 2015-06-10
2015-06-10 2007
20071. Скопировать в новый документ MS Word текст криптограммы (без знака конца абзаца) из Приложения 3 в соответствии с номером варианта (выбор варианта осуществляется по порядковому номеру в официальном списке группы).
Выполнить анализ криптограммы аналогично рассмотренному далее примеру.
ПРИМЕЧАНИЕ: Для выполнения лабораторной работы следует использовать файл «Шифр Виженера.xlsm», а для анализа примера – файл «Шифр виженера пример.xlsx», содержащий загруженный шифр-текст.
Пример. Требуется расшифровать криптограмму:
влцдутжбюцхъяррмшбрхцэооэцгбрьцмйфктъъюьмшэсяцпунуящэйтаьэдкцибрьцгбрпачкъуцпъбьсэгкцъгуущарцёэвърюуоюэкааэбрняфукабъарпяъафкъиьжяффнйояфывбнэнфуюгбрьсшьжэтбэёчюъюръегофкбьчябашвёэуъъюаднчжчужцёэвлрнчулбюпцуруньъшсэюъзкцхъяррнрювяспэмасчкпэужьжыатуфуярюравртубурьпэщлафоуфбюацмнубсюкйтаьэдйюнооэгюожбгкбрънцэпотчмёодзцвбцшщвщепчдчдръюьскасэгъппэгюкдойрсрэвоопчщшоказръббнэугнялёкьсрбёуыэбдэулбюасшоуэтъшкрсдугэфлбубуъчнчтртпэгюкиугюэмэгюккъъпэгяапуфуэзьрадзьжчюрмфцхраююанчёчюъыхьъцомэфъцпоирькнщпэтэузуябащущбаыэйчдфрпэцъьрьцъцпоилуфэдцойэдятррачкубуфнйтаьэдкцкрннцюабугюуубурьпйюэъжтгюркующоъуфъэгясуоичщщчдцсфырэдщэъуяфшёчцюйрщвяхвмкршрпгюопэуцчйтаьэдкцибрьцыяжтюрбуэтэбдуящэубъибрювъежагибрбагбрымпуноцшяжцечкфодщоъчжшйуъцхчщвуэбдлдъэгясуахзцэбдэулькнъщбжяцэьрёдъьвювлрнуяфуоухфекьгцчччгэъжтанопчынажпачкъуъмэнкйрэфщэъьбудэндадъярьеюэлэтчоубъцэфэвлнёэгфдсэвэёкбсчоукгаутэыпуббцчкпэгючсаъбэнэфъркацхёваетуфяепьрювържадфёжбьфутощоявьъгупчршуитеачйчирамчюфчоуяюонкяжыкгсцбрясшчйотъъжрсщчл
На первом этапе следует определить длину ключевого слова (период гаммы).
2. Выполнить тест Казиски, заключающийся в поиске в шифр-тексте повторяющихся фрагментов длиной, не меньшей трех символов, и расстояния между такими фрагментами. Для выполнения теста Казиски рекомендуется использовать возможности текстового редактора MS Word 2010:
· Cкопировать текст криптограммы в новый документ MS Word. Установить курсор в начало текста. Выполнить команду Главная/Найти. В окне команды набрать первые три символа текста криптограммы, будет осуществлен поиск совпадений.
· В случае, если повторения не найдено, выполнить поиск повторений для 2, 3 и 4 символов криптограммы, и так далее, пока не будет найден повторяющийся фрагмент.
· В случае, если найдено повторение, следует выделить все вхождения этого сочетания букв (другим цветом или жирным шрифтом), для перехода к следующему найденному фрагменту следует воспользоваться кнопками со стрелками в окне поиска.
· После того, как все повторения фрагмента выделены, следует проанализировать следующие за повторениями символы с целью выяснить, не имеет ли повторяющийся фрагмент длину, большую трех символов. Если это так, их также следует выделить.
В примере, первый трехбуквенный фрагмент, для которого будет найдено повторение – «цхъ». Для него найдено лишь одно повторение (рис.48) в тексте криптограммы. На рис.48 желтой заливкой отмечено начало текста, которое было просмотрено до нахождения первого повторения.
Видно, что следующие за повторяющимся фрагментом буквы также повторяются, поэтому фрагмент имеет длину 6 и выглядит как «цхъярр».

Рис.48. Поиск повторений – тест Казиски
· После нахождения повторения следует определить расстояние между повторяющимися фрагментами. Для этого следует выделить текст от начала первого вхождения повторяющегося фрагмента до начала следующего вхождения (не включая само следующее повторение). Затем следует выполнить команду Рецензирование/Статистика 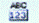 . Расстояние в знаках указано в строке Знаков (без пробелов) или Знаков (с пробелами) в окне команды.
. Расстояние в знаках указано в строке Знаков (без пробелов) или Знаков (с пробелами) в окне команды.
Так, расстояние между повторяющимися фрагментами «цхъярр» составило 210 знаков.
Если фрагмент встречается в тексте более двух раз, следует определить расстояния между каждыми двумя следующими друг за другом повторениями.
3. Открыть книгу «Шифр Виженера.xlsm», включить выполнение макросов. Занести текст повторяющихся фрагментов и значения расстояния между повторениями в форму на лист «Опред-е периода1».
Найти следующие повторяющиеся фрагменты (всего 3-4 разных фрагмента), занести данные о них на лист «Опред-е периода1».
В примере в результате анализа криптограммы будет выявлены следующие первые восемь повторений (табл.12).
Таблица 12. Определение периода гаммы – тест Казиски
| Сочетание | Расстояния | Кол-во повторений | |||
| цхъярр | |||||
| ъяр | |||||
| ооэ | |||||
| цгбр | |||||
| гбр | |||||
| брь | |||||
| брьц | |||||
| рьц |
Период гаммы M находится среди делителей НОД расстояний. Желательно, чтобы найденные в тексте повторения позволяли однозначно определить период гаммы, для этого НОД должен быть простым числом (делится нацело только на себя и на 1).
Таким образом, рекомендуется, если это возможно, производить поиск повторяющихся фрагментов в тексте до тех пор, пока значение НОД не будет простым числом.
В данном случае НОД равен 5, поэтому, скорее всего, период гаммы (длина ключевого слова) M=5.
Отметим, что для однозначного определения периода гаммы в данном примере достаточно было бы найти первые 6 повторяющихся фрагментов.
4. Определить период гаммы методом автокорреляции. Для этого следует:
· Занести текст криптограммы посимвольно в строку 2 на листе «Опред-е периода2» книги «шифр Виженера пример.xlsx». Поскольку криптограмма достаточно длинная, можно занести первые 75-100 ее символов.
ПРИМЕЧАНИЕ: Для удобства занесения символов криптограммы, можно загрузить ее в книгу «Шифр Виженера.xlsm». Для этого следует перейти на лист «Загрузить криптограмму», выделить ячейку E3 и вставить текст криптограммы в адресную строку. Затем перейти в ячейку B3, задать значение периода 7, после чего загрузить криптограмму, нажав кнопку Загрузить криптограмму.
После этого можно осуществлять копирование символов криптограммы построчно с листа «Криптограмма» (столбцы В-Н) и вставлять их в строку 2 на лист «Опред-е периода2».
Для удобства уже просмотренную часть криптограммы можно выделять цветом.
· Скопировать заполненную 2 строку (Криптограмма) листа «Опред-е периода2», начиная со второго символа, и вставить ее в 3 строку (Сдвиг = 1) командой Специальная вставка/Значения. Последний, незаполненный символ строки 3 заполнить следующим символом из текста криптограммы.
· Заполнить строки 4-12, каждый раз копируя предыдущую строку со сдвигом на 1 символ влево, использовать команду Специальная вставка/Значения. Недостающие символы в конце строк дополнить следующими символами криптограммы так, чтобы все строки были одинаковой длины.
· Цветом (инструмент Условное форматирование) будут выделены символы в строках, совпадающие с символом первой строки в том же столбце. Для каждой строки вручную подсчитать количество совпадений (число выделенных ячеек в строке) и занести эти значения в ячейки B16-B25 на листе «Опред-е периода2».
· В ячейках J16-L25 выведены значения коэффициентов автокорреляции, наибольшие из которых определяют сдвиг (сдвиги), кратные периоду гаммы (табл.13).
Полученные значения коэффициентов автокорреляции для рассматриваемого примера приведены в табл.13.
Таблица 13. Определение периода гаммы – метод автокорреляции
| Сдвиг | Число совпадений | Коэффициент автокорреляции |
| 0,040 | ||
| 0,027 | ||
| 0,013 | ||
| 0,027 | ||
| 0,093 | ||
| 0,013 | ||
| 0,027 | ||
| 0,013 | ||
| 0,027 | ||
| 0,093 |
Как видно, наибольшие значения коэффициента автокорреляции получены при величинах сдвига 5 и 10, откуда можно сделать вывод, что период гаммы (длина ключевого слова) равняется 5.
5. Проверить гипотезу о том, что период гаммы равен 5 с помощью индекса совпадения. Рассчитать индексы совпадения для групп периода:
· Очистить данные, занесенные ранее на лист «Криптограмма» (столбцы В-Н) – от этого зависит правильность подсчета индексов совпадения.
· Перейти на лист «Загрузить криптограмму», вставить шифр-текст в ячейку E3 (если это не было сделано ранее), в ячейку В3 занести значение 5, затем нажать кнопку Загрузить криптограмму. Данные будут загружены на лист «Криптограмма», каждый из полученных столбцов представляет группу периода Y↓i.
В примере на листе «Криптограмма» будут заполнены пять столбцов символов (четыре – по 198 символов и один – содержащий 197 символ).
· Перейти на лист «Статистика период». Для каждого столбца – группы периода Y↓i в строке 38 приведен расчет индекса совпадения IC(Y↓i). В случае, если период гаммы определен правильно, значения индекса должны быть не менее 0,05 и выделяются цветом.
· Если период гаммы определен неправильно, значения индексов совпадения близки к 1/33» 0,03. В этом случае следует пересмотреть гипотезу о значении периода гаммы.
В примере значения всех индексов совпадения превышают 0,05, что свидетельствует о правильности определения периода гаммы (табл.14).
Таблица 14. Значения индексов совпадения для групп периода
| Номер столбца –группы периода | |||||
| Значение индекса совпадения | 0,0571 | 0,0560 | 0,0634 | 0,0582 | 0,0723 |
На втором этапе анализа определяется само ключевое слово.
6. Определить относительные сдвиги между столбцами – группами периода:
· Перейти на лист «Статистика сдвиги» книги «шифр Виженера пример.xlsx». В диапазоне B4:AH11 приведены частоты встречаемости символов. Строка 4 содержит частоты букв в русском языке, приведенные к размеру групп периода. В строках 5-11 содержатся частоты групп периода рассматриваемой криптограммы. Распределения этих частот «сдвинуты» относительно русского языка и относительно друг друга. Для каждой группы периода цветом (инструмент Условное форматирование) выделены наибольшие значения частот.
· Определить сдвиг второй группы периода (Столбец 2) относительно первой (Столбец 1), для этого можно воспользоваться сопоставлением пиковых частот в строках 5 и 6, либо сопоставлением начала/конца фрагмента алфавита с малыми частотами (рис.49, 50). Сопоставление начала фрагмента с малыми частотами более надежно.
По сути, требуется определить направление, в котором надо сместить алфавит в строке 6, чтобы распределение частот стало сходным с распределением частот в строке 5, а также величину этого смещения в позициях.
Если строку 6 следует сдвигать вправо, то величина сдвига считается положительной (рис.49). Если строку 6 следует сдвигать влево, то величина сдвига отрицательна (рис.50), в этом случае значение следует взять по модулю L (L – число символов алфавита). В примере L =33. Для вычисления значения по модулю можно воспользоваться функцией Excel ОСТАТ().
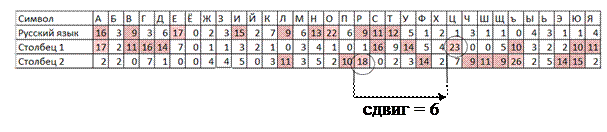
Рис.49. Пример определения сдвига сопоставлением пиковых частот
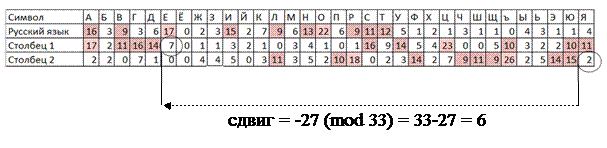
Рис.50. Пример определения сдвига по началу фрагмента
с малыми частотами
Для визуального определения величины сдвига можно использовать гистограммы частот на листе «Статистика сдвиги». Приведены гистограммы распределения частот для первой группы периода, второй группы периода и второй группы периода с учетом определенного сдвига. При визуальном анализе также следует учитывать не только пиковые (наибольшие) значения частот, но и наличие достаточно длинного промежутка низких значений частот.
· После определения сдвига, его значение заносится в столбец AI (для Столбца 2 – в ячейку AI6). Затем можно сравнить гистограммы Столбца 1 и Столбца 2 с учетом определенного сдвига. Они должны быть схожими.
В рассматриваемом примере сдвиг S Столбца 2 относительно Столбца 1, скорее всего, равен 6. Занесем это значение в ячейку AI6. Распределения частот столбца1 и столбца2 со сдвигом окажутся схожими (рис.51).
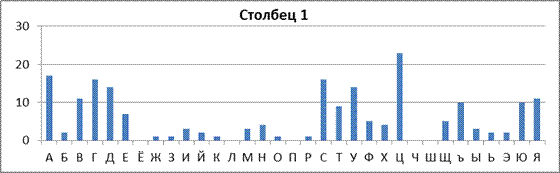
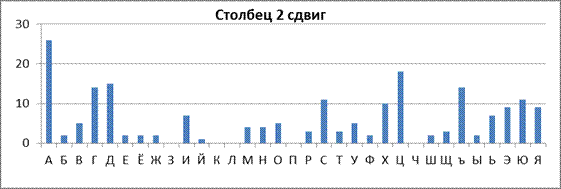
Рис.51. Пример визуальной проверки правильности определения относительного сдвига групп периода
· После определения сдвига, в диапазоне B15:AH20 отобразится «сдвинутое» распределение, в столбце AI – значение индекса взаимного совпадения (для Столбца2 – в ячейке AI15). Если сдвиг определен правильно, то значения индекса взаимного совпадения будет выше 0,05.
· В случае, если значение индекса взаимного совпадения ниже 0,05, следует рассмотреть другую гипотезу о значении относительного сдвига и изменить его значение.
В рассматриваемом примере значение индекса взаимного совпадения MIC(Y↓1, Y↓26) Столбца 1 и Столбца 2 с учетом сдвига составляет 0,0548 (ячейка AI15), что свидетельствует о правильном определении величины сдвига.
· Аналогичным образом определить относительные сдвиги остальных столбцов – групп периода относительно Столбца 1. Для визуального определения и проверки правильности определения величины сдвига Столбца 3, Столбца 4 и т.д. с помощью гистограмм, в гистограммах «Столбец 2» и «Столбец 2 сдвиг» следует изменить исходные данные (щелкнуть на гистограмме правой кнопкой мыши и выбрать команду Выбрать данные).
В рассматриваемом примере получили следующие сдвиги и индексы взаимного совпадения (табл.15):
Таблица 15. Относительные сдвиги и индексы взаимного совпадения столбцов
| Номер столбца | ||||
| Сдвиг относительно 1 столбца | ||||
| Индекс взаимного совпадения с 1 столбцом | 0,0548 | 0,0581 | 0,0547 | 0,0605 |
7. Определение относительных сдвигов S позволяет составить систему уравнений для определения сдвигов g(i) групп периода Y↓i относительно алфавита Столбца 1 (отображается в строках 25-28 на листе «Статистика сдвиги»).
g(1)-g(2)=6,откуда g(2)=g(1)-6,
g(1)-g(3)=3, g(3)=g(1)-3,
g(1)-g(4)=16, g(4)=g(1)-16,
g(1)-g(5)=3. g(5)=g(1)-3.
8. Теперь для определения ключевого слова осталось только вычислить значение g(1), то есть величину сдвига Столбца 1 относительно символов открытого текста. Поскольку возможно всего 33 варианта сдвига (от 0 до 32), сдвиг g(1) нетрудно определить перебором всех вариантов.
Подбор сдвига отображается в строках 33-66 на листе «Статистика сдвиги».
В каждой строке значение первого символа – сдвиг первого символа ключевого слова относительно буквы «А» (значение = 0) на g(1) позиций, остальные символы ключевого слова получаются сдвигами буквы «А» на g(i), i¹1, которые были определены ранее из полученных уравнений.
Получаем следующие варианты (табл.16) ключевого слова, которые отображаются в диапазоне D34:H66 листа «Статистика сдвиги».
Таблица 16. Определение ключевого слова
| Сдвиг g(1) | Ключ | Сдвиг g(1) | Ключ | Сдвиг g(1) | Ключ |
| аъэрэ | кезыз | xптёт | |||
| быюсю | лёиьи | цружу | |||
| вьятя | мжйэй | чсфзф | |||
| гэауа | нзкюк | штхих | |||
| дюбфб | оилял | щуцйц | |||
| еявхв | пймам | ъфчкч | |||
| ёагцг | pкнбн | ыхшлш | |||
| жбдчд | слово | ьцщмщ | |||
| звеше | тмпгп | эчънъ | |||
| игёщё | унрдр | юшыоы | |||
| йджъж | фосес | ящьпь |
Поскольку известно, что ключ является осмысленным словом, его можно определить.
В примере лишь один из вариантов является осмысленным: при величине сдвига g(1) = 18 – «слово» (тогда g(2) = 12, g(3) = 15, g(4) = 2, g(5) = 15).
9. Зная ключ, провести дешифровку.
Дешифровка криптограммы проводится по формуле:
aj = (ci - Si ) mod L,
где aj, cj – j -тый элемент открытого текста и криптограммы соответственно, j=1,…,N, L – число символов нормативного алфавита A, Si – сдвиг, определяемый j -тым символом гаммы. Si определяются, исходя из значений сдвигов g(i), соответствующих найденному ключевому слову.
· Для получения открытого текста на листе «Криптограмма» следует ввести найденное ключевое слово посимвольно в диапазон ячеек K1:Q1. Расшифровка текста содержится в столбцах K-Q (чтение текста осуществляется по строкам).
· Если в результате дешифровки осмысленный текст не был получен, следует опробовать другой правдоподобный вариант ключевого слова из списка полученных.
В рассматриваемом примере получен осмысленный текст:
развебытьздоровымтожесамоечтонебытьбольнымопределенноздоровьеэтонечтобольшеедлянасфизическоездоровьеэтоисостояниеиспособностьиэнергиязаниматьсятемчтонамнеобходимополучатьприэтомудовольствиеивыздоравливатьбезвсякойпомощиздоровьепарадоксальновынеможетенепосредственнозаставитьсебястатьздоровымвамостаетсятольконаблюдатьзатемкакудивительнаяспособностьвашегоорганизмаисцелятьсебяначинаетдействоватьсамасобойивашебогатствоилибедностьжестокостьилидобродетельностьнеимеютздесьповидимомуникакогозначенияздоровьеэтонечтопозитивноеононеозначаетотказотудовольствияздоровьеявляетсяестественнымследствиемнашегообразажизнивзаимоотношенийдиетыокружающейобстановкиздоровьеэтонепредметсобственностиэтопроцессэтоточтомыделаемрезультатнашихмыслейичувствэтообразсуществованияинтересночтонаправлениемедицинскихисследованийвсебольшеибольшеотклоняетсявсторонутойобластикотораядосихпорсчиталасьсферойдеятельностипсихологовисейчасужетруднопровестичеткиеразграничениямеждуфизическимииментальнымифакторамизаболеваний.
10. Показать результат выполнения лабораторной работы преподавателю
Контрольные вопросы:
1. Почему шифр Виженера нельзя вскрыть так же, как шифр простой замены, проводя сравнение частот символов шифр-текста и естественного языка и подставляя их в текст?
(Шифр Виженера является многоалфавитным, простая замена применена к каждому M-тому символу, где M – длина ключевого слова. Это значит, что сопоставление частот корректно только внутри группы из каждого M-того символа, которые идут не подряд, а значит не образуют осмысленные слова)
2. Из каких этапов состоит вскрытие шифра Виженера?
(Вскрытие шифра Виженера проводится в два этапа, сначала определяется длина ключевого слова – период гаммы, а затем можно определить и символы ключа)
3. Каковы условия успешного вскрытия шифра Виженера статистическим методом?
(Ключевое слово должно быть коротким, осмысленным, а зашифрованный текст должен быть существенно длиннее использованного ключевого слова)
Лабораторная работа №12. Изучение шифра RSA
В отличие от рассмотренных ранее шифров, шифр RSA является асимметричным (криптосистемой с открытым ключом). Это значит, что используются два ключа: открытый (public key) и личный (private key), причем, если шифрование проводилась одним ключом, расшифровка производится парным к нему ключом. В зависимости от типа решаемых задач для шифрования может использоваться либо открытый, либо личный ключ.
Для решения задачи обеспечения секретности сообщения, оно шифруется открытым ключом (ОК) получателя, тогда расшифровка может быть произведена только его личным ключом (ЛК) – рис.52.
Открытый ключ может публиковаться в справочниках, подобных справочникам телефонных абонентов, личный ключ держится в секрете.
В асимметричной схеме передачи шифрованных сообщений оба ключа являются производными от единого порождающего мастер-ключа. Когда два ключа (открытый и личный) сформированы, они зависимы в математическом смысле, однако в силу вычислительной сложности ни один из них не может быть вычислен на основании другого.
После того, как сформированы оба ключа (открытый и личный), мастер-ключ уничтожается, и таким образом пресекаются попытки восстановить в дальнейшем значения производных от него ключей.
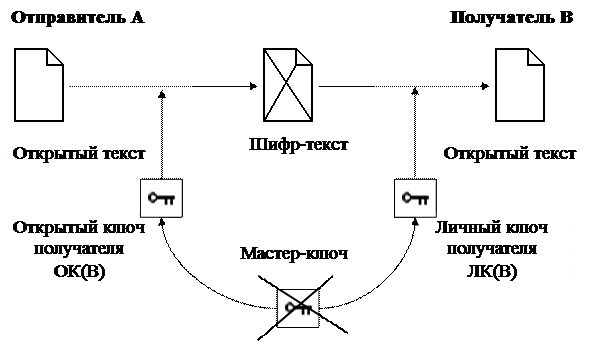
Рис.52. Криптография с открытым ключом:
Перед началом процесса шифрования исходный текст должен быть переведен в числовую форму (с помощью таблицы замен), этот метод считается известным. В результате текст представляется в виде одного большого числа. Затем полученное число разбивается на части (блоки) так, чтобы каждая из них была числом в промежутке от 0 до N -1, (о выборе числа N будет рассказано далее). Процесс шифрования одинаков для каждого блока. Поэтому можно считать, что блок исходного текста представлен числом X, 0 ≤ X ≤ N ‑1.
Конечно, выбор блоков неоднозначен, но и не совсем произволен. Например, во избежание двусмысленностей, не следует выделять блоки, начинающиеся с нуля.
Разбиение числа на блоки можно произвести различными способами. При этом промежуточные результаты зависят от способа разбиения, однако конечный результат – не зависит.
При расшифровке, наоборот, полученная последовательность блоков соединяется вместе и получается большое число. После этого числа заменяют буквами в соответствии с таблицей замен для получения исходного сообщения.
Поскольку должен существовать однозначный алгоритм вычленения кода символа из общей последовательности блоков, использование ASCII-кодировки не подходит (в ASCII на каждый символ приходится разное число десятичных разрядов от 1 до 3). Например, можно кодировать символы нормативного алфавита двузначными числами, старший разряд которых отличен от нуля.
Опишем процесс шифрования. Для каждого абонента вырабатывается своя пара ключей. Для этого генерируются два больших простых числа p и q (мастер-ключ), вычисляется произведение N = p * q. Затем вычисляется значение функции Эйлера j(N) от числа N. Поскольку p и q – простые числа, j(N) = (p -1)*(q -1).
Затем вырабатывается случайное число e, такое что: e <j(N), e – взаимно простое со значением функции j(N).
После этого ищется число d из условия e * d = 1(mod φ(N)). Так как e и j(N) – взаимно просты, НОД(e,j(N))=1, то такое число d существует и оно единственно. Число d можно найти с помощью расширенного алгоритма Евклида.
Пара (N, e) является открытым ключом абонента и помещается в открытый доступ.
Пара (N, d) является личным (секретным) ключом. Для расшифровки достаточно знать секретный ключ.
Числа p, q, j(N) в дальнейшем не нужны, поэтому они уничтожаются.
Пользователь A, отправляющий сообщение X абоненту B, выбирает из открытого каталога пару (N, e) абонента B и вычисляет шифрованное сообщение Y = Xe (mod N).
Чтобы получить исходный текст, абонент B вычисляет Yd (mod N) = X.
Пример: Пусть p = 7, q = 17. Тогда N = 7*17 = 119, φ(N) = 6*16 = 96.
Выбираем значение е: e <96, (e,96)=1. Пусть выбрано e = 5.
Находим d: e * d = 1(mod φ(N)), d = e-1 (mod φ(N)). Получаем d = 77, так как 77*5 = 4*96+1.
Открытый ключ (119,5), личный ключ (119,77). Пусть Х = 19. Для зашифрования число 19 возводим в 5-ю степень по модулю 119, тогда имеем 195 = 2 476 099 и остаток от деления 2 476 099 на 119 равен 66. Итак, Y = 195 mod 119 = 66, расшифровка: X = 6677 mod 119 = 19.
Упрощение вычислений
Как шифрование, так и расшифровка в RSA предполагают использование операции возведения целого числа в целую степень по модулю N. Если возведение в степень выполнять непосредственно с целыми числами и только потом проводить сравнение по модулю N, то промежуточные значения окажутся огромными. Здесь можно воспользоваться свойствами арифметики в классах вычетов a * b mod N = = ((a mod N)* b) mod N = ((a mod N)*(b mod N)) mod N. Таким образом, можно рассмотреть промежуточные результаты по модулю N. Это делает вычисления практически выполнимыми.
Например, для вычисления 883 mod 23, можно выполнить следующее преобразование:
883 mod 23 = ((88 mod 23)*88 mod 23)*88 mod 23 =
= ((19*88) mod 23)*88 mod 23= (1672 mod 23)*88 mod 23 = 16*88 mod 23 = 1408 mod 23 = 5.
Существует более эффективный алгоритм вычисления большой степени числа, основанный на возведении в квадрат по модулю N. Степень x при вычислении значения a x представляется в виде последовательности операций умножения на 2 и сложения с 1. Пусть, например, требуется вычислить a100 mod N. Представим степень как 100 = 2(2(1+2*2*2(1+2))). Тогда возведение в степень a100 = (((((a2*a)2)2)2*a)2)2,
a100 mod N = (((((((a2 mod N)*(a mod N))2 mod N)2 mod N)2 mod N)*(a mod N))2 mod N)2 mod N.
Вычислим 7100 mod 23, получаем 16:
| 72 mod 23 | x *7 mod 23 | x 2 mod 23 | x 2 mod 23 | x 2 mod 23 | x *7 mod 23 | x 2 mod 23 | x 2 mod 23 | |
| x |
Таким образом, возведение в степень 100 производится путем 2 умножений и 6 возведений в квадрат по модулю (8 операций умножения).
Количество операций умножения при вычислении a x методом повторного возведения в квадрат не превосходит 2log x.
Для нахождения числа d, удовлетворяющего равенству e * d = 1(mod φ(N)), то есть инверсии e по модулю φ(N): d = e‑1 (mod φ(N)), может быть использован расширенный алгоритм Евклида.
На вход алгоритма подаются числа φ(N), e, φ(N)> e.
1. Формируются строки: U={u1,u2} {φ(N), 0}; V={v1,v2} { e, 1}.
2. ПОКА v1¹0:
3. k u1 div v1
4. T={t1,t2} {u1 mod v1, u2-k*v2}
5. U V, V T
6. РЕЗУЛЬТАТ U={u1,u2}={НОД(φ(N), e), d }
Пусть, например, e = 19, φ(N) = 28, требуется найти значение d = e‑1 (mod φ(N)).
Расширенный алгоритм Евклида:
| шаг | результат | строки | k | ||||
| U | |||||||
| V | U | ||||||
| T | V | U | -1 | ||||
| T | V | U | |||||
| T | V | -28 |
В начале в строку U записываются значения {28,0}, а в строку V – {19,1} (это две первые строки в схеме). Вычисляется T (третья строка). После этого в качестве U берется вторая, а в качестве V – третья строка в схеме, и вычисляется новое значение T (четвертая строка). Этот процесс продолжается до тех пор, пока первый элемент строки V не окажется равным 0. Тогда строка U (предпоследняя в схеме) содержит ответ.
В данном примере, НОД(28,19)=1, d =3.








