 2017-12-14
2017-12-14 1489
1489Функцию, значение которой при каждом значении независимой переменной является случайной величиной, называют случайной функцией. Случайные функции, для которых независимой переменной является время t называют случайными процессами или стохастическими процессами.
Если, например, проведено n отдельных опытов, то в результате случайный процесс X(t) может принять n различных неслучайных (регулярных) функций времени xi(t) где i = 1, 2, …..n
Всякая функция xi(t) которой может оказатся равным случайный процесс X(t) в результате опыта, называется реализацией случайного процесса (или возможным значением случайного процесса). Сказать заранее, по какой из реализаций пойдет процесс, невозможно.
Для любого фиксированного момента времени, например t = t1 реализация случайного процесса xi(t1) представляет собой конкретную величину, значение же случайной функции X(t1) является случайной величиной, называемой сечением случайного процесса в момент времени t1. Поэтому нельзя утверждать, что случайный процесс в данный момент времени имеет такое то детерминированное значение, можно говорить лишь о вероятности того, что в данный момент времени значение случайного процесса как случайной величины будет находиться в определенных пределах.
|
|
|
Статистические методы изучают не каждую из реализаций xi(t) образующих множество X(t), а свойства всего множества в целом с помощью усреднения свойств входящих в него реализаций (рис. 19.2.). Поэтому при исследовании о поведении объекта судят не по отношению к какому-либо определенному воздействию, представляющему заданную функцию времени, а по отношению к целой совокупности воздействий.
Как известно, статистические свойства случайной величины х определяют по ее функции распределения(интегральному закону распределения) F(x) или плотности вероятности (дифференциальному закону распределения) ω (x).
Случайные величины могут иметь различные законы распределения: равномерный, нормальный, экспоненциальный и др. Во многих задачах очень часто приходится иметь дело с нормальным законом распределения (или законом Гаусса), который получается, если случайная величина определяется суммарным эффектом от действия большого числа различных независимых факторов.
Напомним, что случайная величина х при нормальном законе распределения полностью определяется математическим ожиданием (средним значением) mx и средним квадратическим отклонением σx.
Аналитическое выражение функции распределения в этом случае
 (19.5)
(19.5)
Следует обратить внимание на то, что, хотя переменная интегрирования и верхний предел интегрирования обозначены одним символом, это не отражается на конечных результатах и не должно привести к недоразумениям.
|
|
|
Аналитическое выражение плотности вероятности для нормального закона распределения
 (19.6)
(19.6)
Типичные графики функций распределения F(x) и плотности вероятности ω(x) для различных значений σx приведены на (рис. 19.3 а, б). Изменение среднего значения mx вызывает только смещение кривых F(x) и ω(x) вдоль оси абсцисс без изменения их формы, а изменение величины σx вызывает изменение масштаба вдоль обеих координатных осей, причем площадь, ограничиваемая кривой ω(x) и осью абсцисс, всегда остается конечной и равной единице, т. е.
 (19.7)
(19.7)
поскольку F(∞) = 1, F(-∞) = 0

Рис. 19.3
При конечных пределах интегрирования величина интеграла будет меньше единицы. Уже при пределах интегрирования от (mx - 3σx) до (mx + 3σx) величина интеграла равна 0,997. Так как вероятность того, что х лежит между (mx - 3σx) и (mx + 3σx) равна 0,997, то величину 3σx часто используют в практических расчетах в качестве верхней границы отклонения от среднего значения.
Для случайного процесса также вводят понятие функции распределения F(x,t) и плотности вероятности ω(x,t), которые зависят от фиксированного момента времени наблюдения t и от некоторого выбранного уровня х, т. е. являются функциями двух переменных: x и t.
Рассмотрим случайную величину X(t1) т. е. сечение случайного процесса в момент времени t1. Одномерной функцией распределения (функцией распределения первого порядка) случайного процесса X(t) называют вероятность того, что текущее значение случайного процесса X(t1) в момент времени t1 не превышает некоторого заданного уровня (числа) х1 т. е.
 (19.8)
(19.8)
Если функция F1(x1,t1) имеет частную производную по x1, т. е.
 (19.9)
(19.9)
то функцию ω1(x1,t1) называют одномерной плотностью вероятности (плотностью вероятности первого порядка) случайного процесса. Величина
 (19.10)
(19.10)
представляет собой вероятность того, что X(t) находится в момент времени t = t1 в интервале от x1 до x1 + dx1. В каждые отдельные моменты времени t1,t2,…,tn случайные величины (сечения случайного процесса) X(t1), X(t2),….., X(tn) будут иметь свои, в общем случае разные, одномерные функции распределения F1(x1,t1), F1(x2,t2),….., F1(xn,tn) и плотности вероятности ω1(x1,t1), ω1(x2,t2),……, ω1(xn,tn).
Функции F1(x,t) и ω1(x,t) являются простейшими статистическими характеристиками случайного процесса. Они характеризуют случайный процесс изолированно в отдельных его сечениях, не раскрывая взаимной связи между сечениями случайного процесса, т. е. между возможными значениями случайного процесса в различные моменты времени.
Знания этих функций еще недостаточно для описания случайного процесса в общем случае. Необходимо охарактеризовать также взаимную связь случайных величин в различные произвольно взятые моменты времени.
Рассмотрим теперь случайные величины X(t1) и X(t2), относящиеся к двум разным моментам времени t1 и t2, наблюдения случайного процесса.
Вероятность того, что X(t) будет не больше x1 при t = t1 и не больше x2 при t = t2, т. е.
 (19.11)
(19.11)
называют двумерной функцией распределения (функцией распределения второго порядка). Если функция F2(x1,t1;x2,t2) имеет частные производные по x1 и х2 т. е.
 (19.12)
(19.12)
то функцию ω2(x1,t1;x2,t2) называют двумерной плотностью вероятности (плотностью вероятности второго порядка). Величина
 (19.13)
(19.13)
равна вероятности того, что X(t) при t = t1 убудет находиться в интервале от x1 до x1 + dx1, а при t = t2 в интервале от x2 до x2 + dx2
Аналогично можно ввести понятие от n-мерной функции распределения:
 (19.14)
(19.14)
Если функция Fn имеет частные производные по всем аргументам x1,x2,..,xn, т. е.
 (19.15)
(19.15)
то функцию Ωn называют n-мерной плотностью вероятности. Чем выше порядок n тем полнее описываются статистические свойства случайного процесса. Зная n-мерную функцию распределения, можно найти по ней одномерную, двумерную и другие вплоть до (n-1) функции распределения более низкого порядка. Однако многомерные законы распределения случайных процессов являются сравнительно громоздкими характеристиками и с ними крайне трудно оперировать на практике. Поэтому при изучении случайных процессов часто ограничиваются случаями, когда для описания случайного процесса достаточно знать только его одномерный или двумерный закон распределения.
|
|
|
Примером случайного процесса, который полностью характеризуется одномерной плотностью вероятности, является так называемый чистый случайный процесс, или белый шум. Значения X(t) в этом процессе, взятые в разные моменты времени t, совершенно независимы друг от друга, как бы близко ни были выбраны эти моменты времени. Это означает, что кривая белого шума содержит всплески, затухающие за бесконечно малые промежутки времени. Так как значения X(t) например, в момент времени t1 и t2 независимы, то вероятность совпадения событий, заключающихся в нахождении X(t) между x1 и x1 + dx1 в момент времени t1 и между x2 и x2 + dx2 в момент t2 равна произведению вероятностей каждого из этих событий, поэтому
 (19.16)
(19.16)
и вообще для белого шума
 (19.17)
(19.17)
т. e. все плотности вероятности белого шума определяются из одномерной плотности вероятности.
Для случайных процессов общего вида, если известно, какие значения приняла величина X(tk) в момент времени tk тем самым имеем некоторую информацию относительно X(tm), где k < m так как величины X(tk) и X(tm), вообще говоря, зависимы. Если кроме X(tk) известна X(tl), где l < k, то информация о X(tm) еще более увеличивается. Таким образом, увеличение наших знаний о поведении процесса до момента tk приводит к тому, что увеличивается информация о X(tm).
Однако существует особый класс случайных процессов, впервые исследованных известным математиком А. А. Марковым и называемых марковскими случайными процессами, для которых знание значения процесса в момент tk уже содержит в себе всю информацию о будущем ходе процесса, какую только можно извлечь из поведения процесса до этого момента. В случае марковского случайного процесса для определения вероятностных характеристик процесса в момент времени tm достаточно знать вероятностные характеристики для любого одного предшествующего момента времени tk. Знание вероятностных характеристик процесса для других предшествующих значений времени, например ti не прибавляет информации, необходимой для нахождения X(tm).
|
|
|
Для марковского процесса справедливо следующее соотношение:
 (19.18)
(19.18)
т. е. все плотности вероятности марковского процесса определяются из двумерной плотности вероятности. Другими словами, марковские случайные процессы полностью характеризуются двумерной плотностью вероятности.
Понятие о функции распределения и плотности вероятности случайного процесса обычно используют при теоретических построениях и определениях. В практике исследования прочности сооружений широкое распространение получили сравнительно более простые, хотя и менее полные характеристики случайных процессов, аналогичные числовым характеристикам случайных величин. Примерами таких характеристик служат рассматриваемые ниже математическое ожидание, дисперсия, среднее значение квадрата случайного процесса, корреляционная функция, спектральная плотность и другие.
Математическим ожиданием (средним значением) mx(t) случайного процесса X(t) называют величину
 (19.19)
(19.19)
где ω1(x,t) — одномерная плотность вероятности случайного процесса X(t).
Математическое ожидание случайного процесса X(t) представляет собой некоторую неслучайную (регулярную) функцию времени mx(t), около которой группируются и относительно которой колеблются все реализации данного случайного процесса (рис. 19.4).
Математическое ожидание случайного процесса в каждый фиксированный момент времени tk равно математическому ожиданию соответствующего сечения случайного процесса X(tk) и представляет собой операцию вероятностного усреднения случайной величины X(tk), при котором каждое возможное значение для случайной величины х принимается с весом, равным элементу вероятности ω1(x,tk)dx. Математическое ожидание называют средним значением, случайного процесса по множеству (средним по ансамблю, статистическим средним), поскольку оно представляет собой вероятностно

Рис. 19.4
усредненное значение бесконечного множества реализации случайного процесса.
Средним значением квадрата случайного процесса называют величину
 (19.20)
(19.20)
Часто вводят в рассмотрение так называемый центрированный случайный процесс Ẋ(t) под которым понимают отклонение случайного процесса X(t) от его среднего значения mx(t) или
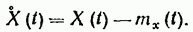 (19.21)
(19.21)
Тогда случайный процесс X(t) можно рассматривать как сумму двух составляющих: регулярной составляющей, равной математическому ожиданию mx(t) и центрированной случайной составляющей Ẋ(t) т. е.
 (19.22)
(19.22)
Очевидно, что математическое ожидание центрированного случайного процесса равно нулю:
 (19.23)
(19.23)
Для того чтобы каким-то образом учесть степень разбросанности реализаций случайного процесса относительно его среднего значения, вводят понятие дисперсии случайного процесса, которая равна математическому ожиданию квадрата центрированного случайного процесса:
 (19.24)
(19.24)
Дисперсия случайного процесса является неслучайной (регулярной) функцией времени Dx(t) значение которой в каждый момент времени tk равно дисперсии соответствующего сечения X(tk) случайного процесса.
Легко показать, что математическое ожидание mx(t), дисперсия Dx(t) и среднее значение квадрата случайного процесса, имеющие размерность квадрата случайной величины, связаны соотношением
 (19.25)
(19.25)
Откуда видно, что среднее значение квадрата случайного процесса в определенной мере учитывает и среднее значение случайного процесса, и степень рассеяния его реализаций относительно этого среднего значения.
На практике часто бывает удобно пользоваться статистическими характеристиками случайного процесса, имеющими ту же размерность, что и сама случайная величина. К таким характеристикам относят:
среднее квадратическое значение случайного процесса
 (19.26)
(19.26)
равное арифметическому значению квадратного корня из среднего значения квадрата случайного процесса;
среднее квадратическое отклонение случайного процесса
 (19.27)
(19.27)
равное арифметическому значению квадратного корня из дисперсии случайного процесса.
Из вышесказанного видно, что среднее квадратическое значение хс.к(t) и среднее квадратическое отклонение σx(t) случайного процесса в общем случае не совпадают. Последняя характеристика используется только для центрированных случайных процессов.
В заключение заметим, что хотя ни математическое ожидание, ни дисперсия случайного процесса ни в какой мере не характеризуют степень статистической зависимости между сечениями случайного процесса в различные моменты времени, знания этих характеристик часто достаточно для решения многих задач.








