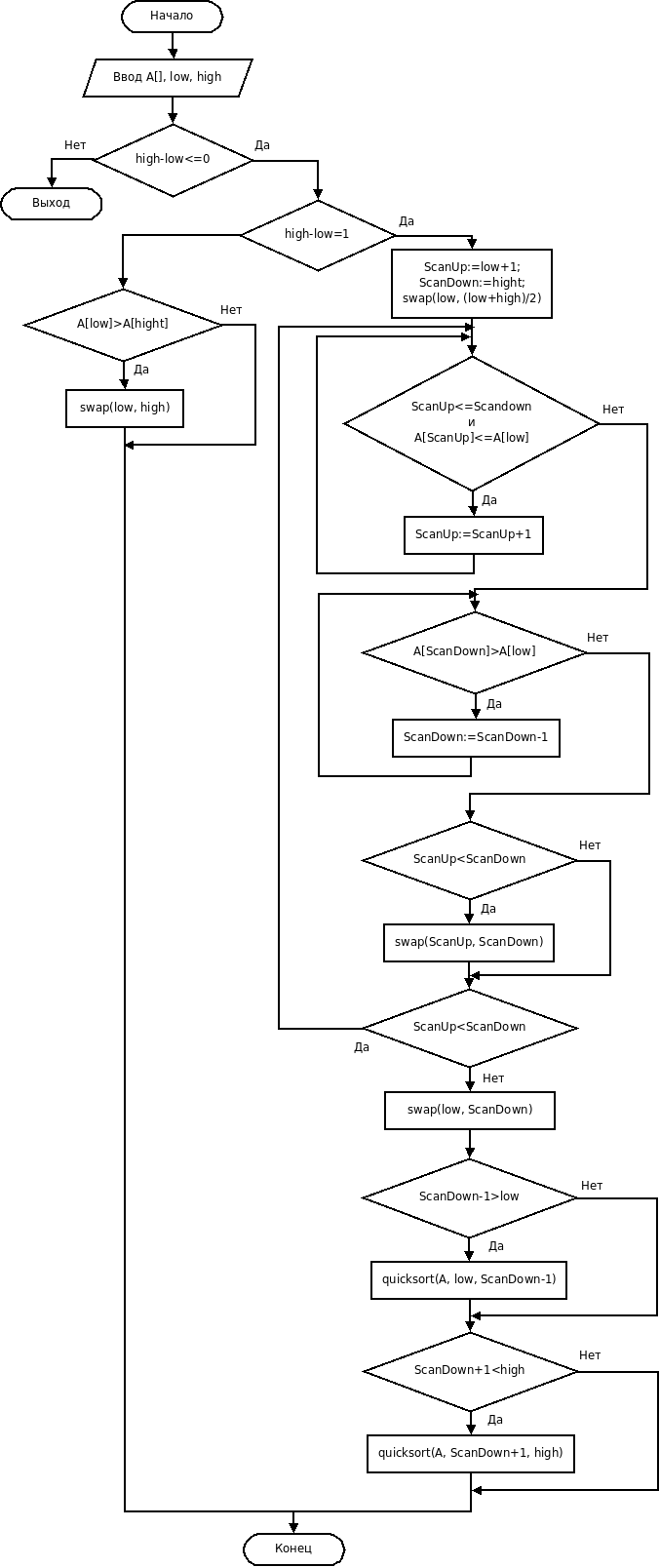
Реализовать данный алгоритм на языке С++ можно следующим образом:
template < class T>
void QuickSort(T *A, const int low, const int high)
{
T temp;
int ScanUp, ScanDown;
int res=0;
if (high-low>0)
{
if (high-low==1)
{
if (A[low]>A[high])
{
temp=A[low];
A[low]=A[high];
A[high]=temp;
}
}
Else
{
ScanUp=low+1;
ScanDown=high;
temp=A[low];
A[low]=A[(low+high)/2];
A[(low+high)/2]=temp;
do
{
while (ScanUp<=ScanDown && A[ScanUp]<=A[low])
ScanUp++;
while (A[ScanDown]>A[low])
ScanDown--;
if (ScanUp < ScanDown)
{
temp = A[ScanUp];
A[ScanUp]=A[ScanDown];
A[ScanDown]=temp;
}
}
while (ScanUp < ScanDown)
temp = A[low];
A[low] = A[ScanDown];
A[ScanDown] = temp;
if (ScanDown-1 > low)
QuickSort(A, low, ScanDown-1);
if (ScanDown+1 < high)
QuickSort(A, ScanDown+1, high);
}
}
}

