 2015-07-14
2015-07-14 874
874Однако, если нулевая гипотеза определяет некоторое ненулевое значение величины а1, то необходимо использовать более общее выражение:
t = (а1 – а0) / σа1 , (3.12)
где а0 некоторое ненулевое значение величины а1, принимаемое в качестве нулевой гипотезы.
Для проверки адекватности уравнения в целом применяют F-тест, с помощью которого оценивают статистическую значимость и надежность оцениваемых характеристик уравнения регрессии. При этом рассчитывается
F факт. как отношение значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы.
(df 1 = m = p - 1 и df 2 = n – m - 1 = n – p):
 | |||
 | |||

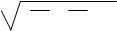
 F факт. = r2xy * (n-2); F факт = n - p * S 2факт.
F факт. = r2xy * (n-2); F факт = n - p * S 2факт.
1 - r2xy p - 1 S2ост.
, (3. 13)
где p -число параметров модели.
Так как 1 ≤ F ≤ ∞, то при F факт < 1, следует рассматриватьвеличину 1/ F факт .
Примечание:Если использовать m -число факторов модели, то p = m + 1 и, тогда, необходимо умножить на * (n – m - 1)/ m).
F факт. можно также найти с помощью статистической функции ЛИНЕЙН - элемент (4, 1) в матрице результатов. F факт. сравнивается с
F табл. -табличное значение F - критерия Фишера при выбранном уров-

 не значимости α и df1 = p – 1,() df2 = n – p () - степенях свободы.
не значимости α и df1 = p – 1,() df2 = n – p () - степенях свободы.
Если F факт. < F табл. ,то гипотеза H0 принимается и признается статистическая незначимость, ненадежность уравнения регрессии.
Если F факт. > F табл,то оцениваемые характеристики уравнения регрессии статистически значимы и надежны.
Для расчета доверительного интервала определяем предельную ошибку ∆ для каждого показателя:
∆ а0 = tтабл.· Sа0; ∆ а1 = tтабл. · Sа1, (3. 14)
Где

 S а1=S ост. / σx√n - 2, Sa0=S ост/√п - 2, Sr =√ (1-r2 )/(n-2)
S а1=S ост. / σx√n - 2, Sa0=S ост/√п - 2, Sr =√ (1-r2 )/(n-2)
S2ост. = Σ(Y – Ŷ)2/ n
Формулы для расчета доверительных интервалов имеют следующий вид:
а0 ± ∆ а0; а1 ± ∆ а1 (3. 15)
Если в границы доверительного интервала попадает 0,т.е. нижняя граница отрицательная, а верхняя положительная, то оцениваемый параметр прини -
мается нулевым, так как он не может одновременно принимать и положительные и отрицательные значения.
Прогнозное значение ypнайдем, подставив в уравнение регрессии
ух = а 0+а1 ·х
соответствующее (прогнозное) значениехр.
Вычислим среднюю ошибку прогноза myp:
 |
 myp = σост. . √1 + 1/ n +((xp – x)2 / Σ(xi – x)2) (3. 16)
myp = σост. . √1 + 1/ n +((xp – x)2 / Σ(xi – x)2) (3. 16)
Где
 σост. = √Σ(y – y x)2/(n – (m – 1)); (3. 17)
σост. = √Σ(y – y x)2/(n – (m – 1)); (3. 17)
тогдадоверительный интервал прогноза:
ур ± ∆ ур; где ∆ ур = tтабл. mур. (3. 18)
Пример2. Вернемся к предыдущему примеру1 и проверим адекватность пос-
троенной модели.Для этого найдем, используя вспомогательную таблицу 2:
Таблица 2.
    у-у у-у | (у- у)2 | Ŷ- у | (Ŷ- у)2 | у - ŷ | (у-Ŷ)2 |
| -3.3 | 10.89 | -2.7 | 7.29 | -0.6 | 0.36 |
| -2.3 | 5.29 | -2.1 | 4.41 | -0.2 | 0.04 |
| -1.3 | 1.69 | -1.5 | 2.25 | 0.2 | 0.04 |
| -0.3 | 0.09 | -0.9 | 0.81 | 0.6 | 0.36 |
| -0.3 | 0.09 | -0.3 | 0.09 | ||
| 0.7 | 0.49 | 0.3 | 0.09 | 0.4 | 0.16 |
| 0.7 | 0.49 | 0.9 | 0.81 | -0.2 | 0.04 |
| 1.7 | 2.89 | 1.5 | 2.25 | 0.2 | 0.04 |
| 2.7 | 7.29 | 2.1 | 4.41 | 0.6 | 0.36 |
| 1.7 | 2.89 | 2.7 | 7.29 | -1 | |
| Σ | 32.1 | - | 29.7 | - | 2.4 |

 Sост. =√Σ(у – ŷ)²/ n = √ 2.4/10 =0.49
Sост. =√Σ(у – ŷ)²/ n = √ 2.4/10 =0.49
 |
σx = √ 38.5 – (5.5)2 = 2.87
 Тогда расчетные значения t - критерия равны:
Тогда расчетные значения t - критерия равны:
 t β 0 = 4* √(10 – 2) / 0.49 = 23.1; t β 1 = 0.6* (√(10 – 2) /0.49)* 2.87= 9.94
t β 0 = 4* √(10 – 2) / 0.49 = 23.1; t β 1 = 0.6* (√(10 – 2) /0.49)* 2.87= 9.94
По таблице распределения Стьюдента для 10 – 2 = 8 степеней свободы и уровне значимости α = 0.05, найдем критическое значение t– критерия: t табличное равно 2.31.
Так как t расчетное больше t табличного, для каждого параметра, то оба параметра β0 и β1 значимы.
Вычислим коэффициент корреляции:
 r xy =(yx – y. x)/σxσy = ( 45.1 – 5.5*7.3)/2.87*1.792 = = 0.962.
r xy =(yx – y. x)/σxσy = ( 45.1 – 5.5*7.3)/2.87*1.792 = = 0.962.
 |  | ||
так как σy = у2 – (у)2 = 56.5 – 7.32 =1.7917
Вывод: существует достаточно тесная связь между производительностью труда и стажем работы.
R2 = 0,962*0,962 = 0,925
Вывод: 92,5% вариации у объясняется вариацией х.
Проверим значимость коэффициента корреляции используя критерий Стьюдента:
 |  |
 t = r * (n-2)/(1-r2) = 0,962 * (10 – 2)/ (1 – 0,925) = 9,93.
t = r * (n-2)/(1-r2) = 0,962 * (10 – 2)/ (1 – 0,925) = 9,93.
Вывод: Так как расчетное значение больше критического значения, то коэффициент корреляции значим.
Таким образом, построенная модель в целом адекватна, и выводы, полученные по результатам малой выборки, можно с достаточной вероятностью распространить на всю гипотетическую генеральную совокупность.
Из модели, следует, что возрастание на 1 год стажа рабочего приводит к увеличению им дневной выработкм в среднем на 0.6 изделия.
Вычислив коэффициент эластичности
 Э = β1 х / у = 0,6*5,5/ 7.3 = 0,45 сделаем вывод: с возрастанием стажа работы на 1% следует ожидать повышение производительности труда в среднем на 0,45%.
Э = β1 х / у = 0,6*5,5/ 7.3 = 0,45 сделаем вывод: с возрастанием стажа работы на 1% следует ожидать повышение производительности труда в среднем на 0,45%.
Анализируя остатки модели можно сделать ряд практических выводов, в частности определить наиболее передовых (наибольшие положительные остатки) и отстающих (наибольшие отрицательные остатки) рабочих.








