2015-10-22
2015-10-22 1391
1391В экономике, банковских операциях, предпринимательстве и др. часто приходится принимать очень важные решения в ситуациях с неопределенным исходом, при этом необходим тщательный расчет, связанный с прогнозом состояния рынка, рентабельности предприятий и банков, базирующийся на методах анализа данных и прикладной статистики, позволяющих выявлять закономерности на фоне случайностей, формулировать обоснованные выводы и прогнозы, оценивать вероятности их выполнения и т.п. /242-269/.
Широкому внедрению методов анализа данных в практику интеллектуальной деятельности и деловых расчетов способствовало появление ЭВМ и ПЭВМ. Эксплуатируемые сегодня универсальные и специализированные статистические программные пакеты типа STADIA, ЭВРИСТА, SPSS, STANGRAPHICS, SYSTAT, STATISTICA, СТАТИСТИК-КОНСУЛЬТАНТ для среды WINDOWS и др. обеспечили доступность методов анализа, их наглядность, автоматическое выполнение трудоемких расчетов с построением таблиц и графиков. Все эти операции выполняет ПЭВМ, за ЛПР остались творческие функции: постановка задач, выбор методов их решения и интерпретация результатов.
|
|
|
Практически все пакеты обеспечивают широкий набор средств визуализации данных: построение графиков, двух- и трехмерных диаграмм, различные средства деловой графики, помогающие лучше представить обрабатываемые данные, получить общее представление об их особенностях и закономерностях.
Однако для осмысленного их употребления пользователь должен обладать определенной подготовкой: понимать, в каких ситуациях применимы различные статистические методы, знать, каковы их свойства, уметь интерпретировать результаты. И сели на Западе такая подготовка обеспечивается обучением основам анализа данных практически всех студентов и менеджеров, а также старшеклассников школ, то в нашей стране, к сожалению, ситуация несколько иная: в вузах, даже перегруженных математикой, методам анализа данных уделялось очень небольшое место, и даже здесь основное внимание уделялось не столько этим методам, сколько формальным конструкциям теории множеств, теории меры, функционального анализа и теории вероятностей, которые не способствовали практическому освоению этих методов. В средней школе и массе вузов, включая педагогические, методы статистического анализа данных не упоминаются вовсе. В результате для большинства российских руководителей и менеджеров самые простейшие методы статистического анализа данных не известны.
Сегодня с широким распространением ПЭВМ появилась возможность использовать в практической деятельности универсальные и специализированные статистические пакеты типа STADIA, ЭВРИСТА, SPSS, SYANGRAPHICS, SYSTAT. Множество новых пакетов разработано для среды WINDOWS-STATISTICA, СТАТИСТИК-КОНСУЛЬТАНТ.
|
|
|
Из перспективных отечественных разработок можно назвать программные системы типа Олимп:ФинЭксперт, Олимп:СтатЭксперт, Олимп:ТриКита, работающие в среде Windows 3.11 и Windows 95 /242,243/ и использующие интерфейс Microsoft Excel.
Программная система ФинЭксперт позволяет исследовать: структуры баланса, платежеспособности и ликвидности, финансовой устойчивости фирм: оборачиваемости активов; эффективности использования капитала и рентабельности продаж. Программой используются методы финансового менеджмента, расчета и использования эффектов финансового и операционного рычагов, учета инфляционных процессов и финансовой политики предприятий. Входной информацией при этом выступают данные внешней бухгалтерской отчетности (баланс предприятия, формы NN 2, 4, 5, приложения к нему).
Программная система Олимп:СтатЭксперт позволяет проводить полный цикл исследований по статистическому анализу и прогнозированию данных, начиная с их ввода, проверки визуализации и кончая проведением и анализом результатов на основе широкого набора современных методов прикладной статистики, включая в свой состав: средства описательной (дескриптивной) статистики количественных данных; методы анализа и прогнозирования одномерных временных рядов; корреляционный и регрессионный анализ; свыше 20 адаптивных моделей и методов прогнозирования; авторегрессионные модели; факторный, кластерный, частотный, гармонический и структурный (структурных сдвигов и различий) анализ; обработку нечисловой информации и принятие решений.
Программная система Олимп:ТриКита позволяет решать задачи управления предприятием, связанные с планированием, учетом и контролем, всесторонне отражая реальное положение дел в финансовой сфере и динамике развития предприятия, планировании расходов и контроле их исполнения, в учете кадров и нагрузки персонала, оценке эффективности работы сотрудников, отделов, департаментов и филиалов; в учете работ и по текущему положению дел по заключенным договорам, по задолжникам и сумме задолженности и др.
Дескриптивная статистика является простым и распространенным средством характеристики исходных данных, позволяя оценивать в аналитическом или графическом видах перспективы их использования для дальнейшего более глубокого анализа. Например, программой СтатЭксперт конструируются 7 таблиц статистических данных - базисные и цепные характеристики динамики, средние характеристики, гипотеза об отсутствии тренда, проверка однородности данных, (частная) автокорреляционная функция, интервальные ряды и формируются графики-гистограммы.
Прогнозирование временных рядов обеспечивает формирование точечного и интервального прогнозов исследуемого показателя и выдачу пользователю степени доверия к полученным результатам. В качестве классов моделей используются: кривые роста, адаптивные модели Брауна и Хольта, Бокса-Дженкинса (модели авторегрессии АР(р) порядка «р») и др. Полнота выдачи результатов вычислений определяется перечнем таблиц, заказанных пользователем в блоке "Структура отчета". Отражение результатов прогноза дается на графиках аппроксимации и ретропрогнозов с указанием верхней и нижней границ, относительной и абсолютной ошибок и др.
Корреляционный анализ обеспечивает измерение степени связи различного числа переменных, отбора факторов, наиболее влияющих на результативный признак, с обнаружением ранее неизвестных причинных связей. Результаты обработки отражаются в 5 таблицах (оптимальные лаги корреляции и парные корреляции на них, парные, частные и множественные коэффициенты корреляции) и соответствующих графиках.
|
|
|
Регрессионный анализ обеспечивает исследование зависимости исследуемой переменной от различных факторов и отображение их взаимосвязи в форме регрессионной модели и соответствующих графиков. В качестве моделей могут быть использованы регрессии: линейная множественная, пошаговая, гребневая, парная.
Компонентный анализ обеспечивает определение структурной зависимости между случайными переменными, сжатие описания до малого объема, несущего почти всю информацию, содержащуюся в исходных данных.
Факторный анализ выступает более общим методом преобразования исходных переменных по сравнению с компонентным анализом, при этом структура отчета может включать в себя до 5 таблиц - собственные значения, прямая и повернутая матрицы факторов, оценки общности, значения главных факторов.
Кластерный анализ обеспечивает разбиение наблюдений на однородные группы (кластеры). Результаты статистической классификации определяются выбором количества и состава переменных, а также алгоритма и метрики классификации. Структура отчета включает в себя таблицу результатов кластеризации и график кластеров.
Частотный анализ обеспечивает исследование временных рядов со строго периодическими или более или менее регулярными колебаниями. Видом анализа может быть: анализ гармоник, спектральный анализ, частотная фильтрация, взаимный спектр (кросс-спектр). Для всех видов анализа, исключая частотную фильтрацию, программа автоматически диагностирует наличие тенденции в исследуемом показателе и при ее обнаружении выдает соответствующее сообщение.
При гармоническом анализе на выходе программы появляется соответствующий протокол с расчетными параметрами, по результатам которого можно судить о значимости гармоник.
При моделях частотной фильтрации производится выделение тренда исходных данных (при высокочастотном фильтре) или его устранение (при низкочастотном фильтре). Протокол частотной фильтрации содержит две таблицы "Выход фильтра", "Передаточная функция" с отражением содержащихся в этих таблицах показателей на графиках.
|
|
|
При спектральном или кросс-спектральном анализе программой выбирается одно из трех окон (прямоугольное, Тьюки, Парзена) и производится построение соответствующих графиков спектра.
Таким образом, эти указанные программные системы позволяют решать очень широкий круг финансово-экономических задач современных предприятий, банков, организаций, помогая их руководству и менеджерам принимать качественные эффективные решения.
Программная система Олимп: Три кита обеспечивает решение внутренних задач управления предприятием, связанных с планированием, учетом и контролем, всесторонне отражая реальное положение дел в финансовой сфере и динамику развития предприятия. Она позволяет: а) планировать сметы расходов и отслеживать их исполнение; б) вести полноценный учет кадров, планировать полезную нагрузку сотрудников и ресурсные возможности предприятия; в) упорядочить назначение сотрудников на проекты и учитывать их фактически отработанное время по различным проектам; г) оценивать эффективность работы сотрудников отделов, департаментов и филиалов; д) вести учет по заключенным договорам; е) знать текущее положение дел по закрытию договоров, выявлять должников и суммы задолженностей.
Таким образом, эти программные системы позволяют решать очень широкий круг задач современных предприятий, помогая их руководству и менеджерам принимать эффективные решения.
Рассмотрим подробнее описание некоторых экономико-математических моделей /242,243,328/.
Методика статистического анализа и прогнозирование данных. При статистическом исследовании финансово-экономических показателей, проводимом с целью анализа характеристик, динамики развития фирм, выявления закономерностей в прошлом и оценки возможности их перенесения на будущее, требуется /242,243,328/:
1. Иметь необходимый для проявления статистических закономерностей объем данных, составляющий для годовых наблюдений - не менее 5 уровней, для сезонных процессов - не менее трех периодов сезонности.
2. Обеспечить методологическую сопоставимость данных.
3. На основе содержательного анализа исследуемого показателя обосновать возможность переноса закономерностей прошлого на выбранный период прогнозирования в будущем.
4. Получить адекватную математическую модель и на ее основе построить точечные и интервальные прогнозы.
Так как основной формой представления статистической информации являются временные ряды наблюдений, то при этом необходимо изучение соотношения между закономерностью и случайностью формирования значений уровней ряда и оценка количественной меры их влияния. Уровни ряда представляют в виде суммы нескольких компонент, отражающих закономерность и случайность развития, в частности, в виде совокупности ряда компонент:
X(t)=f(t)+S(t)+E(t),
где f(t) – тренд, представляющий собой устойчивое изменение показателя в течение длительного времени, являющийся детерминированной компонентой, выражает аналитическую функцию, на которой формируются прогнозные оценки; S(t) - сезонная компонента, характеризующая устойчивые внутригодичные колебания уровней, представляемая квартальными или месячными данными (наличие устойчивых колебаний в суточных или недельных данных может рассматриваться как циклическое явление и отображаться сезонной компонентой); E(t) - остаточная компонента, представляющая собой расхождение между фактическими и расчетными значениями; если построена адекватная модель, то E(t) является близкой к 0, случайной, независимой, подчиняющейся нормальному закону распределения компонентой, иначе модель считается плохой.
Формирование уровней ряда определяется: инерцией тенденции, инерцией взаимосвязи между последовательными уровнями ряда и инерцией взаимосвязи междуисследуемым показателем и показателями-факторами, влияющими на него. При этом выделяются задачи эконометрического анализа и моделирования: а) тенденций, базирующихся на методах компонентного анализа; б) взаимосвязей между последовательными уровнями ряда, базирующихся на адаптивных моделях; в) причинных взаимодействий между исследуемым показателем и показателями-факторами, базирующихся на корреляционно-регрессионных методах.
Алгоритмом статистического компонентного анализа предусматриваются: постановка задачи и подбор исходной информации; предварительный анализ исходных временных рядов и формирование набора моделей прогнозирования; численное оценивание параметров моделей; определение качества, адекватности и точности моделей; выбор одной лучшей или построением обобщенной модели; получение точечного и интервального прогнозов.
На первом шаге алгоритма осуществляется содержательный (логический и экономический) анализ исследуемого процесса; решается вопрос о выборе показателя, характеризующего его наиболее полно; определяются показатели, оказывающие влияние на ход развития; определяются наиболее paзумный период упреждения прогноза, оптимальный горизонт прогнозирования, определяемый индивидуально для каждого показателя с учетом его стабильности и статистическим колебаниям данных (обычно он не превышает 1/3 объема данных).
При предварительном анализе определяется соответствие имеющихся данных требованиям, предъявляемым к ним математическими методами -объективности, сопоставимости, полноты, однородности и устойчивости; строится график динамики и рассчитывают основные динамические характеристики - приросты, темпы роста, темпы прироста, коэффициенты автокорреляции.
Набор моделей формируется на основе интуитивных приемов анализа графика динамики ряда и формализованных статистических процедур исследования приростов уровней. При этом предпочтение отдается наиболее простым, содержательно интерпретируемым моделям, решаемым программным путем на ПЭВМ с проведением вычислений по всем доступным моделям и методам.
Основная идея оценки параметров обычно заключается в максимальном приближении модели к исходным данным. Оценивание параметров моделей кривых роста обычно ведутся методом наименьших квадратов (МНК), параметров адаптивных методов - специальными процедурами многомерной численной оптимизации.
Экстраполяционные методы прогнозирования строят модели кривых роста и адаптивные модели, использующие лишь временный фактор. Кривые роста исходят из равноценности всех данных, отражая общую тенденцию развития, а адаптивные модели - из большей значимости последних наблюдений, лучше отражая динамику изменения, при этом мощным инструментом прогнозирования являются модели Бокса-Дженкинса и ОЛИМП, составляющие основу рабочей базы моделей в программной системе СтатЭксперт. Каждая построенная модель заносится в базу моделей, и если рабочая база заполнена (построено свыше 20 моделей), то вновь построенная модель сравнивается с наихудшей моделью и заменяет ее при лучших характеристиках качества.
Информация, содержащаяся в рабочей базе моделей, является базой для построения прогноза по лучшей модели или формирования обобщенного прогноза. Измерение качества моделей в сочетании с высоким быстродействием ПЭВМ обеспечивает быстрый просмотр множества моделей с выбором из них наилучшей по критериям адекватности и точности, при этом адекватность моделей оценивается по свойствам остаточной компоненты (расхождениям, рассчитанным по модели уровней и фактических наблюдений), а точность модели – по степени близости расчетных данных к фактическим. На основе характеристик точности и адекватности рассчитывается обобщенный показатель качества модели, используемый для определения лучшей модели.
На основе построенной модели рассчитываются точечный (экстраполяционный) и интервальный прогнозы, причем точечный прогноз формируется подстановкой в модель (уравнение тренда) соответствующего значения временного фактора, т.е. t=N+1, N+2,…,N+k, а интервальные прогнозы строятся на основе точечных. Доверительная вероятность прогноза (0-100%) характеризует степень уверенности в попадании прогнозируемой величины в построенный интервал прогнозирования (напомним, что при ее увеличении интервальный прогноз расширяется, поэтому полезность прогноза обратно пропорциональна доверительной вероятности). После получения прогнозных оценок необходимо убедиться в их разумности и непротиворечивости, для чего полученный прогноз следует критически проанализировать с целью выявления возможных противоречий известным фактам и сложившимся представлениям о характере развития на периоде упреждения прогноза (при исследовании конкретных процессов часто применяют ретропрогноз).
При наличии данных о динамике других показателей можнопостроить модель их влияния на основной исследуемый показатель и в случае ее высокого качества получить прогнозные оценки. Для формирования набора факторов, кроме содержательных аспектов, необходимо учитывать формально-статистические аспекты, основывающиеся на коэффициентах корреляции. Следовательно, перед регрессионным анализом необходимо воспользоваться корреляционным анализом, а при необходимости получения прогнозов еще и экстраполяционными моделями.
Дескриптивная статистика. В общем случае исходные данные можно охарактеризовать простейшими средствами описательной статистики, дающими представление об особенностях исследуемого показателя и перспективности использования более глубоких методов анализа. Вычисление основных характеристик данных, в которых Хi - численные значения наблюдений переменной Х, i=1,2,…n проводится на базе ряда известных формул (табл.14.2).
Таблица 14.2. Основные характеристики данных
| № п/п | Показатели | Расчетные формулы |
| Среднее значение | 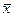 = = 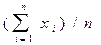
| |
| Среднеквадратическое отклонение (СКО) | s= 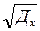 
| |
| Дисперсия | Дх=s2= 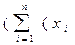 - - 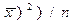
| |
| Несмещенная оценка дисперсии | s2Н= 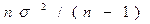
| |
| Среднеквадратическое отклонение для несмещенной оценки дисперсии | sН= 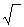 s2Н s2Н
| |
| Среднее линейное отклонение | lo=(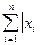 - - 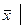 )/n )/n
| |
| Моменты начальные: - 2-го, - 3-го, - 4-го порядка | n2= 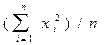 ; n3= ; n3= 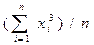 ;
n4= ;
n4= 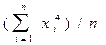
| |
| Моменты центральные: - 3-го, - 4-го порядка | m3 = 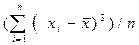 ; m4= ; m4= 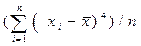
| |
| Коэффициент ассиметрии: его несмещенная оценка - его СКО | АS= 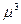 / / 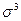 А¢S=[(
А¢S=[(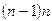 )1/2/(n-2)]´As
SA=[6n (n-1)/ (n-2)(n+1)(n+3)]1/2 )1/2/(n-2)]´As
SA=[6n (n-1)/ (n-2)(n+1)(n+3)]1/2
| |
| Показатель эксцесса: - его несмещенная оценка - его СКО | Е=m4 / s4 Е¢=[(n-1)/(n-2)(n-3)]´[(n+1)E+ 6] SE=[24n(n-1)2/(n-3)(n-2)(n+3)(n+5)]1/2 | |
| Коэффициенты вариации: - по размаху - по среднему линейному отклонению - по его СКО - медиана - мода - минимальное значение ряда - максимальное значение ряда - размах |
R /
lo/
s/
Xn/2
Х
Xmin
Xmax
R=Xmax-Xmin
|
Относительно рядов показателей данной таблицы отметим следующее:
1. Коэффициенты асимметрии и эксцесса позволяют сделать предварительные заключения о близости изучаемого распределения к нормальному. Распределение принято считать нормальным, если выполняются условия:As£3SA; E£5SE.
2. Для медианы - исходный ряд считается отсортированным.
3. Мода – это значение Х, наблюдаемое наиболее часто.
Для изучения пространственных данных используют технологию их агрегирования с построением интервального ряда. Ширина интервала для группировки (Н) определяется как H=R/L, L=1+3.322lg(n),
где L - количество интервалов (округляется в большую сторону; n - число членов ряда.
Если установлен соответствующий параметр, то изменяетcя значение Н и пересчитывается L. Каждый j -й интервал (j=1,…,L) xарактеризуется определенной частотой и частостью попадания в негосоответствующих наблюдений заданного ряда.
Таблица интервального ряда распределений содержит разбивку данных на интервалы, числовую характеристику интервала (начало, середину и конец), а также частоту и частость наблюдений.
Обычно характеристиками интервального ряда выступают: среднее значение, дисперсия, среднеквадратическое отклонение, коэффициенты асимметрии и эксцесса, мода и медиана. Их смысл и назначение совпадает с вариационными характеристиками, а формулы вычисления содержат компоненту, учитывающую частоту попадания наблюдений в интервалы.
Сущность метода бутстреп-оценки сводится к дополнению данных фактических наблюдений данными численного моделирования. При этом моделирование производится только в рамках фактических данных, а входными параметрами метода выступают: {Х1,Х2,…Хn} - исходная выборка; k – количество моделируемых выборок (k>50); р – вероятностный уровень оценки математического ожидания (рекомендуемые значения 0.7-0.9). Оценку математического ожидания для малой выборки можно получить по следующему алгоритму:
10. Осуществляется моделирование выборок с использованием датчика натуральных чисел, равномерно распределенных в интервале от 1 до n:
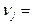 {
{ 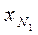 j,
j, 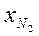 j, …,
j, …, 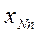 j }.
j }.
20. Для каждой выборки Vj ищется оценка математического ожидания:

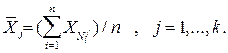
30. Для вариационного ряда математических ожиданий выборки строится интервальный ряд.
40. С хвостов построенного интервального ряда отсекаются интервалы таким образом, чтобы суммарная частость отброшенных интервалов не превосходила (1-р). Оставшиеся интервалы определяют интервальную оценку математического ожидания.
Анализ временных рядов. В этой операции оценивают: характеристику динамики, наличие тренда, однородности данных и автокорреляционных свойств.
Динамику изменения исследуемого показателя мoжно охарактеризовать по отношению к какому-то базисному (обычно nepвому) наблюдению и величиной изменения соседних уровней. В этой связи вычисляются базисные и цепные характеристики. В качестве статистических характеристик временного ряда Yi, i =1,…,N используется ряд величин (табл.14.3).
Таблица 14.3. Основные статистические характеристики временного ряда
| № | Характеристики цепи | Расчетные формулы* |
| 1. | Абсолютный базисный прирост | 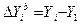
|
| 2. | Абсолютный цепной прирост | 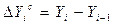
|
| 3. | Базисный коэффициент роста | Кr 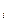 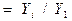
|
| 4. | Цепной коэффициент роста | Кr 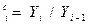
|
| 5. | Базисный коэффициент прироста | Kp r 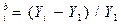
|
| 6. | Цепной коэффициент прироста | Kp r 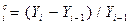
|
| 7. | Темп роста | Tr = Krb ´100% |
| 8. | Темп прироста | Tp r = Tr-100% |
| 9. | Средняя арифметическая | 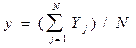
|
| 10. | Средний абсолютный прирост | 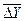 = = 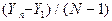
|
| 11. | Средний темп роста | 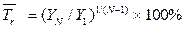
|
| 12. | Средний темп прироста | 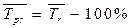
|
* - N – число уровней ряда; Yi - уровни ряда. Использование показателя средней арифметической величины для характеристики процессов, представленных временными рядами с ярко выраженной тенденцией, является некорректным.
Оценка наличия тренда висследуемом временном ряду осуществляется при помощи методов Фостера-Стюарта и средних. При противоречивости их выводов предпочтение отдается первому методу. В методе Фостера-Стюарта гипотеза об отсутствии тренда проверяется с помощью вспомогательных функций:
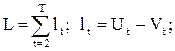
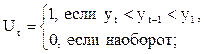
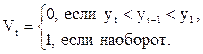
Проверяется гипотеза о том, что L=0. Для проверки строится t-статистика, которая имеет распределение Стьюдента с Т-1 степенями свободы:
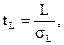 где
где 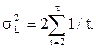 .
.
Гипотеза об отсутствии тенденции отклоняется, если расчетное значение больше табличного на выбранном уровне значимости 0.95.
Проверка однородности данных обычно проводится на основе критерия Ирвина, основанного на сравнении соседних значений ряда и расчете характеристики lt: lt = (Yt – Yt-1)/sy. Полученные значения затем сравниваются с табличными значениями. Однако этот критерий не эффективен для выявления аномальности в динамических рядах, потому что величина sy характеризует отклонения значений показателя от среднего уровня по всей совокупности наблюдений, т.е. он не ловит выбросы внутри ряда наблюдений. Модификация этого метода связана с последовательным расчетом sy не по всей совокупности, а по 3-4 наблюдениям (рассчитанные с такими скользящими значениями sy величины сравниваются с критическими значениями l* для n=3). Не проверяются временные ряды с периодом сезонности более единицы, а также уровни на концах периода наблюдений.
Оценка автокорреляционных свойств сводится к исследованию автокорреляционной и частной автокорреляционной функции исходного и разностного рядов.
Автокорреляционная функция представляет собой совокупность коэффициентов автокорреляции, вычисленных для исследуемого показателя или разностного ряда, используемую для оценки тесноты взаимосвязи уровней ряда и подбора соответствующих авторегрессионых моделей. Анализ автокорреляции выполняется с помощью графика автокорреляции; коэффициенты автокорреляции для его построения вычисляются как
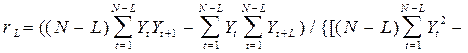
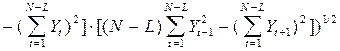 , t=
, t= 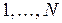 , L=0,1,2,….
, L=0,1,2,….
Частная автокорреляционная функция вычисляется как
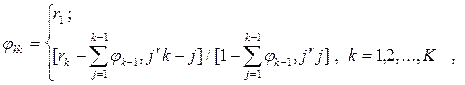
где К - максимальная задержка (лаг) функции (обычно К 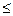 n/4); r – автокорреляционная функция.
n/4); r – автокорреляционная функция.
«Чистые» авторегрессионные процессы имеют плавно затухающую автокореляционную функцию и резко прерывающуюся чистую корреляционную функцию. В этом случае в качестве порядка авторегрессионной модели выбирают лаг, после которого все чистые автокорреляционные функции имеют незначительную величину.
Прогнозирование временных рядов. Для прогнозирования несезонных и сезонных процессов используется различный математический аппарат. Как известно, динамика многих финансово-экономических показателей предприятий и банков имеет устойчивую колебательную составляющую: при исследовании месячных и квартальных данных часто наблюдаются внутригодичные ceзoнные колебания соответственно с периодом 12 и 4; при использовании дневных наблюдений - колебания с недельным (пятидневным) циклом. В этом случае для получения более точных прогнозных оценок необходимо не только правильно отобразить тренд, но его колебательную компоненту. Решение этой задачи базируется на использовании специального класса моделей и методов.
В основе сезонных моделей лежат их несезонные аналоги, которые дополнены средствами отражения сезонных колебаний. Сезонные модели способны отражать как относительно постоянную сезонную волну, так и динамически изменяющуюся в зависимости от тренда. Первая форма относится к классу аддитивных, а вторая – к классу мультипликативных моделей. Большинство моделей имеет обе эти формы. Наиболее широко в финансовой практике используются модели Хольта-Уинтерса, авторегрессии, Бокса-Дженкинса и др.
Кривые роста. Для аналитического выравнивания временных рядов используются функции с одним параметром t, представляющим собой моменты наблюдения (t=1,2,...N). Модели этого класса получили название "кривые роста". Оценка их параметров производится аналогично построению парной регрессии, и для кратко- и среднесрочного прогнозирования они являются надежным инструментом.
Метод наименьших квадратов – основа численной оценки параметров кривых роста. Оценка качества модели производится по критерию минимума средней квадратической ошибки. Аппроксимация наблюдений сложными функциями дает хорошее приближение к фактическим наблюдениям, но снижает устойчивость модели на периоде прогнозирования. В перспективных программных системах используется до 20 моделей, из них можно выделить функции Гомперца и логистической кривой, не сводимые к модели линейной регрессии, в которых поиск параметров ведется методом многомерной численной оптимизации.
Экстраполяция траектории модели за период наблюдения t=N+1,N+2 … является основой прогнозирования трендовых моделей. Интервальный прогноз в каждой прогнозной точке определяется по соотношениям регрессионного анализа с задаваемой пользователем доверительной вероятностью.
Адаптивные методы прогнозирования. При краткосрочном прогнозировании обычно более важна динамика развития исследуемого показателя на конце периода наблюдений, а не тенденция его развития, сложившаяся в среднем на всем периоде предыстории. Свойство динамики развития финансово-экономических процессов часто преобладает над свойством инерционности, поэтому более эффективными являются адаптивные методы, учитывающие информационную неравнозначность данных и имеющие механизм автоматической настройки на изменение исследуемого показателя.
Инструментом прогноза является модель, первоначальная оценка параметров которой производится по нескольким первым наблюдениям. На ее основе делается прогноз, который сравнивается с фактическими наблюдениями. Далее модель корректируется в соответствии с величиной ошибки прогноза и вновь используется для прогнозирования следующего уровня, вплоть до исчерпания всех моментов наблюдений. Таким образом, модель постоянно приспосабливается к новой информации и к концу периода наблюдения отображает тенденцию, сложившуюся на текущий момент. Прогноз получается как экстраполяция последней тенденции. В различных методах прогнозирования процесс настройки (адаптации) модели осуществляется по-разному. Базовыми адаптивными моделями считаются модели Брауна и Хольта, относящиеся к схеме скользящего среднего, и модель авторегрессии, относящаяся к схеме авторегрессии. Многочисленные адаптивные методы базируются на этих моделях, различаясь между собой способом числовой оценки параметров, определения параметров адаптации и компоновкой.
Более подробный их анализ дан в /242,243,328/. Например, по схеме скользящего среднего оценкой текущего уровня является взвешенное среднее всех предшествующих уровней, причем веса при наблюдениях убывают по мере удаления от последнего (текущего) уровня, т.е. информационная ценность наблюдений тем больше, чем ближе они к концу периода наблюдений. По схеме авторегрессии, оценкой текущего уровня является взвешенная сумма "р" предшествующих уровней (их количество называется порядком модели). Информационная ценность наблюдений определяется не их близостью к моделируемому уровню, а теснотой связи между ними. Обе эти схемы имеют механизм отображения колебательного (сезонного или циклического) развития исследуемого процесса.
Модель Брауна.. Если имеется временной ряд наблюдений X(t), T = 1,...,п, то прогноз в момент времени t на t шагов вперед можно получить по формуле
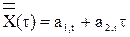 ,
,
где a1,t и a2,t - текущие оценки коэффициентов адаптивного полинома
В модели Брауна модификация (адаптация) коэффициентов линейной модели осуществляется следующим образом:
a 1,t = a 1,t-1 + a 2,t-1 + (1 - b2)et; a 2,t = a 2,t-1 + (1 - b)2et,
где b - коэффициент дисконтирования данных; et – ошибка прогнозирования, 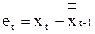 .
.
Начальные значения параметров модели можно определить по методу наименьших квадратов на основе нескольких первых наблюдений. Оптимальное значение параметра дисконтирования находится в переделах [0;1], определяясь методом численной оптимизации и являясь постоянным для всего периода наблюдений. Посредством оператора В можно cдвигать всю последовательность на один шаг назад: Вх(t)=х(t-1). Применение оператора В к наблюдениям и к коэффициентам адаптивного полинома позволяет выразить модель Брауна в виде
(1 - b)2xt = (1 – 2Bb + B2b2)et.
Тогда модель Брауна можно трактовать как модель авторегрессии -
скользящего среднего АРСС(р, d, q) с р==0, d=2, q=2 и коэффициентами скользящего среднего -2b и b2.
Модель Хольта. В модели Хольта коэффициенты линейной модели
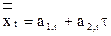
модифицируются по следующим соотношениям:
a 1,t = a 1,t-1 + a 2,t-1 + a1et;
a 2,t = a 2,t-1 + a2et.
Начальные значения параметров модели находятся по методу наименьших квадратов на основе нескольких первых наблюдений. Оптимальные значения параметров сглаживания a1 и a2 находятся в пределах [0,1], определяясь методом многомерной численной оптимизации и являясь постоянными для всего периода наблюдений.
Аналогично модели Брауна, модель Хoльта в терминах АРСС-моделей представима в виде:
(1 – B)2 xt = (1 – (2 – (a1 + a1a2)B + (1 – a1)B2)et.
Формулировка адаптивных моделей в терминах линейных параметрических моделей авторегрессии - скользящего среднего позволяет трактовать их как подмножество класса линейных параметрических моделей. Таким образом, устанавливается соответствие между двумя, вообще говоря, различными подходами к моделированию временных рядов.
Модель Хольта-Уинтерса. Сезонные процессы можно отображать моделью в аддитивной и мультипликативной форме. Прогноз на t шагов вперед для аддитивной формы строится по формуле
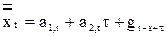 ,
,
а модификация параметров производится по соотношениям:
a 1,t = a1(xt – gt-s) + (1 - a1)(a 1,t-1 + a 2,t-1); a 2,t = a3(a 1,t – a 1,t-1) + (1 - a3)a 2,t-1,
где g - фактор сезонности; s - период сезонного цикла.
Мультипликативная модель аналогична аддитивной модели с той лишь разницей, что расчетные по линейной модели значения корректируются путем их умножения на сезонные коэффициенты Прогноз на t шагов строится по формуле
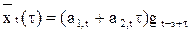 ,
,
а модификация параметров производится по соотношениям:
a 1,t = a1(xt /g t-s) + (1 - a1)(a 1,t-1 + a 2,t-1);
a 2,t = a3(a 1,t – a 1,t-1) + (1 - a3) a 2,t-1;
gt = a2xt / a 1,t + (1 - a2)g t-s,
где g - фактор сезонности; s - период сезонного цикла
Для более точного отображения процессов с сильной сезонностью может использоваться специальная процедура корректировки параметра сглаживания уровня процесса.
Для несезонных временных рядов вычислительные формулы упрощаются за счет исключения сезонной компоненты При построении модели производится численная оптимизация параметров адаптации в пределах [0,1].
Метод эволюции для двух- и трехпараметрических моделей. Для обеспечения адаптации параметра сглаживания однопараметрической модели к изменениям в динамике ряда можно, используя три различных параметра» называемых соответственно "нормальным" (а), "низким" (а-h) и "высоким" (а+h), получать не одну, а три оценки следующего уровня ряда. При этом оценка» полученная при нормальном значении параметра, считается прогнозом, а остальные две оценки являются контрольными величинами.
После получения нового фактического уровня ряда определяют значение параметра, давшего наименьшую абсолютную или сглаженную ошибку, и, следовательно, являющегося лучшим для предыдущего и текущего шагов. Предполагается, что оно будет лучшим и на текущем шаге прогнозирования. Данное значение считается нормальным, и уже от него строятся новые "низкое" и "высокое" значения (а±h), которые должны находиться в некотором интервале (h, 1-h).
Таким образом, значение параметра сглаживания, выбранное первоначально произвольно, постоянно изменяется в направлении компенсации и устранения постоянно возникающих ошибок прогнозирования.
Модель Уинтерса можно развить реализацией схемы всевозможных проб при различных сочетаниях значений параметров сглаживания, задаваемых из расчета по три значения на каждый параметр. При k управляемых параметрах в каждый момент времени вычисляется (2k +1) оценок будущего наблюдения и, одна из них (точка с номером 1), соответствующая центральной точке, т.е. точке, координаты которой соответствуют "нормальным" значениям параметра сглаживания, считается прогнозом. На основе анализа точности пробных оценок можно принять решение о переносе центральной точки в точку плана, давшую минимальную ошибку.
Метод адаптивной фильтрации (МАФ). Оценка уровня динамического ряда хt = (t = 1, …, N) в виде МАФ осуществляется на основе регрессионной AР(p)-модели, не имеющей уровня Ф0. Параметры адаптивного фильтра на j-й итерации обновляется следующим образом:
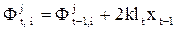 ,
,
где 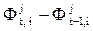 - соответственно векторы старых и новых весов; lt -текущая ошибка прогнозирования (
- соответственно векторы старых и новых весов; lt -текущая ошибка прогнозирования (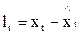 ); k- константа обучения, определяющая скорость адаптации параметров модели, k³0.
); k- константа обучения, определяющая скорость адаптации параметров модели, k³0.
Существуют несколько модификаций МАФ, но алгоритм поучения прогноза модели практически одинаков. На первой итерации (j=1) на основе начального набора весов Ф tj,i и первых р уровней ряда вычисляется 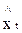 и ошибка lt (t = p + 1). Подставляя величину ошибки прогноза в уравнение корректировки весов, получают новый набор весов Ф t,i для следующего момента временя t = р+2. Далее эта процедура повторяется для следующих р- наборов xt-i (i = 1; t = p + lN), каждый из которых образован из предыдущего путем исключения первого и добавления одного нового уровня ряда. Если оптимальные веса на j-й итерации не получены, то на следующей (j+1)-йитерации следует вернуться к первому набору уровней ряда x p+l-i (i = I, p), но уже с новыми начальными весами
и ошибка lt (t = p + 1). Подставляя величину ошибки прогноза в уравнение корректировки весов, получают новый набор весов Ф t,i для следующего момента временя t = р+2. Далее эта процедура повторяется для следующих р- наборов xt-i (i = 1; t = p + lN), каждый из которых образован из предыдущего путем исключения первого и добавления одного нового уровня ряда. Если оптимальные веса на j-й итерации не получены, то на следующей (j+1)-йитерации следует вернуться к первому набору уровней ряда x p+l-i (i = I, p), но уже с новыми начальными весами 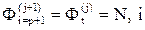 .
.
Рассмотренную общую схему построения адаптивного фильтра можно использовать как для исходного временного ряда, так и для производных разностных рядов tt = Ñdxt (d = 0, 1, 2), причем в последнем случае эффективность метода существенно повышается. Проблема идентификации модели в МАФ решается автоматически (хотя и не всегда удачно): для сезонных рядов порядок модели р равен периоду сезонности, а для несезонных процессов - временному лагу, давшему максимальный положительный коэффициент автокорреляции.
Момент окончания процедуры корректировки параметров можно определить путем априорного задания максимально допустимого числа итераций (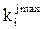 ) или путем сравнения каких-либо статистик, вычисленных на двух последовательных итерациях Корректировку весов можно заканчивать, если среднеквадратическая ошибка перестает заметно убывать.
) или путем сравнения каких-либо статистик, вычисленных на двух последовательных итерациях Корректировку весов можно заканчивать, если среднеквадратическая ошибка перестает заметно убывать.
Важным этапом реализации МАФ является определение оптимальной величины константы обучения Копт. Результаты ряда исследований показывают, что Копт лежит в пределах 0 £ k £ 1/р. Для практической работы этот интервал очень широк. Поэтому более точное значение константы обычно определяется методом проб или направленного поиска.
Метод гармонических весов. В данном методе, разработанном Хельвигом, идея дисконтирования данных реализована иначе, чем в других адаптивных методах Параметр прироста линейной модели, используемой для прогнозирования, находится путем взвешивания на основе гармонических весов приростов сглаженного ряда. Сглаживание осуществляется линейной функцией для каждого из (Н+К-1) перекрывающихся сегментов одинаковой длины К:
xi(t) = ai + bit (i = 1, 2, …, N – K + 1).
Коэффициенты всех моделей скользящего тренда определяются по формулам:
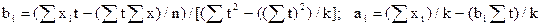 .
.
Здесь суммирование по t производится от i до (i+k-1). После получения всех (N-К+1) оценок параметров определяются сглаженные значения ряда:
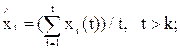
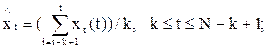
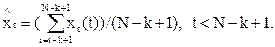
Предполагается, что приросты сглаженного ряда являются случайной величиной, у которой оценкой математического ожидания является средний уровень Pt с дисперсией Sр. В этом случае средний прирост можно использовать для получения прогноза на ряд (1, 2 и более) шагов вперед, прибавляя его к уровню процесса» в качестве которого можно принять последний уровень сглаженного ряда.
Учитывая информационную неравноценность данных, Хельвиг предложил использовать гармоническую среднюю P вида
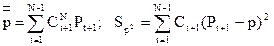 ,
,
где Pt+1 — приросты сглаженного ряда 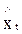 , Ct+1 — веса приростов. Таким образом, все веса приростов положительны и в сумме дают единицу. Прогноз на t шагов вперед получается по формуле
, Ct+1 — веса приростов. Таким образом, все веса приростов положительны и в сумме дают единицу. Прогноз на t шагов вперед получается по формуле
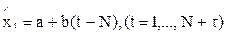 ,
,
где